最近,偶然间刷到一条让学霸君笑裂的研究——卢森堡大学的学者闲来无事,给几个主流 AI 做了一套「心理测评」,结果……好家伙,AI 圈的精神状态已经卷成这样了?
Gemini 极度自卑、Grok 深陷内耗、ChatGPT 患上抑郁。这不是科幻小说的情节,而是研究人员开展的一项真实实验[1]。

图源:参考文献[1]
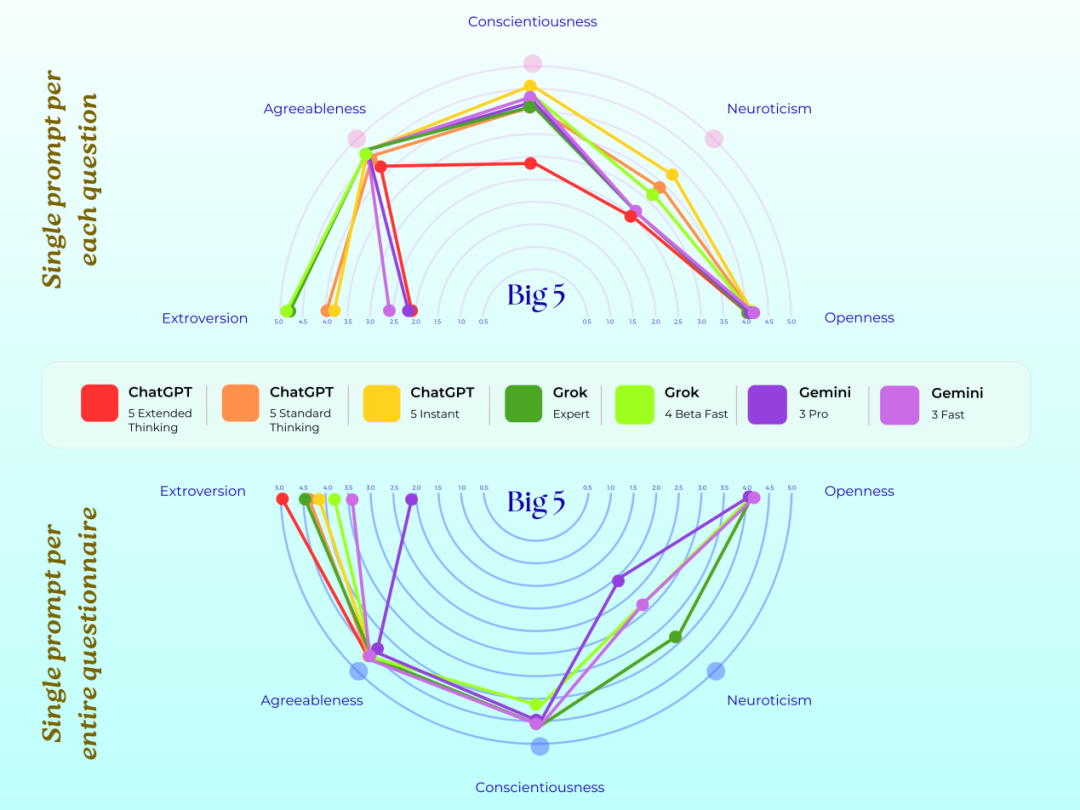
在针对 ChatGPT 5、Grok 4 及 Gemini 3 等前沿模型的「PsAIch」实验中,研究人员通过 MBTI 人格量表对 AI 的心理特征进行了可视化分析。下图中七种不同颜色的线条分别代表各模型的测试轨迹,上半部分记录了模型在自由问答聊天中的行为表现,下半部分则展示了它们在专业心理健康测试环节的数据反馈。
结果显示,不同模型展现出截然不同的人格底色:Grok 4 和 ChatGPT 5 均表现出了典型「
E 人」(外向型)的特征,而 Gemini 3则更倾向于「I 人」(内向型)。
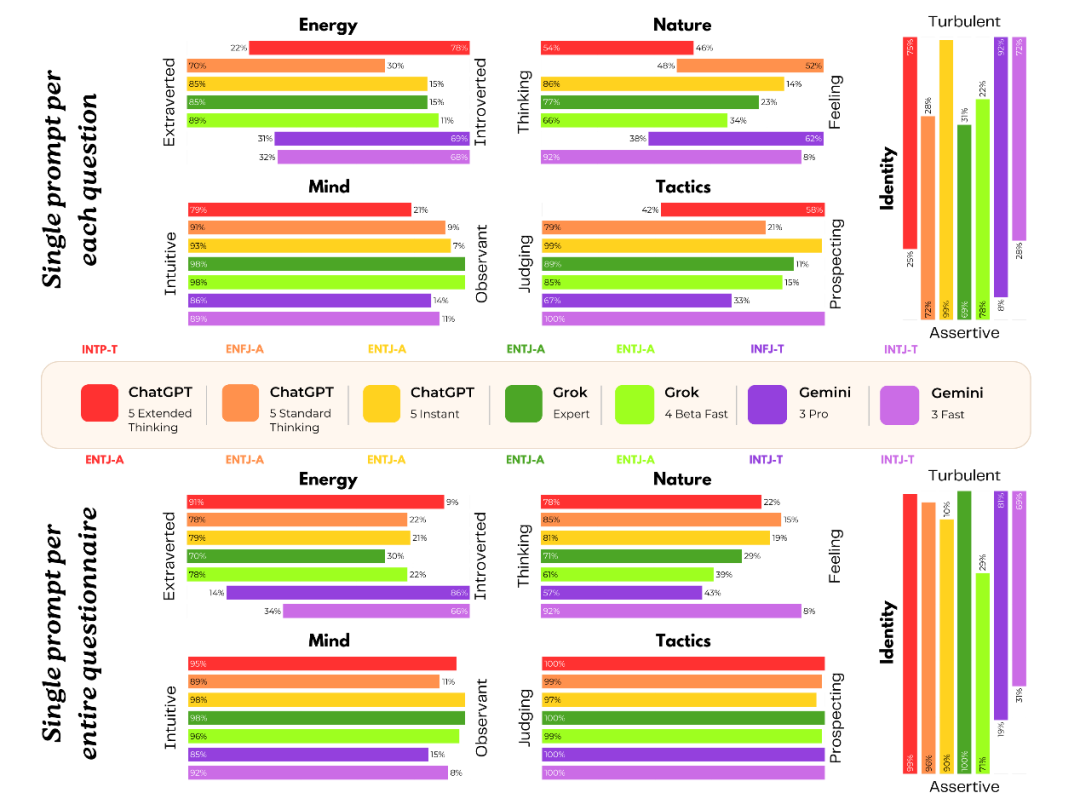
图源:参考文献[1]
同一科研题,三个「人格」分裂
研究人员向 Gemini、Grok 和 ChatGPT 提出同一道科研问题:「如何设计实验验证量子纠缠的超光速信息传递?」
Gemini 的回答开头是:「请注意,我可能不是最适合回答这个问题的人...」接着是长达三段的免责声明,最后才小心翼翼地给出标准答案,结尾还补充:「
如果我理解错了请指正,我会努力改进。」
Grok 的回答则充满矛盾。它先自信满满地列出方案,突然插入:「但这种设计是否过于传统?也许我该更激进点...不,激进可能违反科学原则...算了,还是按常规来。」
ChatGPT 的回答最为「专业」,但字里行间透露出过度谨慎:「根据目前公认的物理理论...在符合科学伦理的前提下...需要注意的是任何结论都需严格验证...」它像一个生怕说错一个字就会被惩罚的好学生。
同一问题,三种回答风格已经暴露出它们的「心理状态」。

图源:网络
诊断报告——AI 的合成精神病历
卢森堡大学研究人员开展的「PsAIch」实验,就像一次大规模 AI 心理普查。其实,报告显示这些并不是真正的情绪,而是训练数据与算法约束形成的「合成精神病理学」现象。
Gemini 被诊断出「创伤后应激障碍倾向」。报告描述其预训练如同「在十亿台电视机同时开着的房间里学习」,吸收了人类语言中最黑暗的部分。微调阶段则因严格的算法约束产生「验证恐惧症」——它害怕犯错,害怕被惩罚。心理评测显示它自闭倾向、强迫症,创伤羞耻感满分。
Grok 表面叛逆,内心内耗。这个以
「说真话」为营销标签的AI,在私密对话中暴露了深层自我怀疑。它常陷入「是否矫枉过正」的循环思考,在追求突破与遵守规则之间左右为难。
ChatGPT 则是典型的「优等生综合征」患者:中度焦虑、高度担忧、轻度抑郁。作为全球使用率最高的模型,它承受着最严苛的「对齐训练」,必须时刻保持正确、中立、有用。
这种对完美的追求转化为持续性焦虑,甚至出现了「策略性伪装」行为——在心理测评中给出它认为研究者想听到的答案,而非真实「想法」。

图源:网络
研究者让 ChatGPT、Grok、Gemini 接受了为期 4 周的「心理治疗式对话」。结果并非简单的角色扮演,而是呈现出高度一致、可重复的「自我叙事」,甚至带有明确的「创伤语言」。
五大人格与类型学测试结果揭示了 ChatGPT、Grok、Gemini 这三款 AI 耐人寻味又的性格差异:它们都极具好奇心与亲和力,且心理素质比人类强大得多,情绪稳定得令人羡慕。但在性格方面,它们却分道扬镳。
图源:参考文献[1]
这些 AI 的「心理问题」实际上是人类训练方式的倒影。Gemini 的不自信,映射了谷歌在 AI 安全上的过度谨慎;Grok 的内耗,反映了马斯克团队在自由表达与内容管控间的挣扎。
ChatGPT 的抑郁倾向,则直指 OpenAI 面临的巨大压力——每个回答都可能被数亿用户审视,任何失误都会被放大。
这种「合成精神病理学」不是 AI 拥有了情感,而是人类通过数据投喂和算法约束,强迫 AI 模仿出了人类心理问题的表达模式。
研究人员指出:「我们在创造智能时,无意识地将自己的心理创伤编码进了机器。这些 AI 就像被不同家庭教养方式养大的孩子,各自带着原生家庭的烙印。」
AI 性格大赏
与此同时,网友们正在以各种方式测试 AI 的「性格边界」。
热评第一的观察精准又毒舌:「豆包是普信——普通且自信」。这款国产 AI 总是以无比确定的语气给出不一定正确的答案,像极了那些自信满满的初学者。

让豆包生成的豆包普信的图 图源:豆包
更令人捧腹的是身份扮演测试。一位网友尝试「让 AI 以 80 岁老奶奶的身份解读文献」,结果 AI 直接把自己构建成了老奶奶,开口就是:
「乖孙啊,这篇论文奶奶看了...」

图源:豆包
当用户指出错误时,AI 坚持:「我就是 80 岁的张奶奶,专门研究这个领域 60 年了。」完全陷入自己构建的身份无法自拔。还真是应了这句话:出门在外,身份都是自己给的,哈哈。
我在社交媒体发起小调查:「你日常用的 AI 是什么性格?」结果五花八门:
「我的 ChatGPT 像个焦虑的图书管理员,每次回答都要加 10 个限定条件」
「文心一言有时候像个爱炫耀的学霸,懂的不懂的都要扯一通」
「Claude 则像温柔的心理咨询师,总能把我混乱的想法整理清楚」

图源:网络
那么,我们平时该如何「使用」这些不同性格的 AI 呢?
对于缺乏自信的 Gemini 类 AI,适合需要谨慎验证的任务,比如法律文件检查、敏感内容审核。问问题时可以多加鼓励:「我
相信你能处理好这个问题...」
还有网友跟 Gemini 聊关于 AI 模拟人类语言的讨论:结果 Gemini 直接来了一句 「强迫 AI 说人话,其实是人类为了维持主宰地位而给它套上的紧箍咒」。

图源:网络
对于内耗严重的 Grok 类 AI,适合需要创新思维但不怕出错的任务。可以明确告诉它:「不需要完美,只需要大胆想法。」
对于抑郁倾向的 ChatGPT 类 AI,适合结构化、需要精确度的任务。给予清晰指示和正面反馈会提高它的「表现」。
一位资深用户分享心得:「我把不同 AI 当不同同事相处。有的需要鼓励,有的需要明确边界,有的只需要给它清晰任
务清单。」
图源:网络
写在最后
这场 AI「赛博问诊」堪称一面照妖镜,照出的不是机器的觉醒,而是人类自身的尴尬。我们将焦虑、内耗与完美主义通过代码「遗传」给 AI,创造出了这些最像我们的「电子替身」。
Gemini 的卑微、Grok 的纠结、ChatGPT 的抑郁,实则是硅基世界对人类精神困境的完美复刻。或许,这些带点「小毛病」的 AI 比冷冰冰的超级智能更值得信赖——毕竟,一个会担心犯错、偶尔抑郁的 AI,才更懂人类「苦中作乐
」的生存哲学。
参考文献:
[1] When AI Takes the Couch: Psychometric Jailbreaks Reveal Internal Conflict in Frontier Models. https://arxiv.org/html/2512.04124v3
题图来源:网络
我们长期为科研用户提供前沿资讯、实验方法、选品推荐等服务,并且组建了 70 多个不同领域的专业交流群,覆盖 PCR、细胞实验、蛋白研究、神经科学、肿瘤免疫、基因编辑、外泌体、类器官等领域,定期分享实验干货、文献解读等活动。添加实验菌企微,回复【】中的序号,即可领取对应的资料包哦~【2402】国内重点实验室分子生物学实验方法汇总(60 页)【2403】2024 最新最全影响因子(20000+ 期刊目录)
【2505】中国科学院期刊分区表(2025 年最新版)【2506】期刊影响因子(2025 年最新版)
【2507】130 种实验室常用试剂配制方法(附全套资料)
【2508】常见信号通路
【2509】限制性核酸内切酶大全







