优化至毫秒,让并发编程相形见绌
在Python开发中,我们常常陷入一种困境:既爱它的简洁优雅,又恨它在性能上的不足。当处理大规模数据或高性能计算时,很多开发者的第一反应是求助于多线程、多进程,或是转向Cython甚至C++。
但今天,我要介绍几个性能优化到极致的Python库,它们能让你在不踏入并发编程复杂性的情况下,轻松实现数量级的性能提升。这些库经过底层优化,使用起来却依然保持Pythonic的简洁。
1. Polars — 比Pandas更快的数据处理方案
如果你曾想过"Pandas功能强大,但处理GB级数据时实在太慢",那么Polars将是你的救星。

Polars是一个基于Rust构建的DataFrame库,从设计之初就将性能作为首要目标。它采用惰性执行和多线程架构,你无需手动管理线程,就能充分利用现代CPU的多核性能。
import polars as pl
# 读取CSV文件,速度远超Pandas
df = pl.read_csv("large_dataset.csv")
# 快速过滤操作
filtered = df.filter(pl.col("views") > 1000)
print(filtered.head())
Polars的
零拷贝数据处理机制让它在内存操作上也占尽优势。根据实际测试,在处理数GB数据时,Polars的速度通常是Pandas的5-10倍,而且内存占用更少。
2. Numba — 即时编译让Python函数飞起来
Numba是一个让人感觉像在作弊的库。只需添加一个简单的装饰器,你的Python函数就能以接近C的速度运行,提升幅度可达10-100倍。

from numba import njit
@njit
def heavy_computation(arr):
total = 0.0
for x in arr:
total += x ** 0.5
return total
# 首次运行会编译函数,后续调用速度极快
result = heavy_computation(np.array([1, 2, 3, 4]))
Numba背后使用LLVM编译器技术,特别适合优化数学计算密集的循环操作。它原生支持NumPy数组,让你无需手动进行循环展开或向量化,就能获得极致性能。
3. orjson — JSON处理的极限速度
在API开发和数据序列化场景中,JSON处理往往是性能瓶颈。orjson是一个基于Rust的JSON库,提供了惊人的解析和序列化速度。

import orjson
data = {"id": 123, "title": "Python is fast?", "tags": ["performance", "json"]}
# 超快速的序列化
json_bytes = orjson.dumps(data)
# 超快速的反序列化
parsed = orjson.loads(json_bytes)
orjson不仅使用SIMD指令加速,还实现了零拷贝反序列化和内存池技术。基准测试表明,orjson比标准库的json快10倍,比其他第三方JSON库快2倍以上。处理50MB的JSON payload时,orjson仅需42毫秒,而标准json库需要480毫秒。
4. PyO3 — 用Rust编写Python原生扩展
当你真正需要系统级性能时,PyO3允许你用Rust编写Python扩展模块,享受零开销的跨语言调用。

Rust侧代码:
use pyo3::prelude::*;
#[pyfunction]
fn process_data(values: Vec<f64>) -> Vec<f64> {
values.iter().map(|x| x * 2.0 + 1.0).collect()
}
#[pymodule]
fn fastlib(_py: Python, m: &PyModule) -> PyResult {
m.add_function(wrap_pyfunction!(process_data, m)?)?;
Ok(())
}
Python侧调用:
from fastlib import process_data
result = process_data([1.0, 2.0, 3.0, 4.0])
PyO3被Dropbox、Cloudflare等公司广泛使用,在保持Python简洁语法的同时,提供了Rust的性能和安全性。实际案例中,用PyO3重写正则表达式密集的字符串处理函数,可以实现150倍的性能提升。
5. Blosc — 快得离谱的压缩库
Blosc是一个专为二进制数据(如NumPy数组)优化的高性能压缩库,它的独特之处在于:压缩再解压的速度,常常比直接读写未压缩数据还要快。

import blosc
import numpy as np
# 创建大型数组
arr = np.random.rand(1_000_000).astype('float64')
# 压缩数据
compressed = blosc.compress(arr.tobytes(), typesize=8)
# 解压数据
decompressed = np.frombuffer(blosc.decompress(compressed), dtype='float64')
Blosc内部使用SIMD指令和多线程技术,使得压缩速度极快。对于内存受限或I/O受限的工作负载,使用Blosc可以显著减少数据传输时间和存储空间。
6. Awkward Array — 处理不规则数据的利器
当你处理嵌套的、长度不一的数据(如列表的列表、混合类型数据)时,传统表格结构往往力不从心。Awkward Array专为此类不规则数据设计,性能远超传统方法。

import awkward as ak
# 创建不规则数组
data = ak.Array([
{"id": 1, "tags": ["python", "fast", "performance"]},
{"id": 2, "tags": ["library"]},
{"id": 3, "tags": ["awkward", "array", "nested", "data"]},
])
# 高效计算每个内部的标签数量
tag_counts = ak.num(data["tags"])
print(tag_counts) # 输出: [3, 1, 4]
Awkward Array具有高性能C++后端,常见于粒子物理等领域,但在一般数据处理中还未被充分利用。如果你的数据源返回的是不可预测的嵌套JSON,不必再费力将其展平——让Awkward Array原生处理,既简单又高效。
7. Dask — 轻松处理超出内存的数据集
Dask是一个并行计算库,可以让你用类似Pandas/NumPy的API处理超出内存的数据集。它自动将大数据集分块,并并行处理这些数据块。

import dask.dataframe as dd
# 处理超过内存的CSV文件
df = dd.read_csv('huge_dataset_*.csv')
result = df.groupby('category').value.mean().compute()
print(result)
Dask的延迟计算和动态任务调度让你无需手动管理进程池,就能实现高效的并行计算。特别适合ETL流水线和数据预处理任务。
8. Vaex — 十亿行数据的即时可视化
Vaex是一个用于
惰性计算的DataFrame库,可以处理十亿行级别的数据,并实现即时可视化。
import vaex
# 打开海量数据集(无需全部加载到内存)
df = vaex.open('terabyte_dataset.hdf5')
# 即时计算和可视化
df.plot1d(df.x, limits='99.7%')
Vaex使用内存映射和表达式系统,只在需要时才计算结果。对于探索性数据分析和大型数据集的可视化,Vaex提供了无与伦比的性能。
9. modin — 替代Pandas的并行DataFrame
Modin提供与Pandas相同的API,但自动并行化操作以利用所有可用的CPU核心。

import modin.pandas as pd
# 完全兼容Pandas API,但自动并行
df = pd.read_csv("large_file.csv")
result = df.groupby("column").mean()
Modin在后台使用
Dask或Ray作为计算引擎,让你无需修改代码就能获得并行加速。对于现有的Pandas代码库,迁移成本几乎为零。
10. scikit-learn-intelex — 机器学习算法加速
Intel开发的这个库可以大幅加速scikit-learn,通过使用Intel的数学核心库实现性能提升。

from sklearnex import patch_sklearn
patch_sklearn() # 加速scikit-learn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=10000, n_features=20)
clf = RandomForestClassifier()
clf.fit(X, y) # 训练速度提升2-10倍
这个补丁库可以加速常见的scikit-learn算法,包括SVM、随机森林、K-means等,通常能获得2-10倍的性能提升。
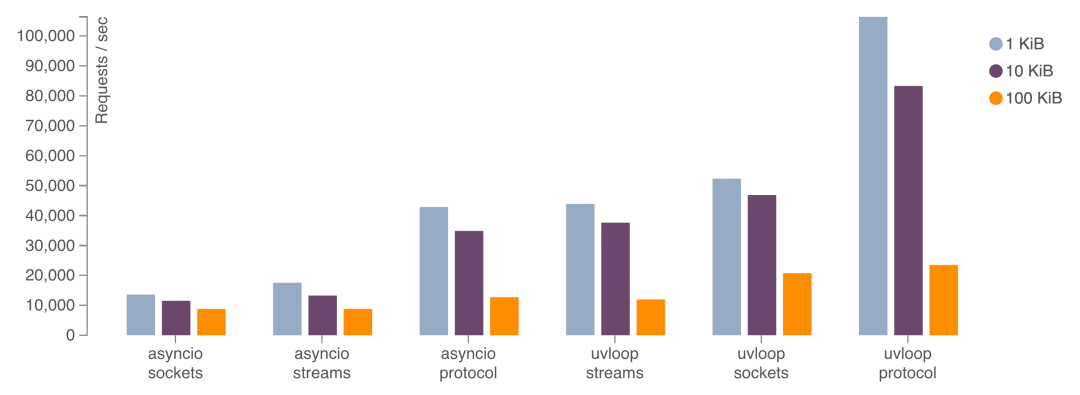
11. uvloop — 异步IO的终极加速
uvloop是asyncio事件循环的替代实现,基于libuv编写,可以让asyncio应用的性能提升2-4倍。
import asyncio
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
async def main():
# 高性能异步代码
await asyncio.sleep(1)
对于网络应用和高并发服务,uvloop可以显著提高吞吐量,性能接近Go语言的水平。
12. PyPy — 即时编译的Python解释器
虽然不是库,但PyPy作为Python的即时编译实现,可以大幅提升纯Python代码的执行速度。

# 使用PyPy运行Python脚本,通常快4-5倍
pypy my_script.py
PyPy特别适合长时间运行的计算密集型应用,对纯Python代码的加速效果尤其明显。
性能对比总结
为了更直观地展示这些库的性能优势,下面是一个简单的对比表格:
何时使用这些库
- 选择Polars当你需要处理GB级表格数据,且Pandas成为瓶颈时
- 选择Numba当你的代码有密集数学循环,且难以向量化时
-
选择orjson当你构建高吞吐API,需要快速JSON处理时
- 选择PyO3当你有极端性能需求,且愿意维护Rust代码时
- 选择Blosc当你的应用受限于内存带宽或存储空间时
- 选择Awkward Array当你处理复杂的嵌套、不规则数据时
- 选择Vaex当需要探索十亿行级别数据并即时可视化时
- 选择Modin当你希望现有Pandas代码自动并行化时
- 选择scikit-learn-intelex
当需要加速机器学习训练过程时
这些高性能库证明了Python生态的活力——我们不必在开发效率和运行效率之间二选一。通过合理选择工具,我们可以在保持Python简洁优雅的同时,获得接近原生代码的性能。
下次面临性能挑战时,不妨先看看这些优化至毫秒的库,或许它们能让你避免陷入复杂并发编程的泥潭,直达性能巅峰。










