上一篇文章中,小编分享了一位狠人逆向研究了 OpenAI 的 ChatGPT 底层记忆机制。它的记忆系统主要分为四个板块:交互元数据、最近会话内容、模型设定上下文、用户知识记忆。
正是基于这样的设计,才会让 ChatGPT 充满了十足的留人能力。
那么,另一大头部的 AI 助手 Claude 又是怎样设计自身的记忆系统的呢?
昨天,Claude 的记忆系统也被逆向工程了一波,这位狠人的出的结论是:
Claude 与 ChatGPT 走的是两种截然不同的方向。
我又研究了 Claude,结果发现了一件很有意思的事情:这两大头部 AI 助手居然构建了完全相反的记忆系统。
ChatGPT 是“全都要”,Claude 是每次都“从0开始”。
这说明了各自的用户群体和产品哲学是什么?以及 AI 记忆设计的潜力空间到底有多大。
这篇文章中,作者首先拆解 Claude 的记忆机制——它到底存储什么、怎么取。然后,再聊更有趣的部分:为什么这两种架构会走向如此不同的道路?
这篇文章描述的剧烈反差感,引起了网友对于 OpenAI、Anthropic 这两大 AI 超级独角兽的疯狂讨论,评论数已经多达 231 条。
一些网友认为这是两家公司在为未来的商业模式做铺垫:ChatGPT 的方向性很明确,未来他们会通过广告和联盟链接盈利。而其记忆功能旨在创建用户画像。
而 Claude 的记忆实现感觉更侧重于访问抽象概念和过去交互的长期目标。
但更有意思的是,这篇逆向文章刚发布不久后,昨天 Claude 似乎也看到了用户的热烈讨论,很快为 Claude 上线了新的记忆功能:专为工作团队设计!
Claude 的工作方式:两个基本特征
Claude 的记忆系统有两个基本特征:
从零开始:每次对话都以一张白纸开场,不会自动加载用户画像或历史记录。只有当你明确调用记忆时,它才会启用。
原始记录检索:Claude 回忆时,只会基于你真实的对话记录,而不是依赖 AI 自动生成的摘要或压缩档案。它就像在做实时搜索,直接在你的历史聊天中查找。
当 Claude 通过类似
“我们之前聊过什么”、“从上次聊到的地方继续”、“还记得我说过……” 这样的提示检测到你在调用记忆时,它会调动两种检索工具。
这有点像你在用网页搜索或执行代码——Claude 会现场运行搜索,你能看到它“检索中”,等完成后再综合结果来回答或继续话题。
两种检索工具
| 1、会话检索 Conversation Search
conversation_search 工具用于关键词和主题搜索,覆盖你全部的对话历史。
比如我问它:“能回忆一下我们聊过的有关昌德尼朝克(德里的一处历史街区)的内容吗?”
Claude 找到了 9 段相关对话——从我研究贾汗娜拉·贝古姆公主在 1650 年建立该区的历史,到我问哪家烤肉串(galouti kebabs)和馅饼(parathas)最好吃。最后 Claude 把这些零散的记录整合成了一份连贯的总结。
如果你一次问多个主题,Claude 会依次进行多次搜索。比如我在做加密研究时,常用 Claude 做编辑。
有次我问它:“能告诉我我们聊过的关于米开朗基罗、Chainflip 或 Solana 的所有对话吗?”
ps:在区块链和加密领域,常见的项目名字经常会会借用艺术家、神话人物;后面的 Chainflip 或 Solana 是两个加密项目。
Claude 就分别跑了三次搜索:一次找我把米开朗基罗类比神经网络的内容,一次找 Chainflip 的跨链协议,一次找 Solana 的技术架构。最后一共找出 22 段对话,并生成了一个带跳转链接的统一回答。
| 2、短期对话检索 Temporal Chat Retrieval
recent_chats 工具提供按时间检索的能力。
我问它:“能告诉我最近 10 次对话聊了什么吗?” Claude 就按时间顺序把最近的聊天抓出来,并做了总结。
它还可以指定时间段。比如我问:“能告诉我 2024 年 11 月最后一周我们聊过什么吗?” Claude 就找出了那段时间里的 16 个对话。

ChatGPT向左:用户无需思考的魔法
Claude向右:让用户自己控制调用时机
时间回到一年前,ChatGPT 和 Claude 的功能几乎是对齐的——多模型、文件上传、项目管理都有。但从那以后,两者的路线分化明显。
ChatGPT:已经演变为一个大众级消费产品。OpenAI 的 CPO Mike Krieger 也承认他们在用户增长上“抓住了闪电”。记忆上,ChatGPT 走的是全自动化:所有记忆组件都会自动加载,用户无需思考,就能得到个性化体验。这意味着它会逐渐构建详细的用户画像,学习偏好与模式,为未来功能或商业化打基础。这是典型的消费级科技思路:做得足够“魔法”,用户黏住,之后再想办法变现。
Claude:走的是另一条路,聚焦开发者工具、编程和专业工作流。Anthropic 的用户群体更技术化,他们理解 LLM 的运作方式,也习惯自己控制调用的时机。就像他们会手动选择是否触发网页搜索或“扩展思考”,他们也决定什么时候需要记忆。用户知道调用记忆会增加延迟,但他们愿意做这种权衡。他们要的不是持续画像,而是一个强大、可预测的专业工具。而且,这类用户往往对隐私更敏感。
记忆的设计空间,没有唯一解
令人震撼的是:ChatGPT 和 Claude 这两大头部AI助手,居然构建了完全相反的记忆系统。这说明 AI 记忆的设计空间极其巨大,没有所谓的“唯一正确答案”。
设计记忆系统时,你必须从用户出发,根据他们的需求倒推,然后从零开始构建。
更关键的是,我们还处于未开垦的领域。这些工具问世还不到三年,没人知道如果同一个人用 AI 助手十年会怎样。
它应该记多少?要怎么处理累积多年的上下文?
与此同时,市面上正爆发出“寒武纪式”的 AI 应用,每家都在实验自己的记忆方式,而底层模型还在快速迭代。
而在应用侧,同样没有固定的打法,也没有最佳实践——大家都在试、在看:究竟谁能跑出来。
所以,原本是想研究记忆系统,结果却慢慢地牵扯出产品层面的思考。
几小时后:Claude 放出了新的记忆功能
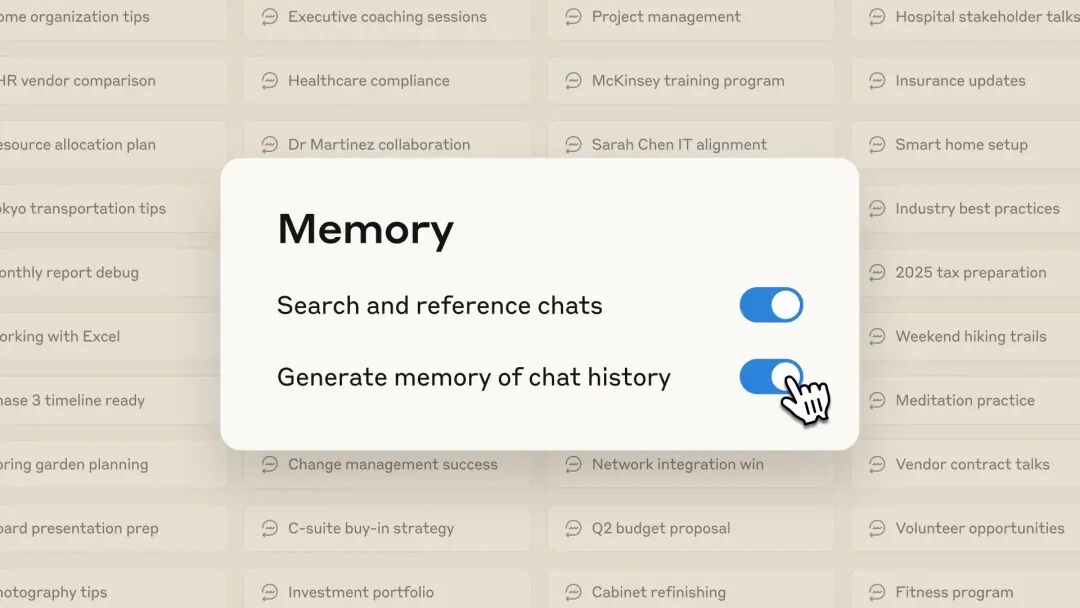
就在昨天晚上,作者发表了逆向文章后的几个小时后,Anthropic 就宣布,Claude 正式上线 记忆(Memory)功能。不过,一个关键的信号是:团队和企业用户可以率先体验。
这项功能可以在“设置”中启用。包含两个开关选项:“搜索并引用聊天记录”和“生成聊天历史记忆”。
来看一看,Claude 新发布的记忆功能的主要用途:
此外,在官方介绍中,Anthropic 特别强调了企业用户的控制权和隐私安全:
可选开启:用户可以自由决定 Claude 记住什么、不记住什么
隐身聊天:提供“一次性对话”,不会进入记忆或历史,非常适合敏感讨论
有时候,用户需要 Claude 的帮助,但又不想使用或增加记忆。这时就可以用隐身聊天,它提供了一张干净的对话“白纸”。这种模式非常适合敏感的头脑风暴、机密的战略讨论,或是单纯想要一次不带上下文的新对话。你的常规记忆和历史对话不会受到影响。如果你在团队版或企业版中使用记忆,标准的数据保留策略依然适用。
总之,通过“Memory”功能,Claude 会专注于学习用户的职业背景和工作模式,从而最大化生产力。
这里需要注意,记忆功能也带来了新的安全考量,所以 Anthropic 在设计时,强调:确保它适用于工作场景,同时避免涉及敏感话题。
官方博客中表示:Claude 团队将采取循序渐进的方式,以负责任的方式部署这些强大功能,并持续评估和测试记忆在不同使用场景中的表现,再逐步扩大适用范围。
OpenAI和Anthropic为什么走了相反的路?
乍看之下,两者路线还是比较清晰的。
最基本的区别:ChatGPT 想记住你这个人,而 Claude 关心的是企业用户之前的交互。
所以,OpenAI 更像是打造一款AI时代的万能微信,而 Anthropic 则避其锋芒,专门瞄准企业服务领域,所以更像是“企业钉钉”。
一位网友认为,Anthropic 和 OpenAI 的区别可能更多体现在商业目标上,而不是技术本身。
ChatGPT 的方向很明确:最终会通过广告和返佣链接来变现。他们的记忆实现方式,核心就是在建立用户画像。
Claude 的记忆实现更像是面向长期目标,关注的是如何访问抽象概念和过往交互。这很接近人类回忆的方式,只是多了个搜索功能(据我所知他们还没真正实现)。
有网友认为,Claude 的路线很清晰:以后可以结合 RL 后训练,让 Claude “记住”你上次指出的错误。在未来的迭代里,它甚至能从对话中提炼出抽象,比如“用户上次让我在这个任务里改了某些地方,也许这次我可以主动做”或者“上次代理是这样完成这个任务的”。
不过,小编判断,Anthropic 或许不会放弃个性化广告这个已相对成熟的商业模式的。
评论区的大佬们,你们又是如何看待的呢?欢迎拍砖。
参考链接:
https://www.shloked.com/writing/claude-memory
https://www.anthropic.com/news/memory
——好文推荐——
狠人研究公开!ChatGPT底层记忆系统终于被逆向了!没有RAG!用户设备信息、使用习惯统统存下来,用户知识记忆是新的研究热点!
数十亿人将用上免费AGI!OpenAI奥特曼高调断言:全球经济将迎来极度通缩!效率强如DeepSeek,全球AI也需百吉瓦能源!







