InnoDB 表是索引组织表,也就是所谓的索引即数据,数据即索引。索引分为聚集索引和二级索引,所有行数据都存储在聚集索引,二级索引存储的是字段值和主键,但不管哪种索引,其结构都是 B+tree 结构。
一棵 B+tree 分为根页、非叶子节点和叶子节点,一个简单的示意图(from Jeremy Cole)如下:
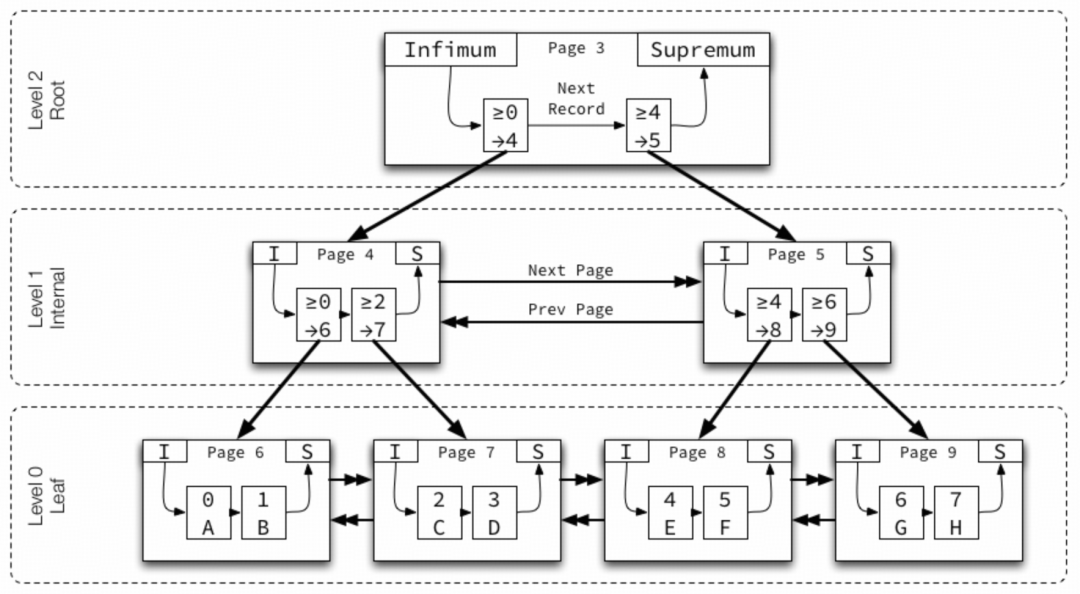
由于 InnoDB B+tree 结构高扇区特性,所以每个索引高度基本在 3-5 层之间,层级(Level)从叶子节点的 0 开始编号,沿树向上递增。每层的页面节点之间使用双向链表,前一个指针和后一个指针按key升序排列。
最小存储单位是页,每个页有一个编号,页内的记录使用单向链表,按 key 升序排列。每个数据页中有两个虚拟的行记录,用来限定记录的边界;其中最小值(Infimum)表示小于页面上任何 key 的值,并且始终是单向链表记录列表中的第一个记录;最大值(Supremum)表示大于页面上任何 key 的值,并且始终是单向链表记录列表中的最后一条记录。这两个值在页创建时被建立,并且在任何情况下不会被删除。
非叶子节点页包含子页的最小 key 和子页号,称为“节点指针”。
现在我们知道了我们插入的数据最终根据主键顺序存储在叶子节点(页)里面,可以满足点查和范围查询的需求。
默认一个页 16K 大小,且 InnoDB 规定一个页最少能够存储两行数据,这里需要注意规定一个页最少能够存储两行数据是指在空间分配上,并不是说一个页必须要存两行,也可以存一行。
怎么实现一个页必须要能够存储两行记录呢? 当一条记录 <8k 时会存储在当前页内,反之 >8k 时必须溢出存储,当前页只存储溢出页面的地址,需 20 个字节(行格式:Dynamic),这样就能保证一个页肯定能最少存储的下两条记录。
当一个记录 >8k 时会循环查找可以溢出存储的字段,text类字段会优先溢出,没有就开始挑选 varchar 类字段,总之这是 InnoDB 内部行为,目前无法干预。
建表时无论是使用 text 类型,还是 varchar 类型,当大小 <8k 时都是存储在当前页,也就是在 B+tree 结构中,只有 >8k 时才会进行溢出存储。
随着表数据的变化,对记录的新增、更新、删除;那么如何在 B+tree 中高效管理动态数据也是一项核心挑战。
MySQL InnoDB 引擎通过页面分裂和页面合并两大关键机制来动态调整存储结构,不仅能确保数据的逻辑完整性和逻辑顺序正确,还能保证数据库的整体性能。这些机制发生于 InnoDB 的 B+tree 索引结构内部,其具体操作是:
深入理解上述机制至关重要,因为页面的分裂与合并将直接影响存储效率、I/O模式、加锁行为及整体性能。其中页面的分裂一般分为两种:
表空间管理
InnoDB的B+tree是通过多层结构映射在磁盘上的,从它的逻辑存储结构来看,所有数据都被有逻辑地存放在一个空间中,这个空间就叫做表空间(tablespace)。表空间由段(segment)、区(extent)、页(page)组成,搞这么多手段的唯一目的就是为了降低IO的随机性,保证存储物理上尽可能是顺序的。
上面几个关键点铺垫完了,回到第一个问题,这里先直接说明根本原因,后面会阐述一下排查过程(有同学感兴趣所以分享一下,整个过程还是耗费不少时间)。
在『结构变更机制』介绍中,我们发现这种变更机制它有一个特点,就是【第三步】会导致新插入的记录可能会先写入到表中(主键 ID 大的记录先写入到了表),然后【第二步】中复制数据后写入到表中(主键 ID 小的记录)。这种写入特性叠加单行记录过大的时候(业务表单行记录大小 5k 左右),会碰到 MySQL 页分裂的一个瑕疵(暂且称之为瑕疵,或许是一个 Bug),导致了一个页只存储了 1 条记录(16k 的页只存储了 5k,浪费 2/3 空间),放大了存储问题。
下面直接复现一下这种现象下导致异常页分裂的过程:
CREATE TABLE `sbtest` ( `id` int(11) NOT NULL AUTO_INCREMENT, `pad` varchar(12000), PRIMARY KEY (`id`)) ENGINE=InnoDB;
然后插入两行 5k 大小的大主键记录(模拟变更时 binlog 回放先插入数据):
insert into sbtest values (10000, repeat('a',5120));insert into sbtest values (10001, repeat('a',5120));
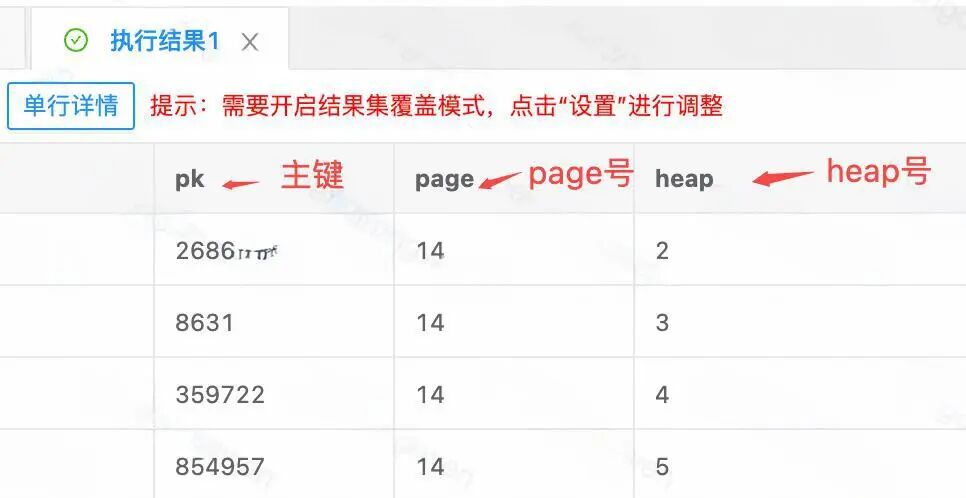
这里写了一个小工具打印记录对应的 page 号和 heap 号。
# ./peng[pk:10000] page: 3 -> heap: 2[pk:10001] page: 3 -> heap: 3
可以看到两条记录都存在 3 号页,此时表只有这一个页。
继续开始顺序插入数据(模拟变更时 copy 全量数据过程),插入 rec-1:
insert into sbtest values (1, repeat('a',5120));
# ./peng[pk:1] page: 3 -> heap: 4[pk:10000] page: 3 -> heap: 2[pk:10001] page: 3 -> heap: 3
插入 rec-2:
insert into sbtest values (2, repeat('a',5120));
# ./peng[pk:1] page: 4 -> heap: 2[pk:2] page: 4 -> heap: 3[pk:10000] page: 5 -> heap: 2[pk:10001] page: 5 -> heap: 3
可以看到开始分裂了,page 3 被提升为根节点了,同时分裂出两个叶子节点,各自存了两条数据。此时已经形成了一棵 2 层高的树,还是用图表示吧,比较直观,如下:
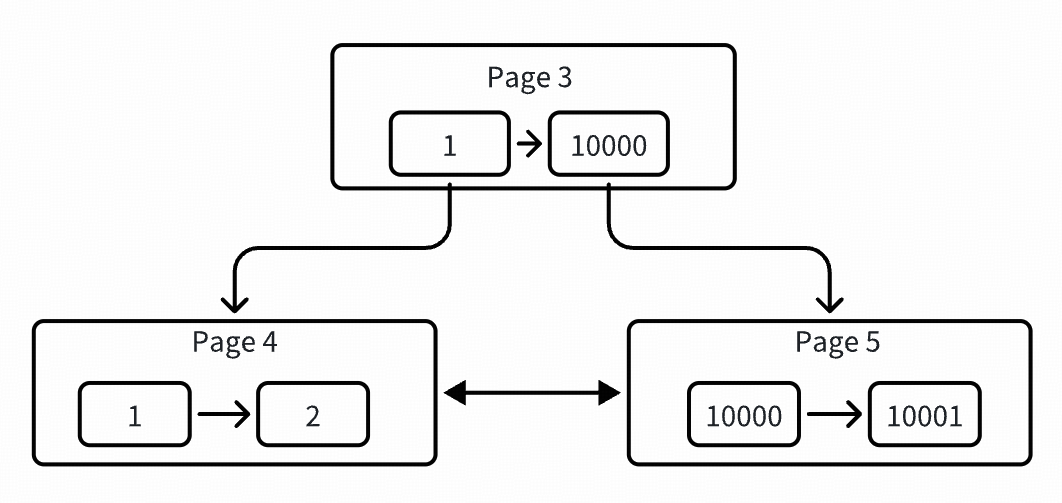
插入 rec-3:
insert into sbtest values (3, repeat('a',5120));
# ./peng[pk:1] page: 4 -> heap: 2[pk:2] page: 4 -> heap: 3[pk:3] page: 5 -> heap: 4[pk:10000] page: 5 -> heap: 2[pk:10001] page: 5 -> heap: 3
示意图如下:
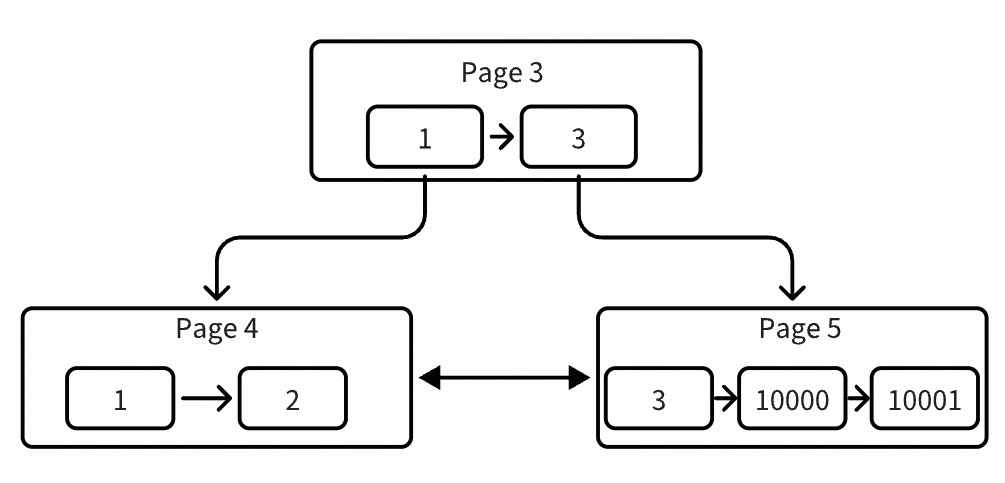
插入 rec-4:
insert into sbtest values (4, repeat('a',5120));
# ./peng[pk:1] page: 4 -> heap: 2[pk:2] page: 4 -> heap: 3[pk:3] page: 5 -> heap: 4[pk:4] page: 5 -> heap: 3[pk:10000] page: 5 -> heap: 2[pk:10001] page: 6 -> heap: 2
这里开始分裂一个新页 page 6,开始出现比较复杂的情况,同时也为后面分裂导致一个页只有 1 条数据埋下伏笔:
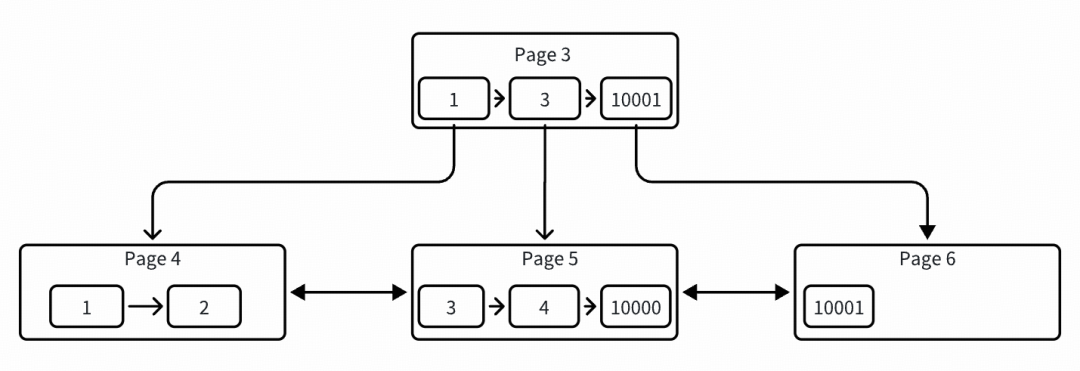
这里可以看到把 10001 这条记录从 page 5 上面迁移到了新建的 page 6 上面(老的 page 5 中会删除 10001 这条记录,并放入到删除链表中),而把当前插入的 rec-4 插入到了原来的 page 5 上面,这个处理逻辑在代码中是一个特殊处理,向右分裂时,当插入点页面前面有大于等于两条记录时,会设置分裂记录为 10001,所以把它迁移到了 page 6,同时会把当前插入记录插入到原 page 5。具体可以看 btr_page_get_split_rec_to_right 函数。
ibool btr_page_get_split_rec_to_right( btr_cur_t* cursor, rec_t** split_rec){ page_t* page; rec_t* insert_point;
page = btr_cur_get_page(cursor); insert_point = btr_cur_get_rec(cursor);
我们假设这里存在一个顺序插入的模式。 */
if (page_header_get_ptr(page, PAGE_LAST_INSERT) == insert_point) { rec_t* next_rec; next_rec = page_rec_get_next(insert_point); if (page_rec_is_supremum(next_rec)) { split_at_new: *split_rec = nullptr; } else { rec_t* next_next_rec = page_rec_get_next(next_rec); if (page_rec_is_supremum(next_next_rec)) { goto split_at_new; }
我们在该页上保留 1 条记录,因为这样后面的顺序插入就可以使用 自适应哈希索引,因为它们只需查看此页面上的记录即可对正确的 搜索位置进行必要的检查 */ *split_rec = next_next_rec; } return true; }
return false;}
插入 rec-5:
insert into sbtest values (5, repeat('a',5120));
# ./peng[pk:1] page: 4 -> heap: 2[pk:2] page: 4 -> heap: 3[pk:3] page: 5 -> heap: 4[pk:4] page: 5 -> heap: 3[pk:5] page: 7 -> heap: 3[pk:10000] page: 7 -> heap: 2[pk:10001] page: 6 -> heap: 2
开始分裂一个新页 page 7,新的组织结构方式如下图:
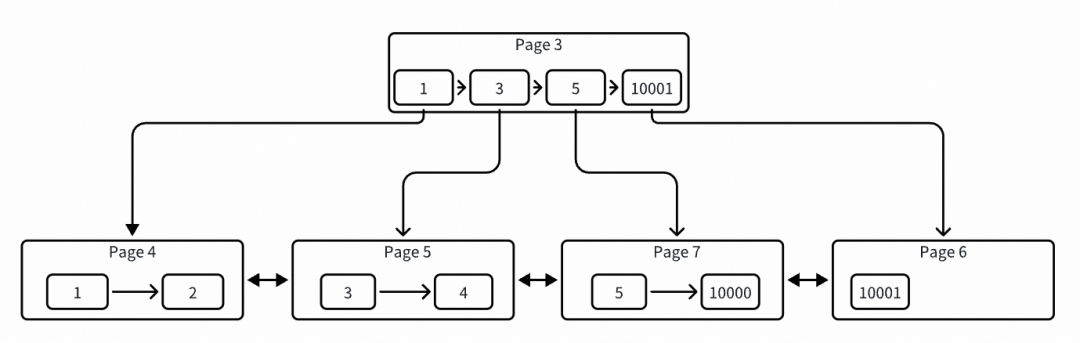
此时是一个正常的插入点右分裂机制,把老的 page 5 中的记录 10000 都移动到了 page 7,并且新插入的 rec-5 也写入到了 page 7 中。到此时看上去一切正常,接下来再插入记录在当前这种结构下就会产生异常。
插入 rec-6:
insert into sbtest values (5, repeat('a',5120));
# ./peng[pk:1] page: 4 -> heap: 2[pk:2] page: 4 -> heap: 3[pk:3] page: 5 -> heap: 4[pk:4] page: 5 -> heap: 3[pk:5] page: 7 -> heap: 3[pk:6] page: 8 -> heap: 3[pk:10000] page: 8 -> heap: 2[pk:10001] page: 6 -> heap: 2
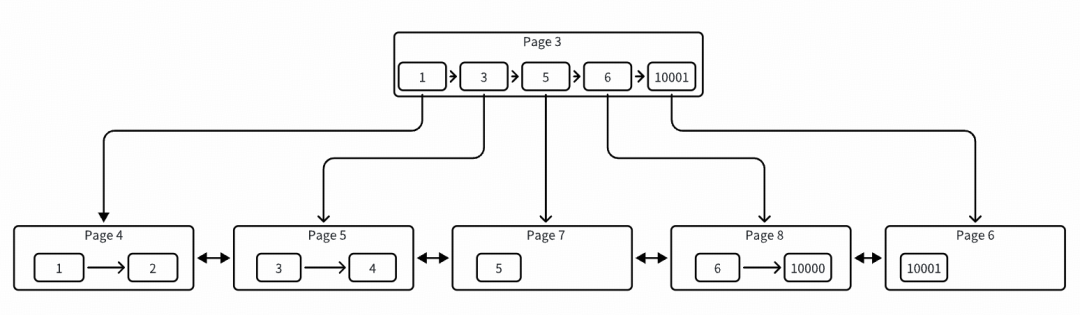
此时也是一个正常的插入点右分裂机制,把老的 page 7 中的记录 10000 都移动到了 page 8,并且新插入的 rec-6 也写入到了 page 8 中,但是我们可以发现 page 7 中只有一条孤零零的 rec-5 了,一个页只存储了一条记录。
按照代码中正常的插入点右分裂机制,继续插入 rec-7 会导致 rec-6 成为一个单页、插入 rec-8 又会导致 rec-7 成为一个单页,一直这样循环下去。
目前来看就是在插入 rec-4,触发了一个内部优化策略(具体优化没太去研究),进行了一些特殊的记录迁移和插入动作,当然跟记录过大也有很大关系。
有同学对这个问题排查过程比较感兴趣,所以这里也整理分享一下,简化了一些无用信息,仅供参考。
表总行数在 400 百万,正常情况下的大小在 33G 左右,变更之后的大小在 67G 左右。
基于现在这些信息我们知道了存储翻倍的根本原因,就是之前一个页存储 2 条记录,现在一个页只存储了 1 条记录,新的问题来了,为什么变更后会存储 1 条记录,继续寻找答案。
btr_cur_optimistic_insert:乐观插入数据,当前页直接存储
btr_cur_pessimistic_insert:悲观插入数据,开始分裂页
btr_root_raise_and_insert:单独处理根节点的分裂
btr_page_split_and_insert:分裂普通页,所有流程都在这个函数
btr_page_get_split_rec_to_right:判断是否是向右分裂
btr_page_get_split_rec_to_left:判断是否是向左分裂
heap
heap 是页里面的一个概念,用来标记记录在页里面的相对位置,页里面的第一条用户记录一般是 2,而 0 和 1 默认分配给了最大最小虚拟记录,在页面创建的时候就初始化好了,最大最小记录上面有简单介绍。
解析 ibd 文件
更快的方式还是应该分析物理 ibd 文件,能够解析出页的具体数据,以及被分裂删除的数据,分裂就是把一个页里面的部分记录移动到新的页,然后删除老的记录,但不会真正删除,而是移动到页里面的一个删除链表,后面可以复用。
表统计信息主要涉及索引基数统计(也就是唯一值的数量),主键索引的基数统计也就是表行数,在优化器进行成本估算时有些 SQL 条件会使用索引基数进行抉择索引选择(大部分情况是 index dive 方式估算扫描行数)。
InnoDB 统计信息收集算法简单理解就是采样叶子节点 N 个页(默认 20 个页),扫描统计每个页的唯一值数量,N 个页的唯一值数量累加,然后除以N得到单个页平均唯一值数量,再乘以表的总页面数量就估算出了索引总的唯一值数量。
但是当一个页只有 1 条数据的时候统计信息会产生严重偏差(上面已经分析出了表膨胀的原因就是一个页只存储了 1 条记录),主要是代码里面有个优化逻辑,对单个页的唯一值进行了减 1 操作,具体描述如下注释。本来一个页面就只有 1 条记录,再进行减 1 操作就变成 0 了,根据上面的公式得到的索引总唯一值就偏差非常大了。
static bool dict_stats_analyze_index_for_n_prefix( ... uint64_t n_diff_on_leaf_page; dict_stats_analyze_index_below_cur(pcur.get_btr_cur(), n_prefix, &n_diff_on_leaf_page, &n_external_pages); 一次是某个页面的最后一个值,一次是另一个页面的第一个值。请考虑以下示例: Leaf level: page: (2,2,2,2,3,3) ... 许多页面类似于 (3,3,3,3,3,3)... page: (3,3,3,3,5,5) ... 许多页面类似于 (5,5,5,5,5,5)... page: (5,5,5,5,8,8) page: (8,8,8,8,9,9) 我们的算法会(正确地)估计平均每页有 2 条不同的记录。 由于有 4 页 non-boring 记录,它会(错误地)将不同记录的数量估计为 8 条 */ if (n_diff_on_leaf_page > 0) { n_diff_on_leaf_page--; } n_diff_data->n_diff_all_analyzed_pages += n_diff_on_leaf_page;)
可以看到PRIMARY主键异常情况下统计数据只有 20 万,表有 400 百万数据。正常情况下主键统计数据有 200 百万,也与表实际行数差异较大,同样是因为单个页面行数太少(正常情况大部分也只有2条数据),再进行减1操作后,导致统计也不准确。
MySQL> select table_name,index_name,stat_value,sample_size from mysql.innodb_index_stats where database_name like 'sbtest' and TABLE_NAME like 'table_1' and stat_name='n_diff_pfx01';+| table_name | index_name | stat_value | sample_size |+| table_1 | PRIMARY | 206508 | 20 |+11 rows in set (0.00 sec)
优化
为了避免相邻两次dive统计到连续的相同的两个数据,因此减1进行修正。
这里应该是可以优化的,对于主键来说是不是可以判断只有一个字段时不需要进行减1操作,会导致表行数统计非常不准确,毕竟相邻页不会数据重叠。
最低限度也需要判断单个页只有一条数据时不需要减1操作。
当前 MySQL 对大部分 SQL 在评估扫描行数时都不再依赖统计信息数据,而是通过一种 index dive 采样算法实时获取大概需要扫描的数据,这种方式的缺点就是成本略高,所以也提供有参数来控制某些 SQL 是走 index dive 还是直接使用统计数据。
另外在SQL带有 order by field limit 时会触发MySQL内部的一个关于 prefer_ordering_index 的 ORDER BY 优化,在该优化中,会比较使用有序索引和无序索引的代价,谁低用谁。
当时业务有问题的慢 SQL 就是被这个优化干扰了。
user_id = ? and biz = ? and is_del = ? and status in (?) ORDER BY modify_time limit 5idx_modify_time(`modify_time`)idx_user_biz_del(`user_id`,`biz`, `is_del`)
正常走 idx_user_biz_del 索引为过滤性最好,但需要对 modify_time 字段进行排序。
这个优化机制就是想尝试走 idx_modify_time 索引,走有序索引想避免排序,然后套了一个公式来预估如果走 idx_modify_time 有序索引大概需要扫描多少行?公式非常简单直接:表总行数 / 最优索引的扫描行数 * limit。
使用有序索引预估的行数对比最优索引的扫描行数来决定使用谁,在这种改变索引的策略下,如果表的总行数估计较低(就是上面主键的统计值),会导致更倾向于选择有序索引。
但一个最重要的因素被 MySQL 忽略了,就是实际业务数据分布并不是按它给的这种公式来,往往需要扫描很多数据才能满足 limit 值,造成慢 SQL。









