第一作者:刘鹏(博士研究生)
通讯作者:刘新会、李立平
通讯单位:北京师范大学
近日,北京师范大学李立平教授和刘新会教授在Nature旗下合作期刊 (Nature Partner Jounal) npj Clean Water发表了题为“Integrating Non-Target Analysis and Machine Learning: A Framework for Contaminant Source Identification”的综述论文。该论文提出了一套融合非靶向分析(NTA)和机器学习(ML)的系统框架,涵盖从样品采集、数据获取,到智能分析与结果验证的完整闭环。该框架有望借助机器学习,将海量复杂的化学信号转化为可操作的环境管理指标,从而为污染溯源和环境决策提供强有力的技术支撑。
在环境监测中,传统的靶向分析能够精准检测已知污染物,但在面对不断涌现的新污染物及其转化产物时,往往显得力不从心。非靶向分析依托高分辨质谱技术,能够一次性捕获数千种化学物质信号,大幅拓展检测范围。然而,非靶向分析的优势也伴随着挑战——庞大而复杂的数据矩阵中,真正与污染溯源相关的特征往往只是“冰山一角”,如何高效而准确地识别这些关键信息,成为科学家们必须解决的核心问题。
机器学习为此提供了新思路。它能够在高维复杂数据中识别模式与规律,并提炼出可用于污染溯源的“化学指纹”
。但目前,机器学习与非靶向分析相结合的最大的难点在于缺乏一个将原始质谱数据转化为环境决策依据的系统化框架。现有研究往往重视样品预处理和数据采集,却忽视了面向机器学习的数据处理与分析流程,因而难以有效提炼与污染源相关的化学指纹或指标(图 1)。尽管多种机器学习模型已应用于污染溯源,但尚无系统性综述指导研究者如何在不同情境下选择最合适的机器学习算法。同时,模型的“黑箱”问题仍然突出,复杂模型虽具备较高的准确率,却难以提供符合化学逻辑的解释。验证环节也多依赖实验室条件,缺乏真实环境下的检验,进一步限制了方法的可靠性与推广性。因此,亟需构建一个兼顾数据处理、模型选择、可解释性提升与多层验证的完整框架,以推动机器学习赋能的非靶向分析真正应用于污染溯源与环境决策。
图 1机器学习协助非靶向分析在污染溯源方面的主要进展和现存不足
图文导读
融合非靶向分析与机器学习的污染溯源框架
作者提出了一个由四阶段构成的污染溯源框:(1)样品处理与信号提取;(2)高分辨质谱数据采集;(3)机器学习处理与模式识别;(4)多层验证与结果应用。本综述的重点集中在第(3)和(4)阶段。第(3)阶段,作者比较了多种降维方法(如 PCA、t-SNE、UMAP)与聚类算法(K-means、HCA、SOM 等),分析了它们在不同数据特征和研究目标下的适用性。同时梳理了常见的监督学习分类模型,包括随机森林(RF)、支持向量机(SVM)、极端梯度提升(XGBoost)等,总结了从数据预处理、特征选择到模型训练与验证的完整操作流程。这部分不仅为方法选择提供了参考,还强调了根据数据特性灵活组合多种方法的重要性。第(4)阶段中,作者提出了“三步式”多层验证策略:首先通过标准物质和对照样验证方法的准确性;其次进行跨数据集验证,以检验模型在不同环境样本中的稳健性;最后开展环境合理性评估,将模型输出与环境过程知识结合,确保结果具备科学解释性与实际应用价值。整个框架既保持科学严谨性,又具备实际可操作性。
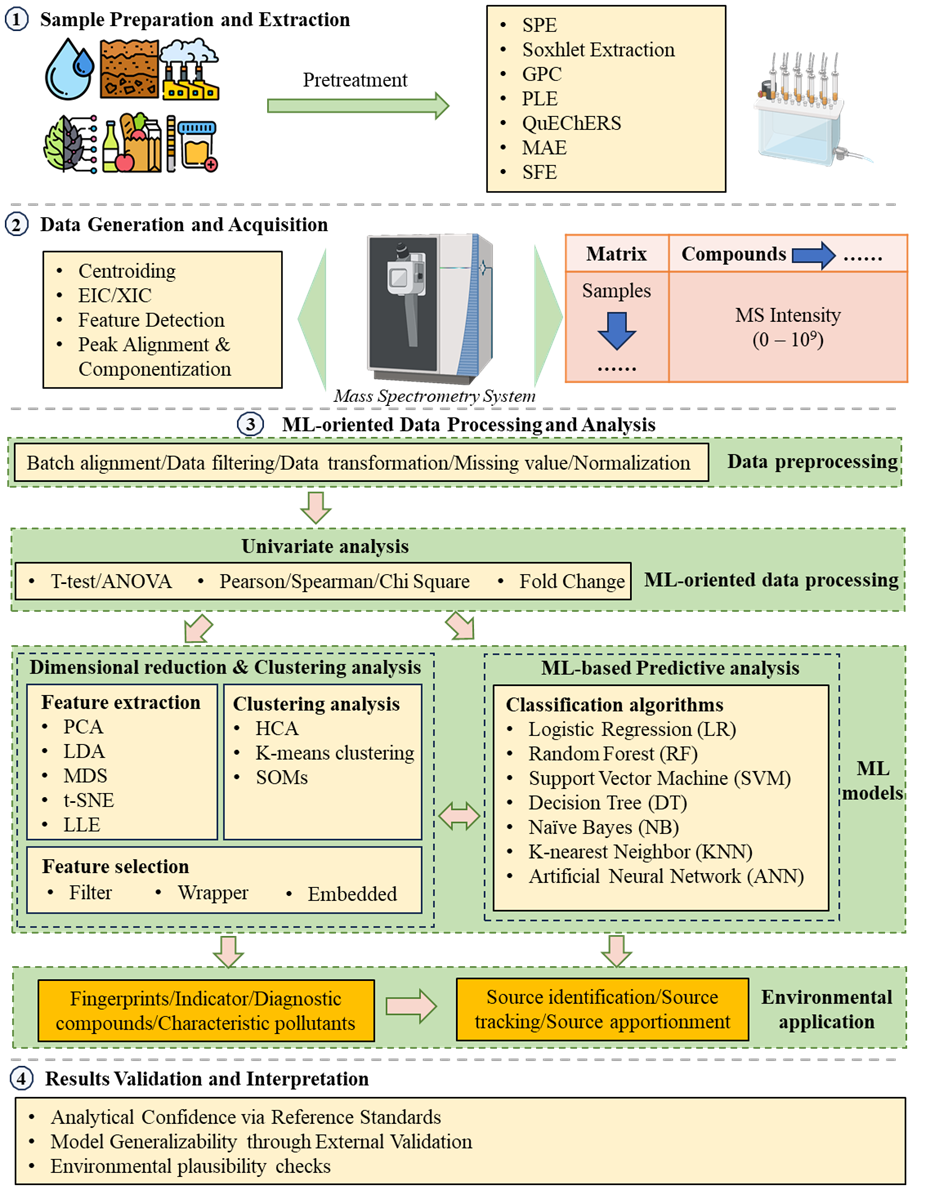
图 2非靶向分析和机器学习集成框架在污染源识别中的工作流程。
实际考量
作者指出,要让该框架真正用于环境监测与污染溯源,还需解决若干实际问题。首先如何平衡样本量与特征维度?NTA 数据通常维度高而样本有限,极易导致模型过拟合。经验上,特征数少于100时,建议样本量保持在50–100 之间。若样本和特征比例失衡,可通过正则化或降维来降低冗余,提升模型稳定性。需要强调的是,实验设计的合理性与变量代表性往往比单纯增加样本数更为关键。其次,无监督方法和有监督模型有何不同?在实际应用中,研究者常先用
PCA或HCA等无监督方法进行初步探索,以识别异常值或观察潜在分组趋势。但这些方法仅能“提示”趋势,缺乏预测能力。相比之下,监督模型(如 RF、SVM)能够对未知数据进行分类,并通过准确率、精确率、召回率等指标严格量化效果。最后,如何选择合适的分类模型?不存在“完美”的最佳算法。一般而言,线性模型适用于二分类,树模型和集成算法(RF、XGBoost、LightGBM)及神经网络更适合多分类任务,并能提供特征重要性解释。若关注关键因子的识别,推荐 RF、SVM 等可结合特征重要性或SHAP 分析的模型;若强调整体分类性能,则应根据准确率、F1 分数等指标筛选最佳模型。
融合非靶向分析与机器学习的污染溯源框架
作者提出了一个由四阶段构成的污染溯源框:(1)样品处理与信号提取;(2)高分辨质谱数据采集;(3)机器学习处理与模式识别;(4)多层验证与结果应用。本综述的重点集中在第(3)和(4)阶段。第(3)阶段,作者比较了多种降维方法(如 PCA、t-SNE、UMAP)与聚类算法(K-means、HCA、SOM 等),分析了它们在不同数据特征和研究目标下的适用性。同时梳理了常见的监督学习分类模型,包括随机森林(RF)、支持向量机(SVM)、极端梯度提升(XGBoost)等,总结了从数据预处理、特征选择到模型训练与验证的完整操作流程。这部分不仅为方法选择提供了参考,还强调了根据数据特性灵活组合多种方法的重要性。第(4)阶段中,作者提出了“三步式”多层验证策略:首先通过标准物质和对照样验证方法的准确性;其次进行跨数据集验证,以检验模型在不同环境样本中的稳健性;最后开展环境合理性评估,将模型输出与环境过程知识结合,确保结果具备科学解释性与实际应用价值。整个框架既保持科学严谨性,又具备实际可操作性。
图 2非靶向分析和机器学习集成框架在污染源识别中的工作流程。
实际考量
作者指出,要让该框架真正用于环境监测与污染溯源,还需解决若干实际问题。首先如何平衡样本量与特征维度?NTA 数据通常维度高而样本有限,极易导致模型过拟合。经验上,特征数少于100时,建议样本量保持在50–100 之间。若样本和特征比例失衡,可通过正则化或降维来降低冗余,提升模型稳定性。需要强调的是,实验设计的合理性与变量代表性往往比单纯增加样本数更为关键。其次,无监督方法和有监督模型有何不同?在实际应用中,研究者常先用PCA或HCA等无监督方法进行初步探索,以识别异常值或观察潜在分组趋势。但这些方法仅能“提示”趋势,缺乏预测能力。相比之下,监督模型(如 RF、SVM)能够对未知数据进行分类,并通过准确率、精确率、召回率等指标严格量化效果。最后,如何选择合适的分类模型?不存在“完美”的最佳算法。一般而言,线性模型适用于二分类,树模型和集成算法(RF、XGBoost、LightGBM)及神经网络更适合多分类任务,并能提供特征重要性解释。若关注关键因子的识别,推荐 RF、SVM 等可结合特征重要性或SHAP 分析的模型;若强调整体分类性能,则应根据准确率、F1 分数等指标筛选最佳模型。
作者在结语中指出,非靶向分析与机器学习的结合正在快速推动污染物识别与溯源技术的发展,但在可解释性、流程标准化以及跨平台数据兼容性等方面仍存在挑战。展望未来,随着质谱技术和数据分析方法的持续进步,该框架有望进一步与多组学数据深度融合,实现对污染物来源、迁移与转化的系统解析。同时,若能结合物联网与实时监测技术,还可进一步发展为动态、智能化的环境污染预警与管理系统。这一方向不仅对科学研究具有推动意义,也将为环境监管部门提供高效的应对手段与科学决策支持。
作者简介
刘鹏:北京师范大学2025级博士生,主要从事不同环境介质的光谱质谱分析及机器学习溯源研究。

刘新会:北京师范大学,环境学院教授、博士生导师,教育部新世纪优秀人才,天山学者讲座教授。长期从事污染物的环境行为、环境效应、环境风险和控制技术研究。作为主持人承担国家973专题、国家自然科学基金以及环境保护部委托课题的研究工作,在水环境污染物的迁移机制、转化机理、检测方法、控制技术以及预测模型等研究方面取得了一定成绩。目前,已在Environmental Science & Technology、Water Research、Journal of Hazardous Materials等国内外知名SCI期刊发表科研论文130余篇;出版专著/教材7部。曾荣获国家科技进步二等奖1项,教育部奖励4项。

李立平:北京师范大学,自然科学高等研究院副教授、博士生导师。主要从事溶解性有机质有与消毒副产物、新型有机污染物的转化过程机制及环境风险评价等研究。目前已在Water Research、Environmental Science & Technology、Analytical Chemistry等JCR一区期刊上发表论文30余篇。主持国家自然科学基金面上项目、青年项目,国家重点研发计划子课题,山东省重点研发计划子课题等多项。现任中国环境科学学会水处理与回用专业委员会委员,并担任Chinese Chemical Letters、Water Cycle 青年编委。
投稿、合作、转载、进群,请添加小编微信Environmentor2020!环境人Environmentor是环境领域最大的学术公号,拥有20W+活跃读者。由于微信修改了推送规则,请大家将环境人Environmentor加为星标,或每次看完后点击页面下端的“在看”,这样可以第一时间收到我们每日的推文!环境人Environmentor现有综合群、期刊投稿群、基金申请群、留学申请群、各研究领域群等共20余个,欢迎大家加小编微信Environmentor2020,我们会尽快拉您进入对应的群。








