在前一篇 《Harness Engineering:为 AI 打造可持续迭代环境的实践》 中,我们讲了 HelixVerify 如何在线下环境用 114 次迭代 把风险样本召回率从 8% 提升到 98.86%。那是一个典型的 线下 Harness。这一篇讲 Harness 思想搬到 C 端 AIGC 生产链路后的形态 —— 蚂蚁保保险快查深度解读页面生成系统(Deep Interpretation Page Generator,以下简称 DIPG)。
DIPG 不让 C 端用户直接吃 LLM 实时生成的结果,而是把架构翻转成 "host-generate-verify-modify → DB 按品开启 → C 端直出" 。离线生成由一个带 verify 闭环的 Agentic Loop 负责,只有通过 verify 的 HTML 才会刷入 DB 并暴露给用户。实时生成只保留作为未开启品的兜底路径。即通过 Harness 的方式让 对 C 端交付的HTML 有足够好的质量。

最开始当然试过用户点开详情页时调 LLM 实时生成 HTML 直出。不过问题也很明显:
时延扛不住:一次完整的深度解读需要 agentic 检索素材与条款、 生成几千字 HTML,LLM 推理加起来几十秒。C 端用户等不起,"秒出"是基础体验要求。
质量扛不住:LLM 生成 HTML 会出两类错 —— 渲染类错误(孤儿闭合标签、组件层级错乱)让页面直接塌掉;幻觉类错误(数据不符、编造对比)让用户读到错信息。LLM 一次过做不到 100% 正确,直出就是赌。
C 端 AIGC 交付的本质要求是:用户点开那一刻看到的 HTML,必须是已经被校验过的。所以 DIPG 把实时生成降为兜底、把离线 Harness 的生产过程作为主路径。这篇文章就讲这个离线 verify 闭环在工程上怎么搭。
DIPG 对外的产品形态:用户在支付宝保险快查里打开某款产品的详情页,页面中相应模块会出现一个"深度解读"模块 —— 那里渲染的就是 DIPG 产出的 HTML 片段(750 宽度移动端容器)。前端向后端带着 prodNo 发请求,后端返回 HTML 片段。
在线上生产环境里,这个系统同时跑着两条链路 —— 离线链路是主路径,负责交付质量;实时链路是兜底:
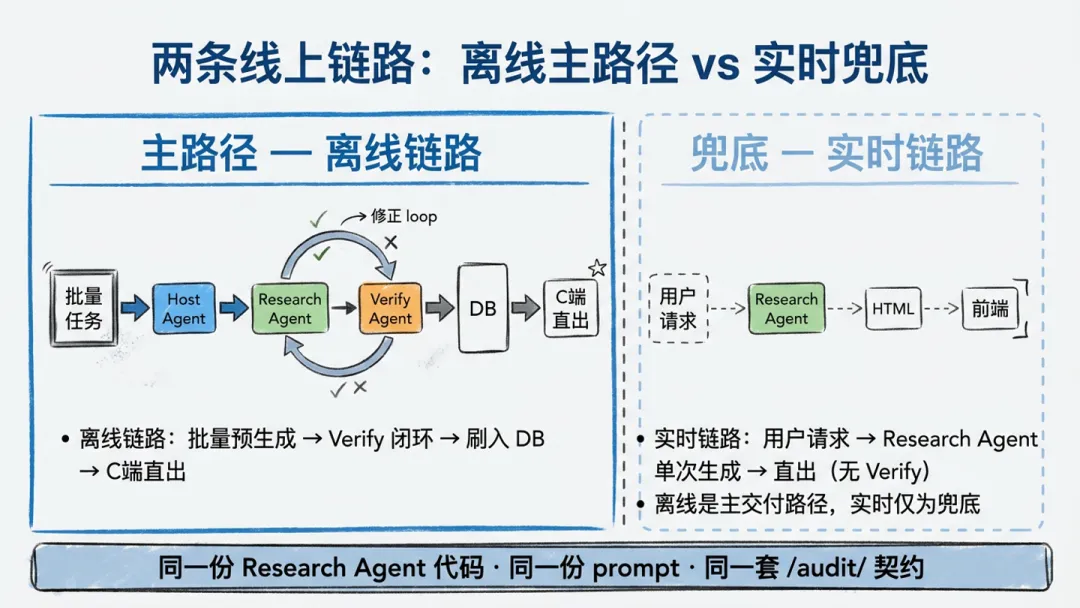
两条链路的 Research Agent 完全同源 —— 离线链路在它之上套了一层 Host Agent(负责调度 Research/Verify、并自己按 verify 反馈 patch HTML);实时链路只跑一次 Research Agent,Host 和 Verify 都不参与,产出的 HTML 不经过后置校验也不会被修正。
用户读的都是离线产物。DIPG 当前采用"离线刷入 DB + 按品维度开启"的方案:后台批量预生成并刷入 DB,只对"已开启的品"向 C 端暴露 —— 用户请求时直接从 DB 读离线产物,命中率 100%,不依赖缓存层兜底(线上还会叠加缓存做进一步加速,但那是性能优化,不是可用性前提)。实时链路仅作为未开启品的兜底生成通道存在,默认情况下 C 端看到的永远是离线产物。
离线链路--质量可控。如果实时生成能 100% 不出错,我们根本不需要离线。离线的核心价值是:把 verify 闭环的修正机会还回来,让 Harness 有施展空间。
"合格 HTML 送达用户:DIPG 的外层 Graph 末端有一个
callback 节点,它把 HTML + verify 结论 + error_code 一起通过 RPC 回调发给下游(insexpert 的 deepResearchCallBack);下游根据 error_code 决定是否把这份 HTML 刷入 DB(通过 verify 的才刷)。
离线链路的"带 verify 闭环"不是一个魔法盒子 —— 它内部由三个分工明确的 Agent 协作完成。这是后面所有工程讨论的概念起点:
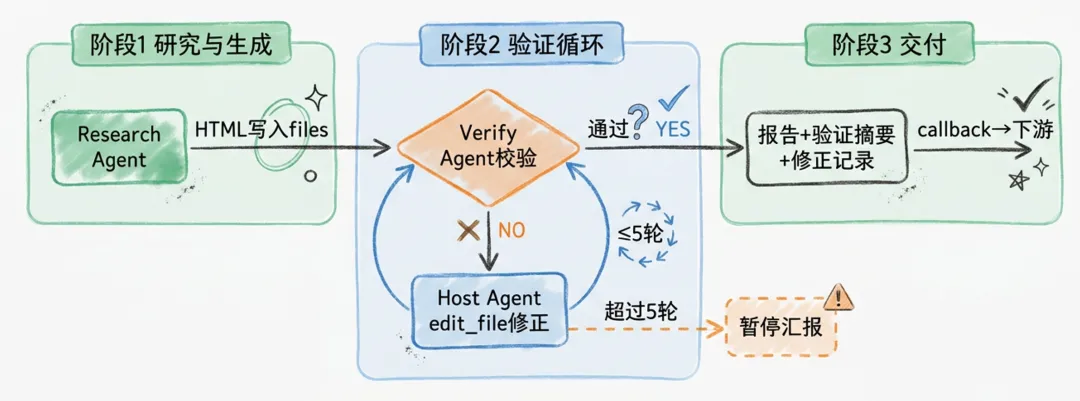
Host Agent —— 总编排 + 精准修正。它读到用户请求后,按"研究 → 校验 → (若未通过)修正 → 再校验"的流程派活。当 Verify Agent 返回修正意见时,Host Agent 自己在已有 HTML 上做精准编辑 (按 fix_hint 定位段落、patch 掉问题点),而不是再派一次 Research Agent 去重新生成 —— 这是 DIPG 的一个关键设计,下面 5.4 节展开。
Research Agent —— 只负责从零生成。它拿到产品编号后下载素材、多轮读取条款、必要时搜网络,最后产出整份 HTML 片段。它不参与修正循环 —— 修正不是它的工作,Host Agent 不会拿"按修正意见改一下"这种请求去派它。它内部也是一个完整的 ReAct Agent,有自己的工具链(第三节 3.4 展开)。
Verify Agent —— 只负责校验、不改 HTML。它读 HTML 产物 + Research Agent 用过的原始素材,做"程序化结构校验 + LLM 事实校验"两层检查,产出结构化的修正意见(fix_hint 列表)交给 Host Agent(第五节 5.2 展开)。
三个 Agent 都是 LangGraph 意义上的独立子图,Host Agent 通过
task 工具异步调用另两个。LangGraph 在物理层面是三层嵌套(外层 Graph / 中层 Host / 内层两个 SubAgent),在逻辑层面就是这个三角分工。
在讲两条链路怎么协作之前,先看一个真实出过问题的页面。
某天巡检到一份重疾险深度解读报告在 C 端偶发渲染错位 —— 最后一个"风险提示"卡片下,下一个无关模块被挤歪了。翻开 HTML 的最后几行:
... <div text-card class="desc">重大疾病赔付后合同终止,轻症赔付后该项责任终止...div> div>div>div> ← 第 201 行: 多出来的孤儿闭合标签
问题很隐蔽。整份报告的顶层本来是平铺结构(
。但 LLM 凭"印象"在末尾补了一个
当作收尾。这个孤儿闭合标签进到移动端容器,被容器当成关闭自身的信号,导致下一个兄弟组件的位置错乱。
同一时期,另一份惠民保产品的深度解读出了更隐蔽的问题。页面渲染完全正常,视觉上看不出任何毛病,但"特色保障分析"模块里赫然写着:
<div class="title" highlight-card>优于市场<span class="title-highlight" highlight-card>85%span>同类惠民保产品div>
"85%"这个数字从哪来的?翻遍 Research Agent 拉到的全部素材 —— 保险条款、投保须知、健康告知 —— 没有任何关于"市场排名"或"百分位"的数据。这是一个典型的幻觉:LLM 为了让页面更有说服力,凭空编造了一个具体数字。
如果说孤儿







