想象一下教小孩认识动物的过程。你给他看一张猫的照片,他说是"狗",你告诉他错了,这是"猫"。经过成千上万次这样的纠正,他最终学会了正确识别各种动物。神经网络的训练过程本质上就是这样一个不断试错、不断改进的过程。
在深度学习中,这个"纠错"过程是通过数学方法自动完成的。网络会根据每次预测的错误程度,自动调整内部的参数(权重和偏置),使下次预测更加准确。
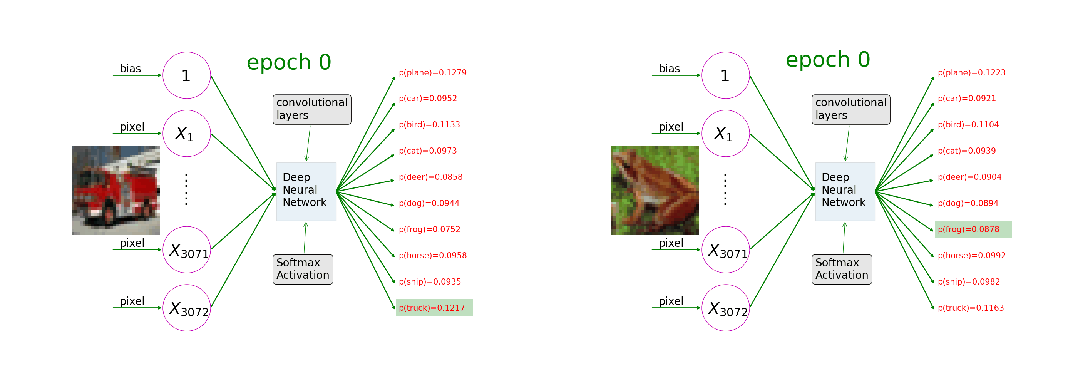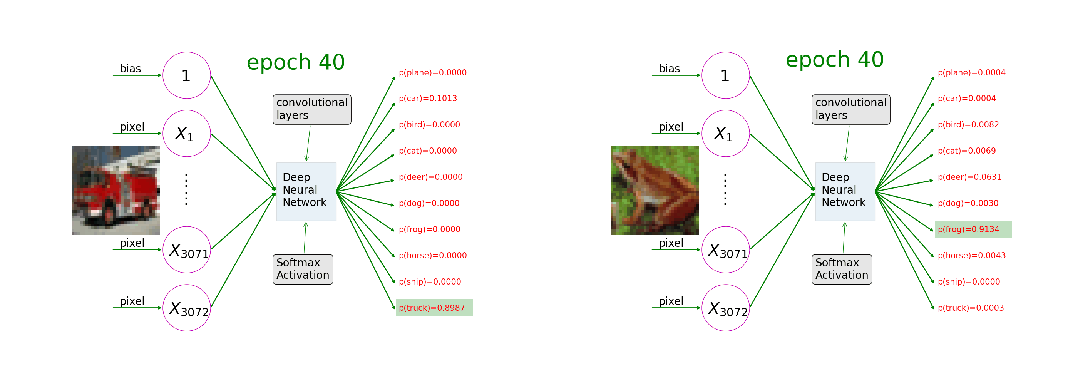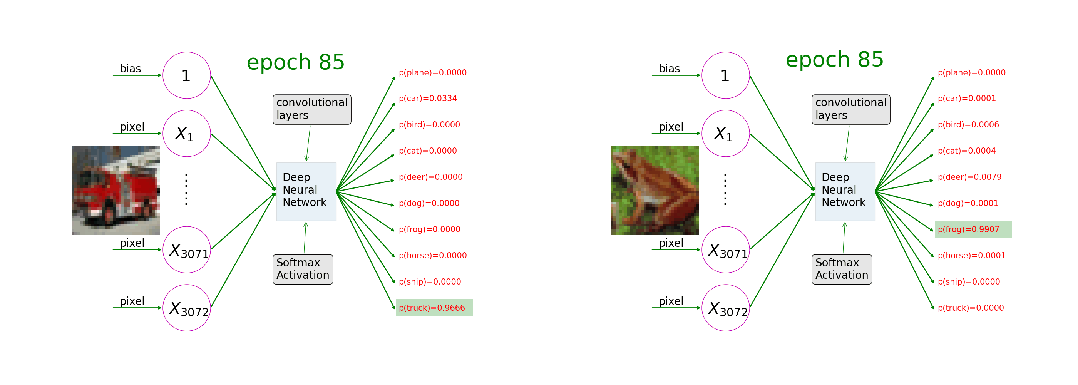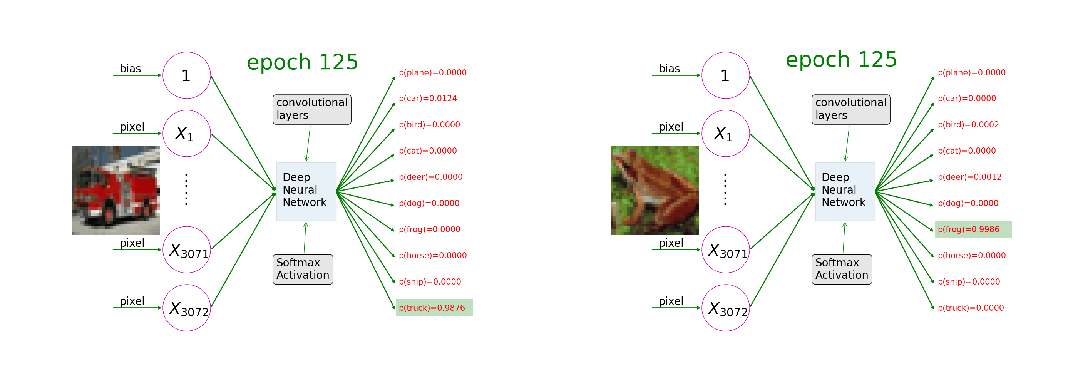
训练过程就像一个精密设计的学习循环,每一轮都包含"前向传播-损失计算-反向传播-权重更新"四个不可缺少的步骤。输入数据 → 第1层 → 第2层 → ... → 输出层 → 预测结果
这一步就像学生答题的过程。输入数据(比如一张图片)进入神经网络,就像题目交给学生一样。数据会依次经过网络的每一层,每一层都会对数据进行一定的处理和变换。这个过程完全是自动的,就像水流从高处流向低处一样自然。每一层都使用当前的权重参数来处理接收到的信息,然后传递给下一层。预测结果 vs 真实标签 → 损失函数 → 损失值(错误程度)
当网络给出预测后,我们需要知道这个预测有多准确。这就像老师批改试卷一样,需要将学生的答案与标准答案进行对比。损失函数就是这个"评分标准",它会计算出一个数值来表示预测的错误程度。常用的损失函数包括:均方误差主要用于回归任务,计算预测值与真实值差值的平方;交叉熵损失主要用于分类任务,衡量预测概率分布与真实分布的差异。这是训练过程中最核心也最神奇的一步。当我们知道预测有误差后,需要弄清楚网络中的哪些参数需要为这个错误负责,以及它们应该如何调整。这个过程被称为"反向",是因为信息流的方向与前向传播相反——从输出层流向输入层。通过链式法则这一数学工具,我们能够精确计算出每个参数的调整方向和幅度。
有了调整的方向和幅度,现在就要真正更新网络的参数了。这就像学生根据老师的指导来改正错误一样。权重更新的公式看起来简单,但包含了深刻的学习智慧。学习率的选择至关重要,太大可能会错过最优解,就像走路步子太大容易摔倒;太小学习导致过程会非常缓慢,就像蜗牛爬行;刚好才能够稳步而高效地找到最优解。训练循环,重复是学习之母。单次的四步骤只能让网络稍微改进一点点。真正的学习需要成千上万次的重复。就像我们的深度学习,日拱一卒,让大脑不断构建深度学习和大模型的神经网络连接。
对于每个训练周期(epoch): 对于每批数据(batch): 1. 前向传播:让网络做预测 2. 损失计算:评估预测质量 3. 反向传播:计算改进方向 4. 权重更新:实际改进网络 重复处理下一批数据... 完成一个完整的数据遍历重复多个训练周期...
这个重复训练过程中有几个重要概念,给大家敲下黑板,划下重点。
训练周期(Epoch):完整遍历整个训练数据集的次数。通常需要多个周期才能让网络充分学习。
批次(Batch):为了提高效率,我们不是一次处理一个样本,而是一次处理一小批样本。这样既能保证学习的稳定性,又能充分利用计算资源。
损失值(Loss):在训练过程中,我们会密切关注损失值的变化。理想情况下,损失应该随着训练的进行而逐渐降低,这表明网络正在不断进步。
模型推理的本质是什么?运用已学知识
如果说训练是"学习"的过程,那么推理就是"应用"的过程。就像一个经过多年训练的医生,面对新病人时能够快速做出诊断一样,训练好的神经网络能够对新的输入数据快速给出预测结果。
推理阶段最重要的特点是知识已经固化。所有的权重参数都已经确定,不再发生变化。网络就像一个经验丰富的专家,运用已有的知识来解决新问题。
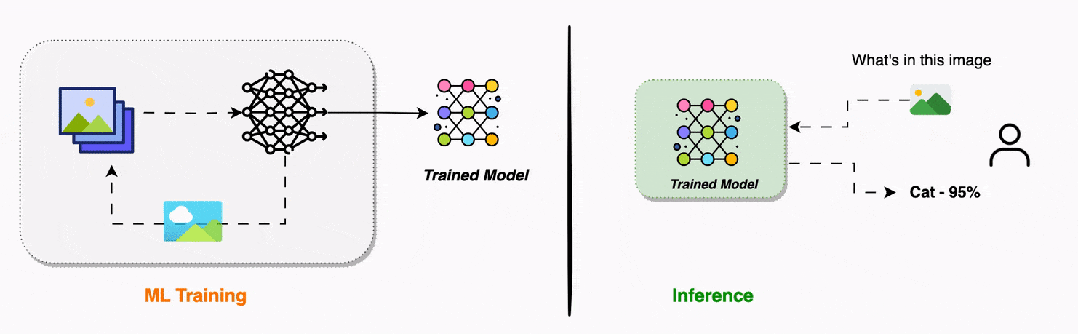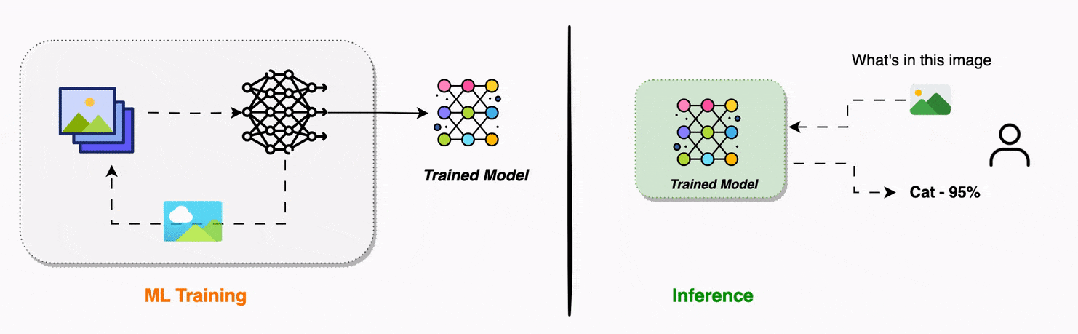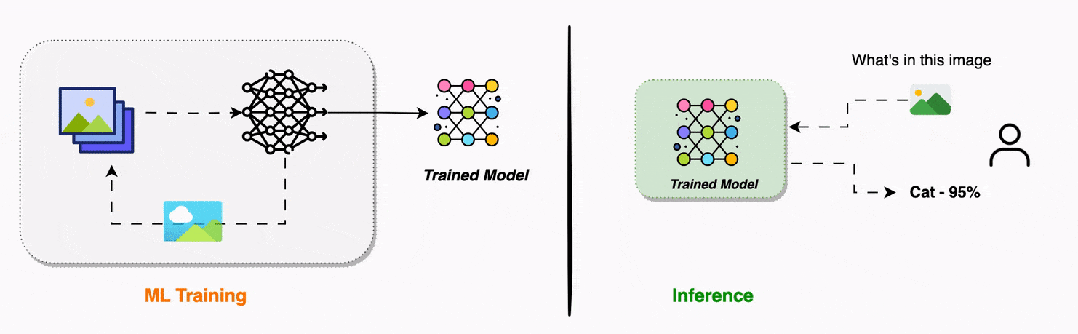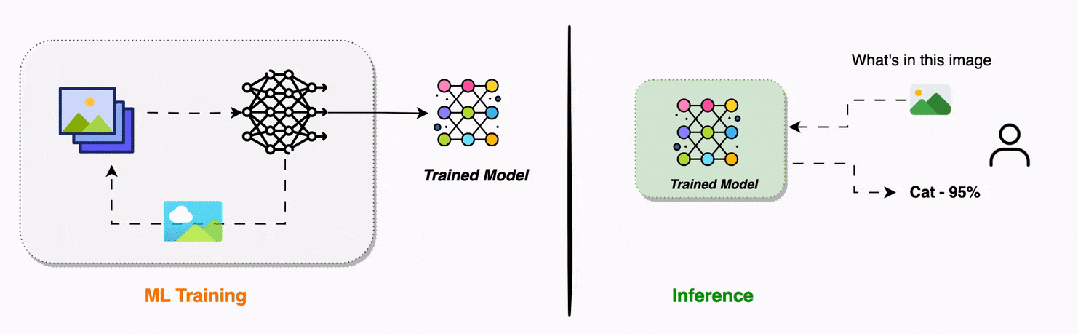
推理过程的三个步骤是什么?与复杂的训练过程相比,推理过程要简单得多,只需要三个步骤:保存的模型文件 → 加载权重参数 → 构建网络结构 → 模型就绪
这一步就像从书架上取下一本已经写好的教科书。训练过程的所有成果——千辛万苦学到的权重参数,都被保存在模型文件中。加载模型时,我们要做如下工作。-
设置模式:将网络切换到"推理模式",关闭训练时的特殊功能
模型加载完成后,就像一台准备就绪的机器,随时可以接受新的输入并产生输出。新输入数据 → 第1层处理 → 第2层处理 → ... → 输出层 → 预测结果
这是推理的核心步骤,与训练时的前向传播几乎完全相同。数据依然是从输入层流向输出层,每一层依然使用相同的数学运算,唯一的区别如下。整个过程就像清澈的溪流,数据平滑地从一端流向另一端,中途经过各种"过滤器"和"处理器",最终变成我们需要的预测结果。原始网络输出 → 格式化处理 → 后处理 → 最终可理解的结果
网络的原始输出通常需要进一步处理,才能变成人类可以理解和使用的结果。
分类任务的处理如下。
- 原始输出可能是一组数字,如 [2.1, -0.8, 1.5]
- 通过softmax函数转换为概率,如 [0.7, 0.1, 0.2]
- 解释为各类别的置信度:"70%可能是猫,10%可能是狗,20%可能是鸟"
回归任务的处理如下。
训练与推理是两种截然不同的工作模式,为了让大家更好地理解这两个阶段的区别,让AI整理了一个表格,将它们进行详细对比。







