传统的神经网络就像流水线工人,只能按顺序逐个处理信息。而Transformer更像是一个圆桌会议——每个位置的信息都能同时与所有其他位置"对话"。
这种"全连接式交流"就是自注意力机制(Self-Attention)的威力。
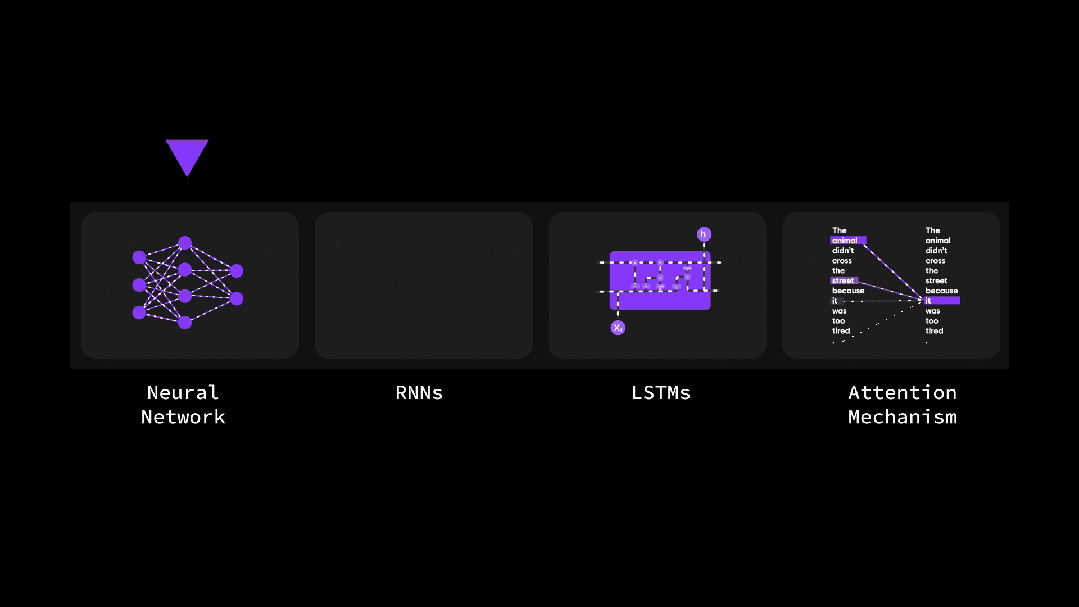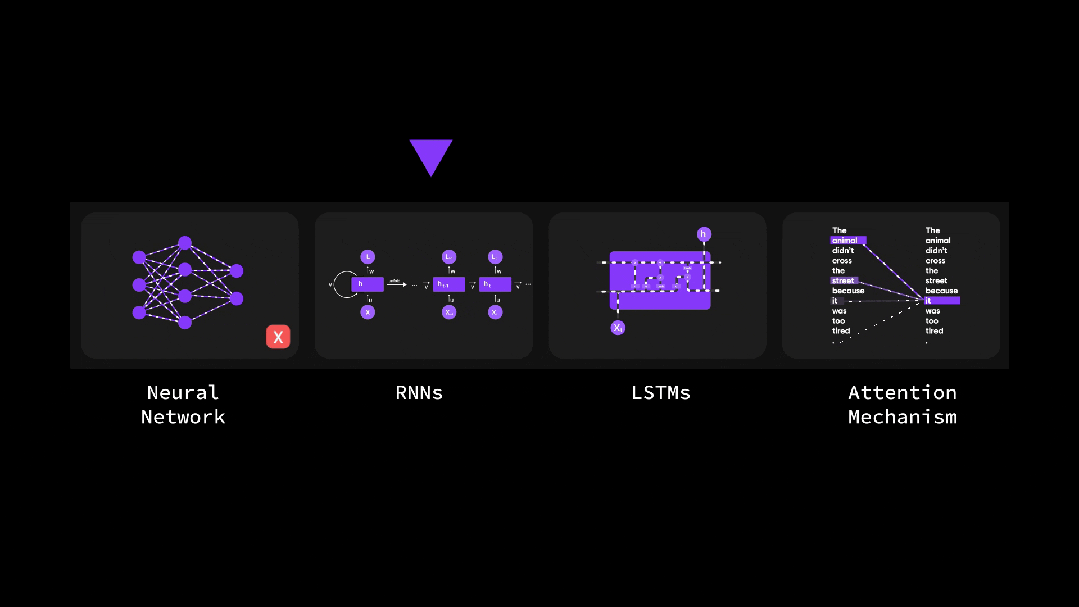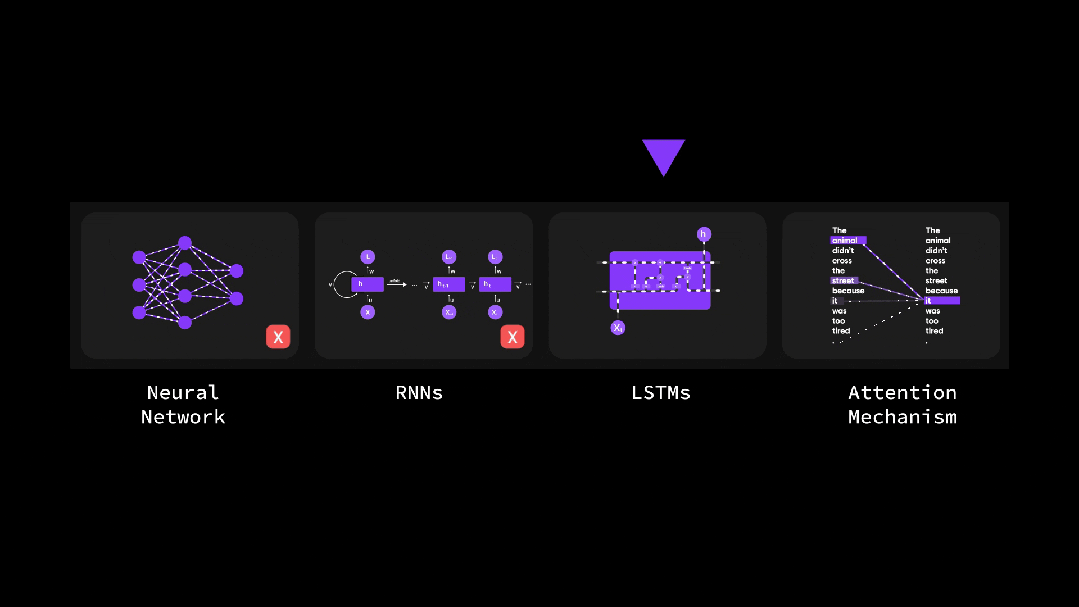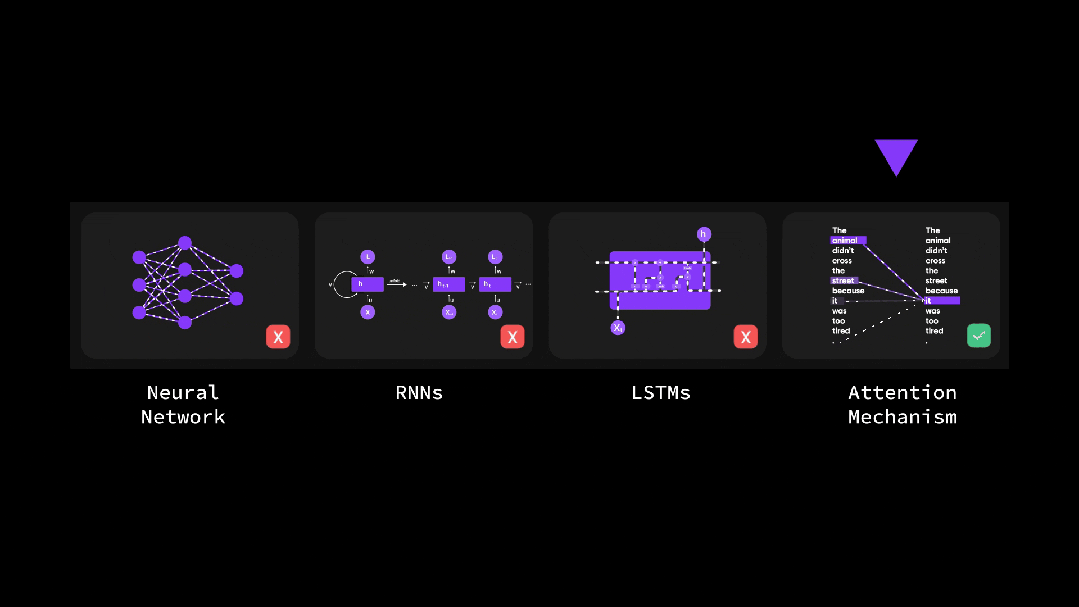
(1)自注意力机制是如何工作的?
彻底搞懂深度学习-为什么自注意力如此重要?(动图讲解)
Transformer动画讲解 - 数据处理的四个阶段
Transformer动画讲解 - 注意力机制
想象你在读这句话:"小明把苹果给了小红,她很开心。"
- 当处理"她"这个词时,人脑会自动回顾前文
- 发现"她"指代的是"小红",而不是"小明"或"苹果"
- 这种"回头看"的能力就是注意力
自注意力用数学语言描述这个过程:
输入句子:[小明, 把, 苹果, 给了, 小红, ,, 她, 很, 开心]当处理"她"时:- Query(查询):"她"想知道自己指代谁- Key(键值):每个词都提供自己的"身份标识" - Value(数值):每个词的具体含义信息注意力计算:"她" 对 "小明" 的注意力:0.1"她" 对 "小红" 的注意力:0.8 "她" 对 "苹果" 的注意力:0.05...最终理解:她 = 0.8×小红 + 0.1×小明 + 0.05×苹果 + ...
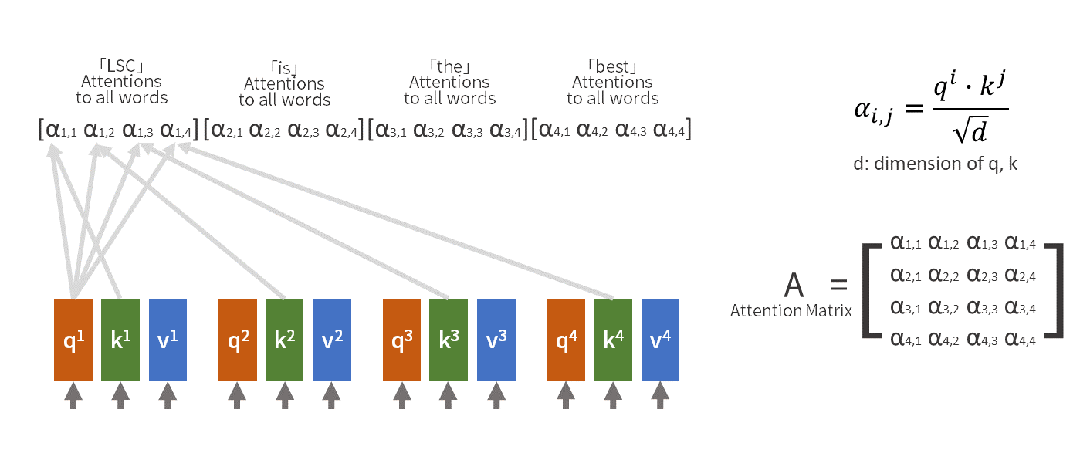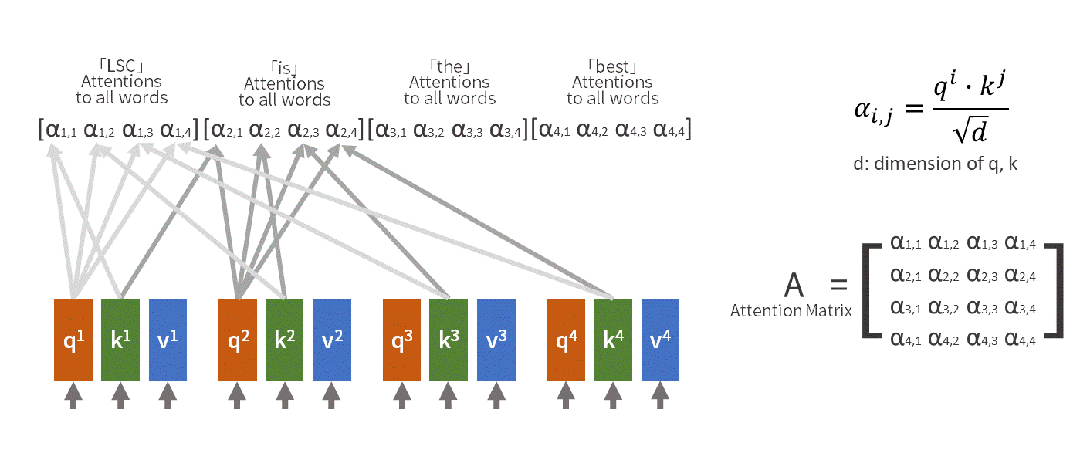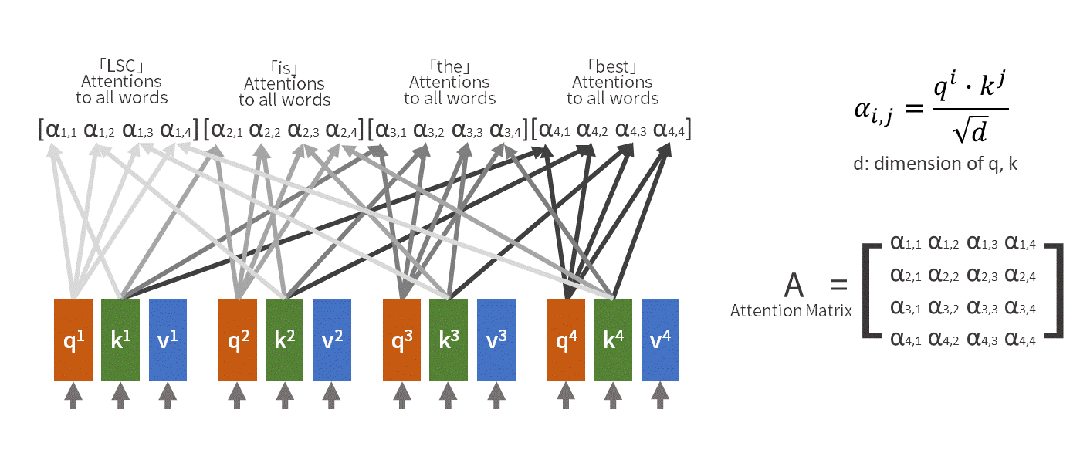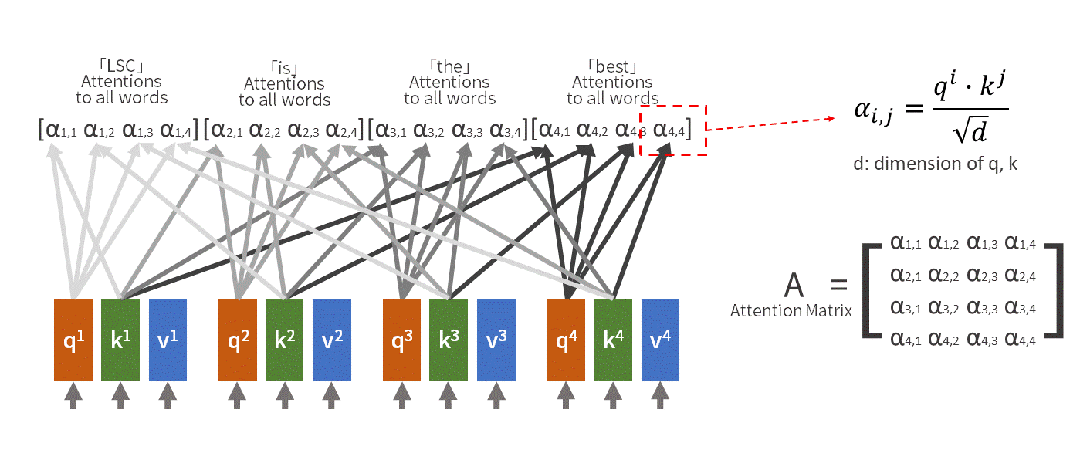
(2)多头注意力:为什么要"分身术"?
一文搞懂多头注意力(PyTorch)
单个注意力头就像用一只眼睛看世界,多头注意力让AI长出"复眼":
- 第1个头关注语法关系:"她"和"小红"在语法上呼应
- 第2个头关注语义关系:"开心"的情感主体是谁
- 第3个头关注长距离依赖:"她"可能指代很久之前提到的人物
每个头独立工作,最后汇总结果,就像多个专家从不同角度分析同一个问题。
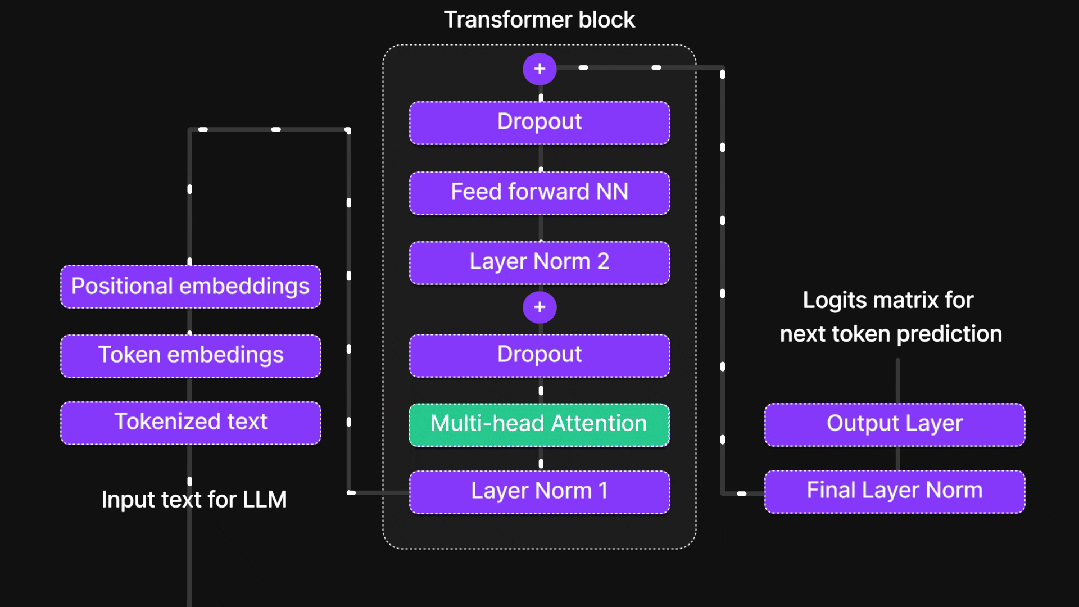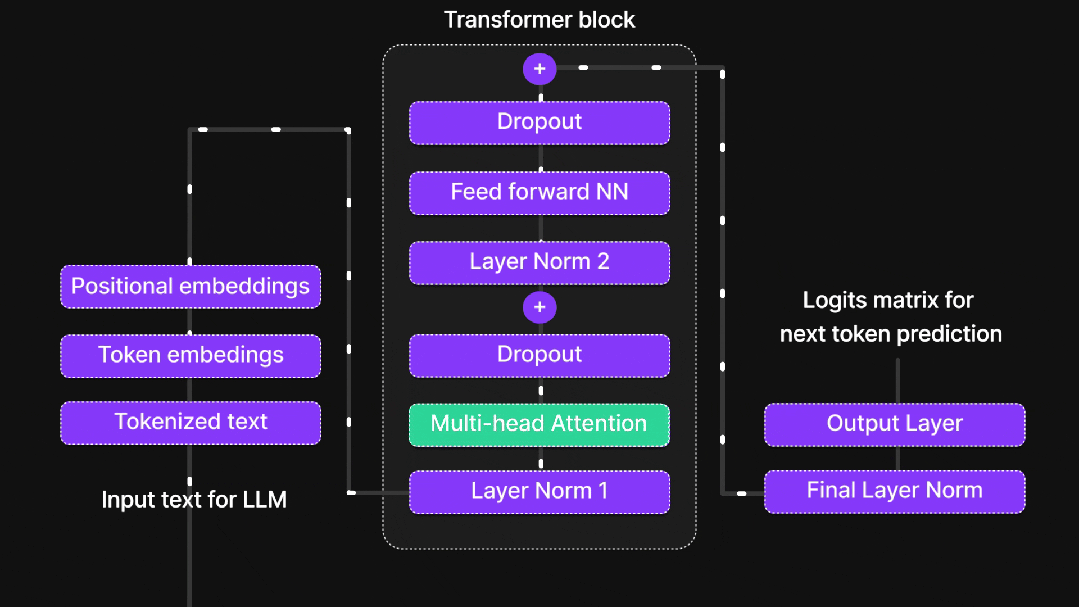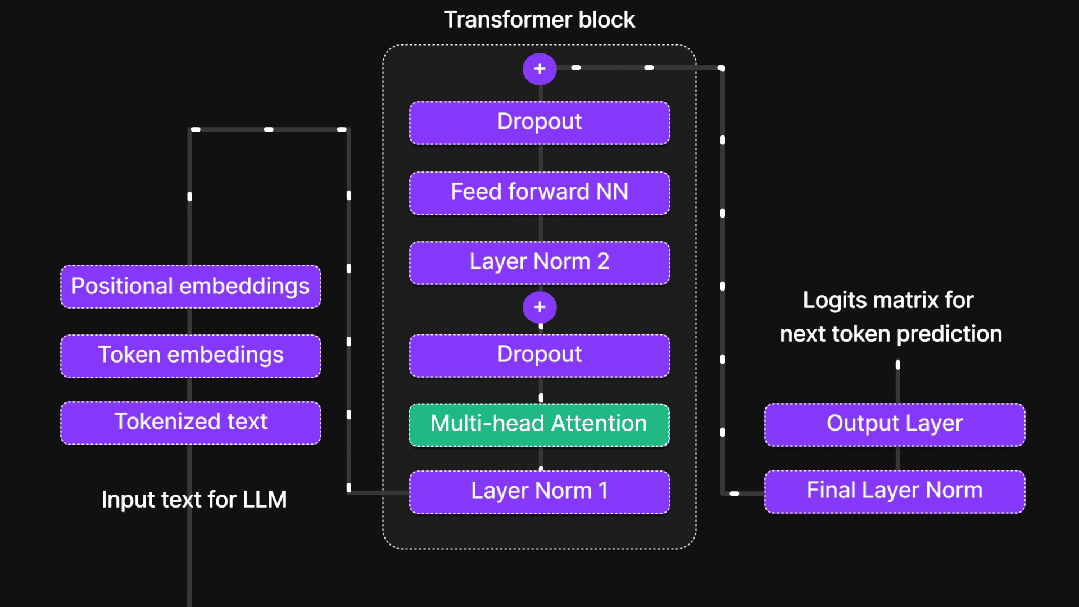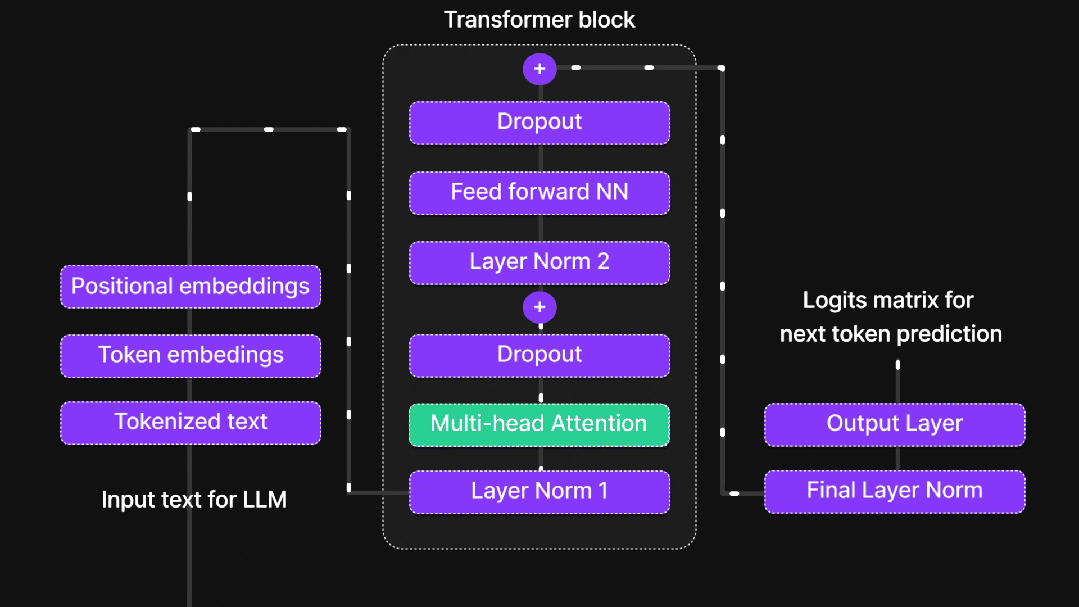
(3)位置编码:给每个位置一个"门牌号"
彻底搞懂深度学习-正余弦位置编码(动图讲解)
彻底搞懂深度学习-RoPE旋转位置编码(动图讲解)
彻底搞懂深度学习-多头注意力和位置编码(动图讲解)
Transformer的并行处理能力很强,但也带来一个问题——它天生不知道词语的顺序。
位置编码就像给每个座位标号:
原始输入:[我, 爱, 北京, 天安门]加上位置:[(我,位置1), (爱,位置2), (北京,位置3), (天安门,位置4)]这样AI就知道:- "我爱北京"和"北京爱我"是不同的意思- 词语的先后顺序很重要

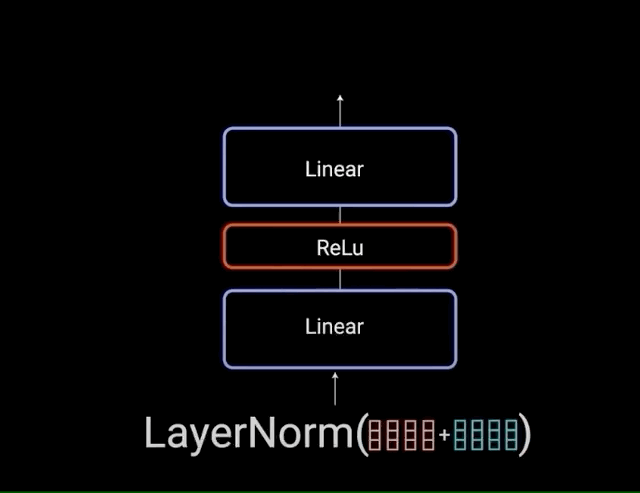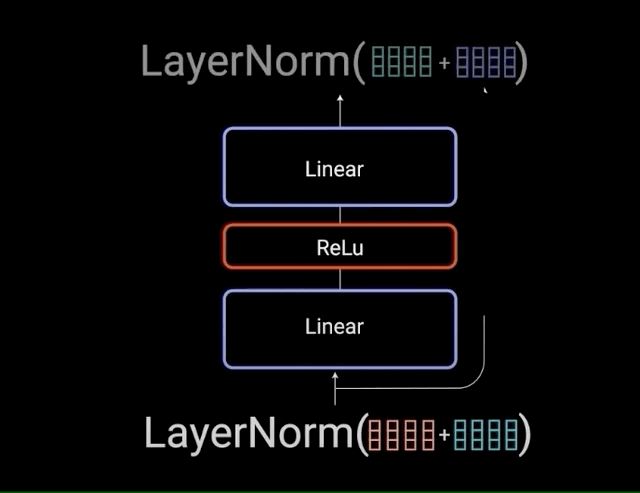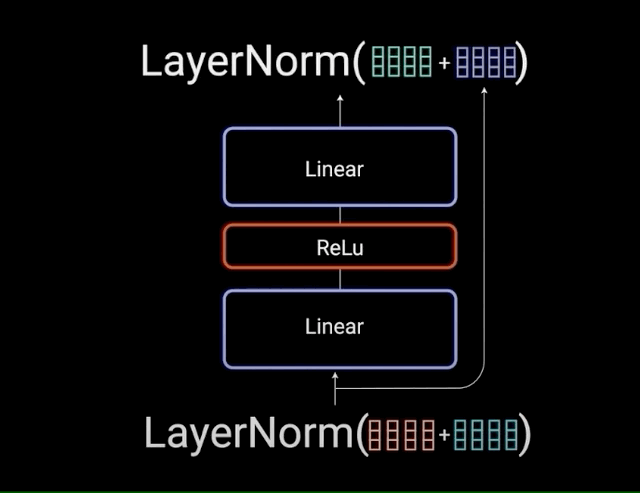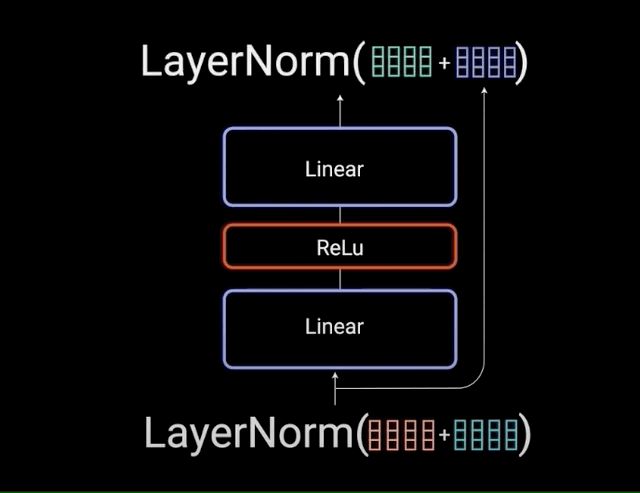
(4)Feed-Forward网络:深度思考的过程
Transformer动画讲解 - 多层感知机
注意力机制负责"信息收集",FFN负责"深度加工":
- 第一层:线性变换,扩展维度,让信息更丰富
- 激活函数:RELU,引入非线性,让模型能学习复杂模式
- 第二层:线性变换,压缩维度,提炼关键信息
这就像人的思维过程:先发散思考(扩展),再收敛总结(压缩)。