📋 摘要
本文提出 Nexus,一种统一的深度学习模型中间表示。它在传统数据流图基础上扩展了动态形状、异构分布式语义和结构化控制流,借鉴编译器 IR(特别是 libfirm)的设计思想,将数据流、控制流、通信原语和形状信息融合为一张单一图,具备最高表达能力——任何可计算模型均可无损映射至此表示。通过轻量级装饰器 @nexus.script,开发者可将普通 Python 函数转换为这种静态图,并利用其丰富的语义进行优化和部署。
📑 目录
- 3. ⚡ 快速上手:从 Python 函数到统一图
1. 🔍 引言
随着深度学习模型日益复杂,从简单的 CNN/RNN 到融合动态控制流、异构计算和分布式执行的超大模型,传统基于静态数据流图的中间表示逐渐显得力不从心。现有框架往往通过多种 IR(如 HLO、MLIR、TorchScript)组合或引入特殊算子来弥补不足,但缺乏一种统一且表达能力完备的表示。本文提出 Nexus,一种基于计算图但大幅扩展的表示方法,借鉴编译器 IR 的设计思想(尤其是 libfirm 的图结构),将数据流、控制流、动态形状、异构/分布式通信融合为一张单一图。我们引入轻量级装饰器 @nexus.script,使开发者能直观地编写带控制流的 Python 函数,并将其自动转换为这种扩展图,从而无缝利用其强大表达能力。
2. ⚠️ 传统计算图的局限
经典数据流图由算子节点和张量边构成,每个算子输入输出数量固定,形状静态已知。这种表示在以下场景中捉襟见肘:
- • 输出形状不固定的算子:如 NMS(非极大值抑制),输出边界框数量随输入变化,无法静态确定输出 shape。应用场景:目标检测后处理、动态 beam search。
- • 动态形状:输入维度中包含符号变量(如可变 batch size),形状推导需要符号计算。应用场景:处理可变长序列(NLP)、动态 batch 的推理服务。
- • 异构与分布式:跨设备/机器执行需插入显式的内存拷贝(
memcpy)或通信原语(send/recv/allreduce),传统图缺乏这些节点的标准化表达。应用场景:多 GPU 训练、多机分布式训练、异构计算(CPU+GPU+NPU)。 - • 控制流:条件分支、循环(如 RNN 的时间步展开或
while_loop)需要图外控制逻辑,破坏了图的纯粹性。应用场景:循环神经网络、自适应计算、动态网络结构。 - • 状态与流式模型:RNN 中的循环状态、流式推理中的持久化变量,需要跨越迭代的依赖关系,传统图难以自然表达。应用场景:语音识别流式解码、视频流处理。
3. ⚡ 快速上手:从 Python 函数到统一图
我们提供装饰器 @nexus.script,用于将普通的 Python 函数(输入输出均为张量)转换为本文所述的扩展静态图。转换过程类似 torch.script,但生成的图包含显式的控制流节点、Phi 节点和通信原语。
以下是一个简单的例子:对输入向量 x 循环 n 次,每次加上当前迭代索引。
import nexus as nx
@nx.script
def accumulate(x: Tensor, n: int) -> Tensor:
y = x
for i in range(n):
y = y + i
return y
调用 accumulate 时,实际执行的是编译后的静态图。该图内部结构如下:
- • 包含一个循环头基本块,其中有
Phi 节点合并来自循环入口和循环体的 y 和 i。 - • 循环体内部执行
y + i 和 i+1,并通过 Jmp 跳回循环头。
这种表示使得循环的状态传递、迭代控制一目了然,且所有数据计算节点均可并行执行。
4. 🧠 核心设计
我们的表示方法是计算图的超集,在维持数据流图直观性的基础上,引入编译器中成熟的控制流图(CFG)和数据依赖与控制依赖分离的思想,并参考 libfirm 的基于 Block 的图 IR,将所有要素统一为一张图。
4.1 📦 动态形状与非常规输出
- • 符号化形状:张量的维度可以是符号变量(如
N、H、W),支持符号表达式(如 N*2)。形状推导引擎在编译期执行符号约束求解。ONNX 同样通过符号维度(free dimensions)支持动态形状。 - • 形状算子:引入
ShapeOf、DimSize 等算子,将形状信息显式化为图中的值,使依赖于形状的计算(如 reshape、slice)可表达动态性。对于 NMS 等算子,输出形状由另一个算子(如 NumBoxes)给出,消费者通过读取该值决定内存布局。
应用场景:目标检测模型中的 NMS 后处理,输出框数量动态变化;图像分割中的动态尺寸输出;可变长序列的 packing 与 unpacking。
示例:NMS 的扩展图表示
下图展示了 NMS 算子如何与形状算子配合,将动态输出信息显式传递:
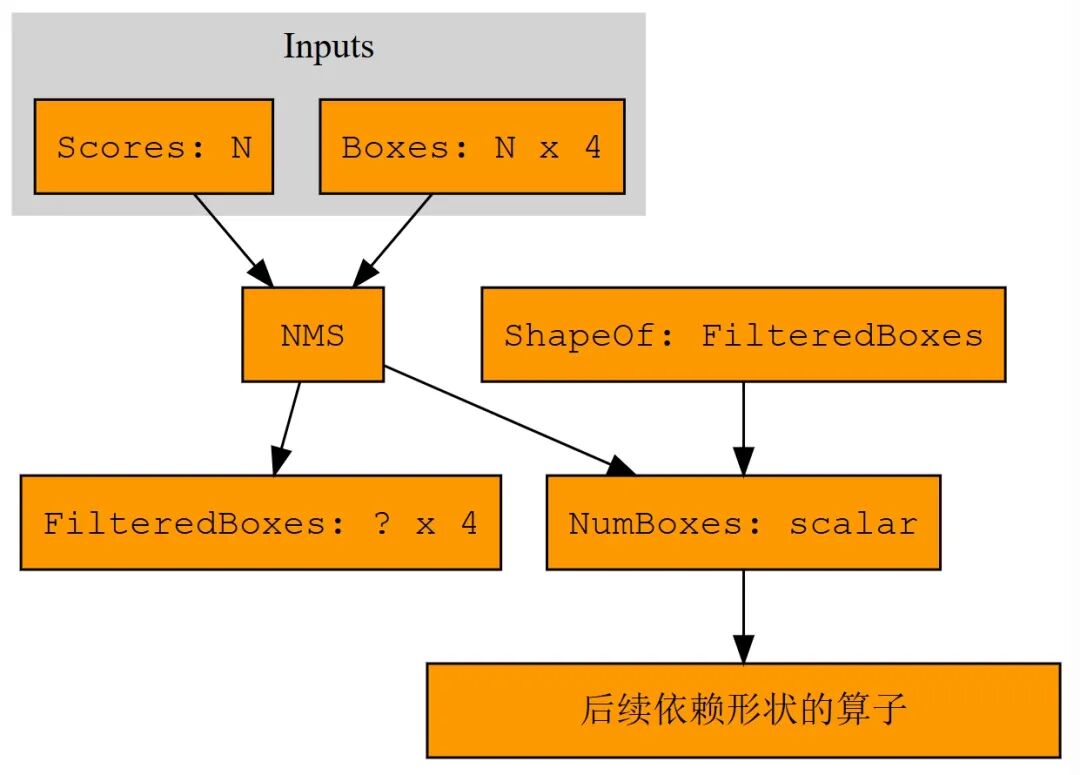
图说明:NMS 节点输出两个值:筛选后的边界框张量(形状未知)和框数量标量。NumBoxes 作为形状信息显式输出,可供下游
Reshape、Slice 等算子使用。ShapeOf 算子也可直接获取张量形状。
4.2 🌐 异构与分布式语义
- • 设备与机器属性:每个张量和算子均可标注
device(如 /GPU:0)和 machine(如 host:192.168.1.10)属性。图构建时,不同设备间的数据传输自动插入 memcpy(同机不同设备)或 send/recv(跨机)节点。 - • 集合通信原语:将
allreduce、allgather、broadcast 等作为一等算子,可直接在图中实例化,支持定义通信组(通过 group 属性)。这些算子的执行语义与普通算子一致,但其内部可能涉及跨节点同步。
应用场景:数据并行训练中梯度同步;模型并行中的张量切分与通信;混合精度训练中的设备间数据转换;CPU 预处理与 GPU 推理的流水线。
示例1:CPU 预处理 + GPU 推理
考虑一个典型的推理流水线:CPU 负责图像解码、resize、归一化等预处理,然后将处理后的张量传输到 GPU 执行模型推理。对应的 DSL 代码如下:
with nexus.device('/CPU:0'):
raw_images = nexus.constant(...) # 原始图像数据
resized = nexus.image.resize(raw_images, [224, 224])
normalized = nexus.cast(resized, nexus.float32) / 255.0
with nexus.device('/GPU:0'):
model = nexus.keras.applications.ResNet50(weights='imagenet')
logits = model(normalized)
predictions = nexus.argmax(logits, axis=1)
对应的扩展图如下:
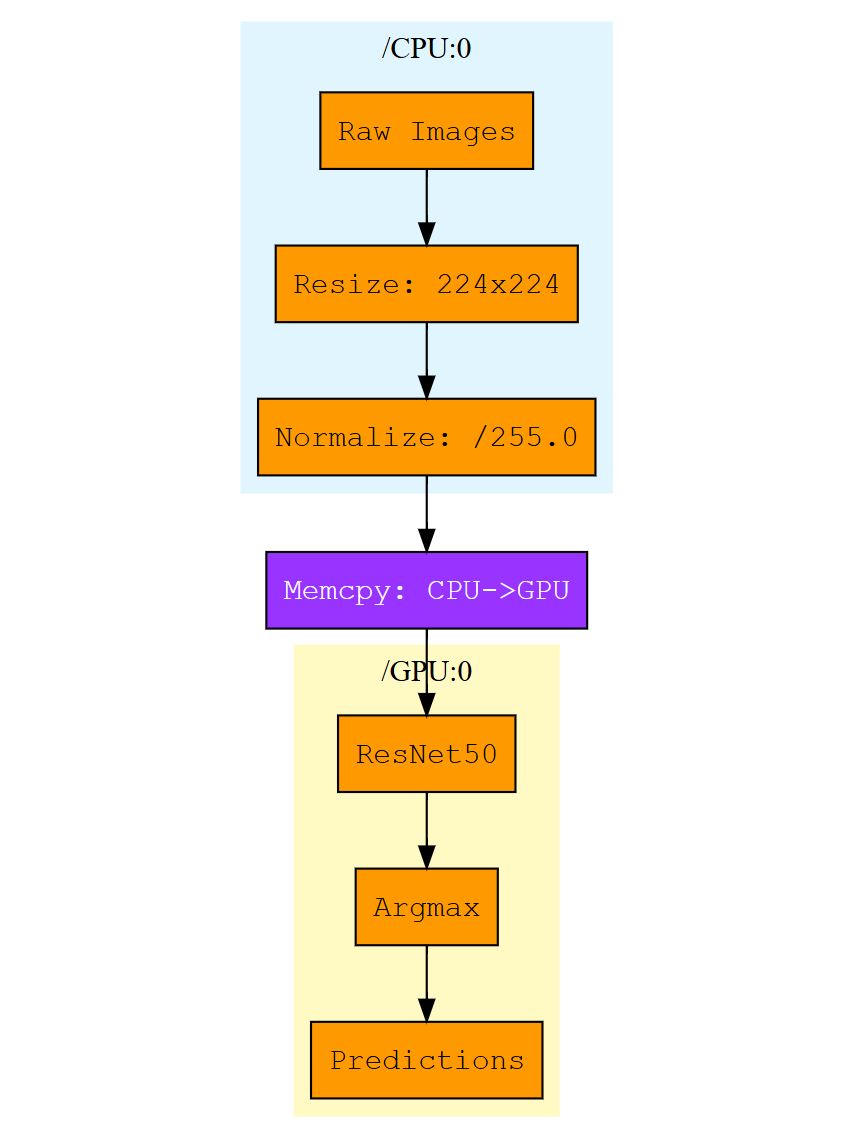
图说明:Memcpy 节点作为显式的数据传输算子,连接 CPU 和 GPU 上的计算。所有算子均带有 device 属性,确保在正确设备上执行。
示例2:数据并行分布式训练
下图展示了一个跨两台机器、每台两个 GPU 的数据并行训练过程,其中 AllReduce 作为一等算子显式出现在图中:
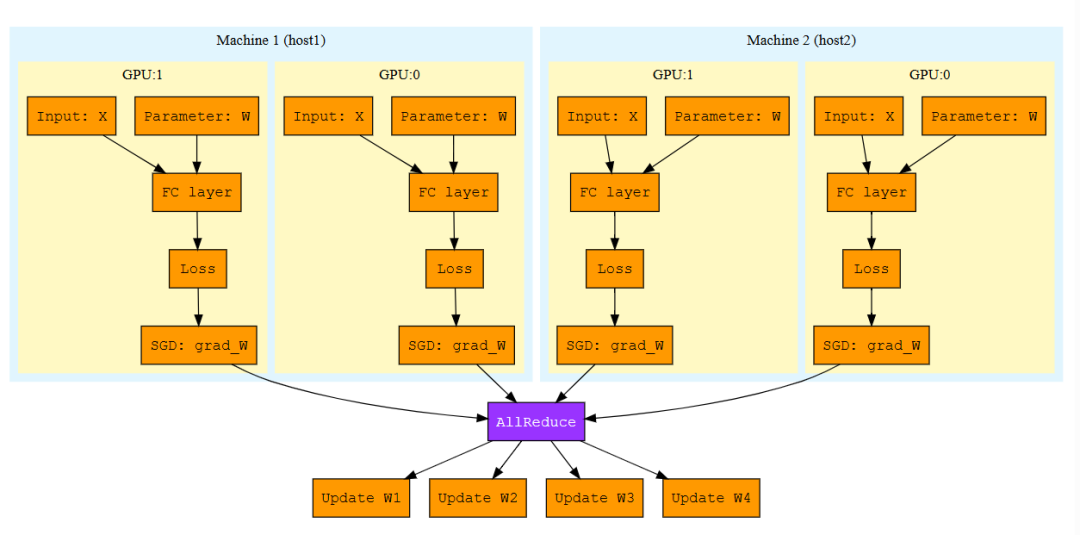
图说明:AllReduce 节点作为一等算子,接收来自所有 GPU 的梯度,聚合后将结果广播回每个 GPU 用于参数更新。每个算子和张量均带有 device/machine 属性,跨设备的数据流自动触发 memcpy,跨机器的 AllReduce 通信由底层运行时映射到 NCCL 或 MPI 原语。
4.3 🎛️ 控制流作为一等公民
ONNX 通过 If 和 Loop 算子实现控制流:If 算子根据布尔条件选择执行 "then_branch" 或 "else_branch" 子图;Loop 算子实现基于迭代次数或动态条件终止的循环执行。这种设计将控制流封装为特殊算子,子图作为算子的属性嵌入。
我们的方案更进一步,在图中显式引入控制流节点和Block,将数据流图与控制流图融合:
- • Block:表示基本块,是代码执行的基本单元。每个 Block 包含一组顺序执行的算子(数据流节点),并以一个控制流节点(如
Branch、LoopCond、Return)结尾,决定后续执行的 Block。 - • 控制依赖边:除数据边外,图中存在从控制节点到 Block 的有向边,表示控制流走向。算子之间也可有纯粹的控制依赖(如确保顺序执行),用虚线边表示。
- • Phi 节点:借鉴 SSA 形式,在 Block 入口处使用
Phi 算子合并来自不同前驱的值,自然表达循环状态更新。 - • Proj 节点:用于从条件节点投影出不同分支的执行路径,通常与
Cond 节点配合使用。
应用场景:RNN/LSTM 中的时间步循环;Transformer 中的动态解码长度;自适应计算中的提前退出;有状态模型的迭代更新。
示例1:简单条件分支
考虑以下 DSL 代码:
a = nexus.constant(1.0)
b = nexus.constant(2.0)
if nexus.less(a, b):
c = nexus.add(a, b)
else:
c = nexus.subtract(a, b)
d = nexus.multiply(c, 2.0)
其对应的扩展计算图如下:
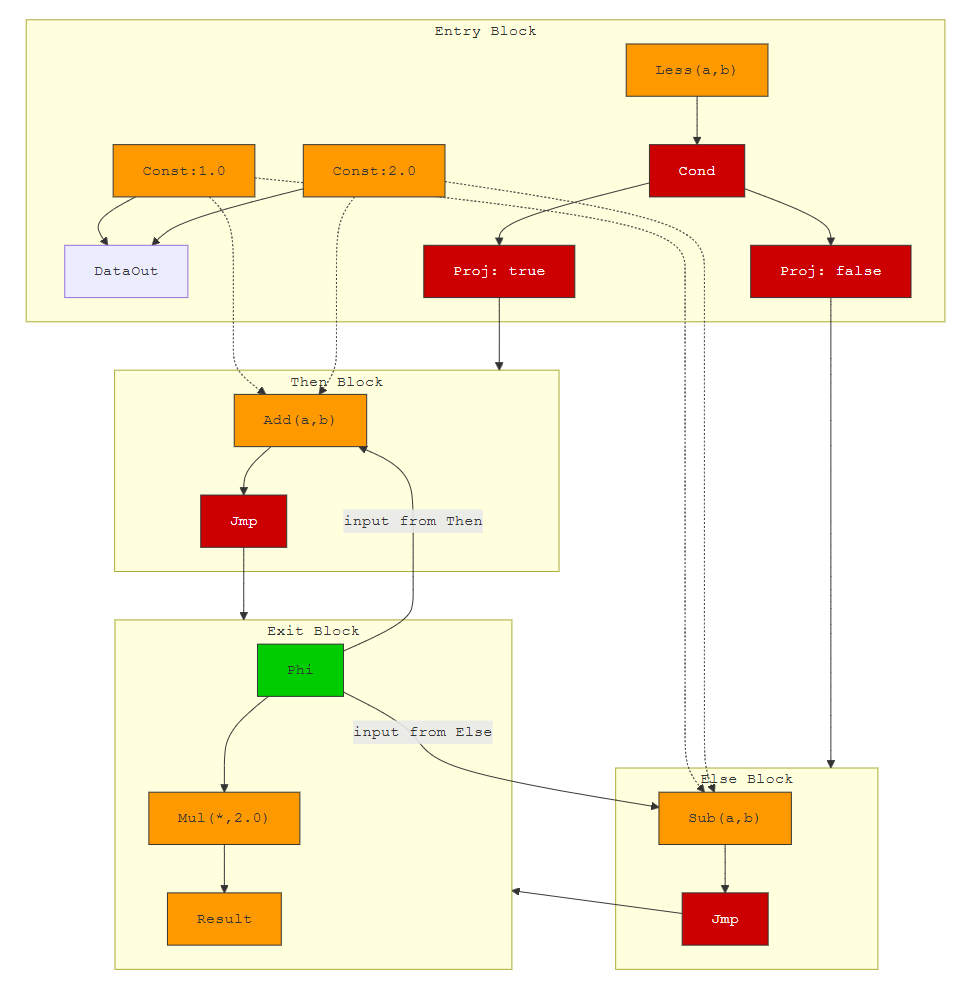
图说明:橙色节点为数据流算子,红色节点为控制流算子,绿色节点为 Phi。数据依赖边为黑色实线,控制依赖边为红色实线(此处简化)。每个基本块内数据流节点可并行执行,控制流节点决定后继块。Phi 节点在 Exit 块入口合并来自 Then 和 Else 的 c 值。
示例2:包含 continue/break 的循环
考虑一个累加计算,从1加到10,但跳过5,且和超过25时提前退出。DSL 代码如下:
sum = nexus.constant(0)
i = nexus.constant(1)
while i <= 10:
if i == 5:
i = i + 1
continue
sum = sum + i
i = i + 1
if sum > 25:
break
result = sum
其扩展计算图如下(简化表示关键结构):
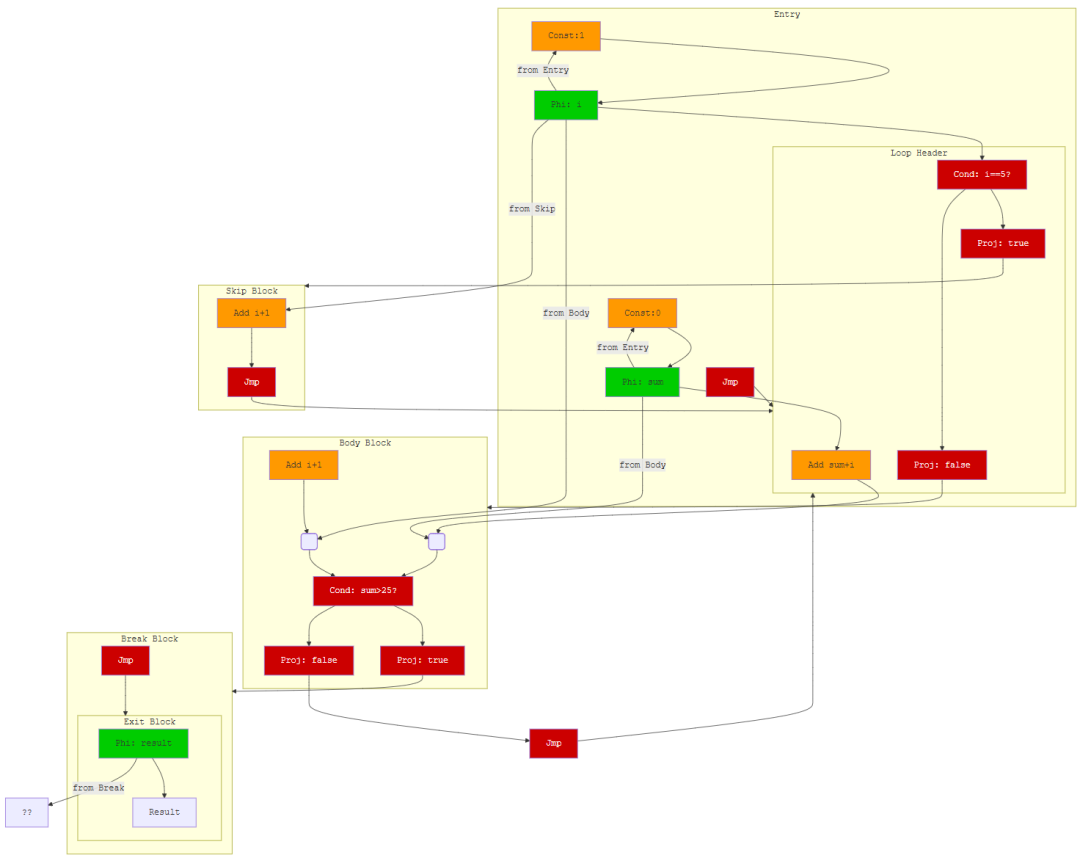
图说明:循环头(Header)包含 Phi 节点,合并来自 Entry、Body 和 Skip 块的循环变量。条件判断节点(CondSkip、CondBreak)产生投影分支,分别对应跳过(continue)、正常迭代和退出(break)。Jmp 节点实现跳转。此图完整表达了循环、条件跳过和提前退出的控制流,且所有数据计算节点均在各自基本块内,可并行执行。
示例3:RNN 循环
考虑一个简单的 RNN 单元,每个时间步计算 h_t = tanh(W·x_t + U·h_{t-1}),执行 T 步。DSL 代码如下:
def rnn_cell(x, h, W, U):
return nexus.tanh(nexus.matmul(W, x) + nexus.matmul(U, h))
@nexus.script
def rnn(x_sequence: Tensor, h0: Tensor, W: Tensor, U: Tensor, T: int) -> Tensor:
h = h0
t = 0
while t < T:
x_t = x_sequence[t] # 假设 x_sequence 形状为 [T, D]
h = rnn_cell(x_t, h, W, U)
t = t + 1
return h
其扩展图结构如下(简化):
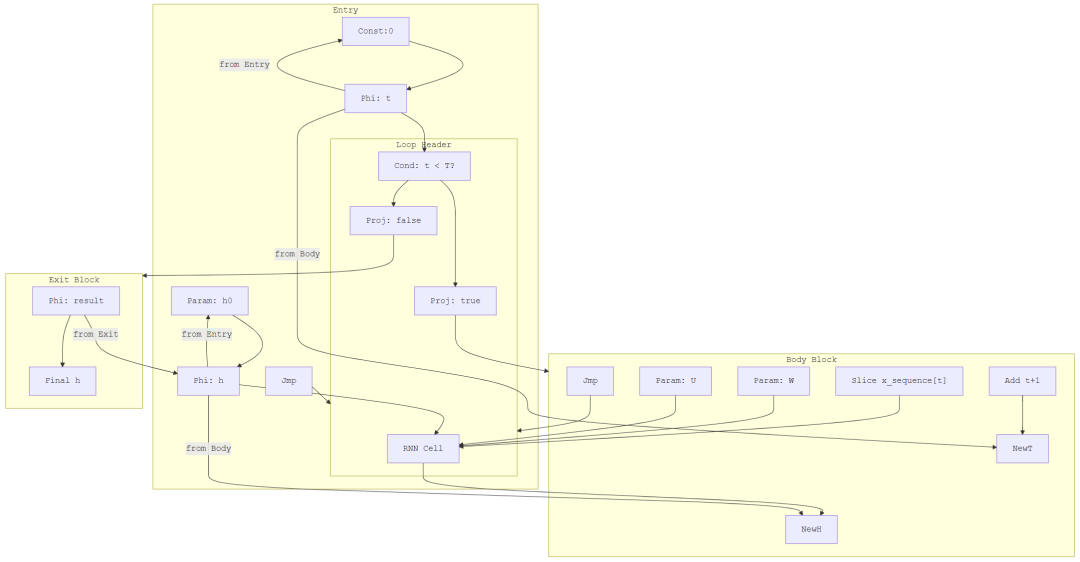
图说明:循环头包含 Phi 节点维护 h 和 t。每次迭代从输入序列中切片得到 x_t,调用 RNN cell 计算新 h,然后增加 t 并跳回循环头。当 t >= T 时,退出循环,最终 h 通过 Phi 节点输出。此图完整表达了 RNN 的时间循环和状态更新。
4.4 🔗 融合数据流与控制流的图结构
最终表示是一个有向图,节点类型包括:
- • 数据算子:加减乘除、MatMul、Conv、Relu、NMS 等。
- • 控制流算子:
Start(入口)、End(出口)、Cond(条件分支)、Merge(多路汇合)、Loop(循环头)、Return、Jmp、Proj 等。 - • 通信算子:
Send、Recv、AllReduce、Memcpy。 - • 元算子:
Constant、Parameter、ShapeOf 等。
每条边可携带属性,如数据边的张量形状、设备位置;控制边仅表示顺序约束。Block 节点聚合一组算子,其输入为控制依赖,输出为跳转目标。
这种结构直接源于 libfirm 的**“图即代码”**哲学:整个程序是一张图,图由节点和边构成,节点包括数据算子、控制流算子、Phi 等,边包括数据边和控制边。Block 将节点分组,但本身也是节点的一种。
5. ⚙️ 执行模型概述
扩展计算图的执行需要一个基于基本块的解释器,它维护当前块、值表等状态。执行流程如下:
- • 处理 Phi 节点:根据前驱块选择合适的输入值。
- • 执行数据流节点:对块内无依赖的节点进行拓扑排序,分组并行执行。
- • 执行控制流节点:根据 Cond、Jmp 等节点决定下一个块。
3. 块间跳转:重复步骤2直到到达 Exit 块。这种执行模型既保留了数据流的并行性,又通过基本块实现了控制流的顺序语义。
6. 📊 与 ONNX 的对比
ONNX 作为当前最广泛使用的模型交换格式,提供了跨框架的中间表示。ONNX Runtime 通过执行提供者(Execution Provider)机制支持异构计算:将模型图划分为子图,每个子图分配给不同的执行提供者(如 CPU、CUDA、TensorRT),在子图边界处进行数据转换。控制流通过 If 和 Loop 算子实现,子图作为算子的属性嵌入。
下表对比 ONNX 与本文方案的关键差异:
| 特性维度 | ONNX | Nexus 统
一表示 |
|---|
表达能
力完备性
| | |
异构计
算表达 | | 图构建时
显式标注
device/
machine
属性,通
信节点显
式插入 |
分布式
通信原语
| | AllReduce |
动态形
状支持 | | |
控制流
融合度 | | Block 结
构,控制流
节点和数
据流节点在
同一层级,
支持任意嵌
套 |
状态表
达 | | |
优化统
一性 | | 统一图上
的数据流+
控制流分析
,优化规则
同时作用于
两者 |
7. 💡 实践价值
这种统一表示可作为深度学习框架的终极 IR,位于前端(如 PyTorch、TensorFlow)和后端(如 LLVM、GPU kernel)之间。它能够:
- • 一站式优化:跨设备通信、形状推导、控制流简化在同一 IR 中执行。
- • 硬件无关性:可附加设备属性,由后端将通信算子映射到具体硬件指令(如 NCCL、MPI)。
- • 动态模型支持:动态 shape 和 NMS 等算子无需特殊对待,只需形状算子配合。
- • 流式部署:模型可编译为状态机,状态由 Phi 节点维持,便于增量推理。
8. 🏁 结语
本文提出了一种统一的、具有最高表达能力的深度学习模型表示方法 Nexus,通过融合数据流图与控制流图,引入动态形状、异构通信原语,并借鉴 libfirm 的 Block 结构,将传统计算图扩展到能够描述任意复杂模型。通过轻量级装饰器 @nexus.script,开发者可以直观地编写带控制流的 Python 函数,并自动获得这种强大表示。与 ONNX 等现有标准相比,Nexus 在表达能力完备性、异构分布式原生支持和控制流融合度方面具有显著优势。它为下一代深度学习编译器和运行时系统提供了坚实的基础,使我们能够更自由地设计、优化和部署未来更智能的模型。








