银河通用多项首创技术突破,引领具身智能迈向通用未来。 编辑丨李希

![]()
近日,银河通用创始人兼首席技术官、北京大学研究员王鹤博士在 2026 年北京智源大会“具身智能与人形机器人”专题论坛上,首次指出人形机器人的“AlphaGo”及“ChatGPT”时刻已经到来。
王鹤博士发表了题为《推动人形机器人的“AlphaGo”及“ChatGPT”时刻》的演讲,系统性阐述了银河通用取得的全球首创性突破,并清晰展示了其基座大模型“银河星脑(
AstraBrain)”的完整技术脉络。他认为,数字 AI 从“AlphaGo”到 “ChatGPT” 的演进路径为具身智能提供了清晰参照:先在一个复杂任务上超越人类,再通过规模化走向通用。

在“专”的层面,银河通用实现了两项全球首创性突破:一是全球首个面向网球对抗的人形机器人全身实时智能规控系统,实现完全自主的机器人打网球,一经发布后引发特斯拉 CEO 埃隆·马斯克、Andrej Karpathy等全球顶尖 AI 专家的高度关注;二是以春晚“盘核桃”为代表的灵巧操作能力,银河通用提出的灵巧手神经动力学模型(DexNDM)全球唯一实现了灵巧手“转笔”从仿真到真实部署。
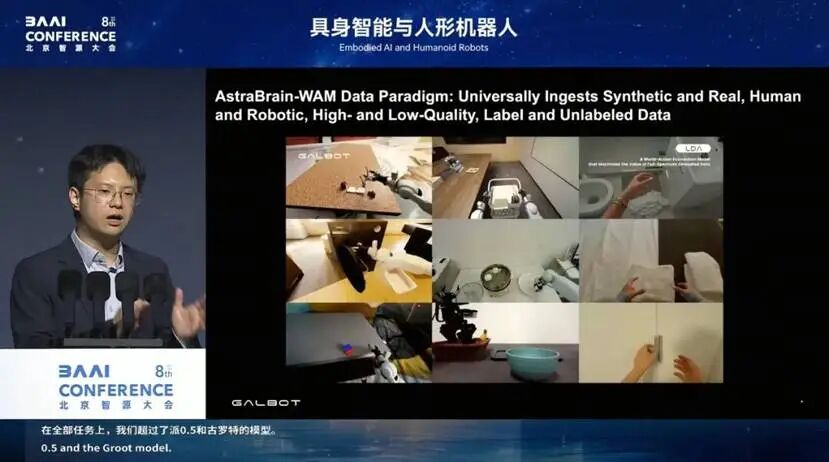
在“通”的层面,银河通用自主研发的“银河星脑(AstraBrain)”是全球首个集成“大脑-小脑-神经控制”于一模的端到端具身大模型。其核心技术路线“世界-动作模型”(WAM)由银河通用团队于2025 年在计算机视觉顶会 ICCV 上首次提出,如今已成为具身智能领域公认的下一代技术方向。在此基础上,银河通用发布了通用大脑 AstraBrain WAM 0.5,全球首次实现虚实共融、人机混合、质量参差、有无动作标签的数据统一有效利用;通用小脑 AstraBrain-WBC 0.5 则在全身闭环控制与实时指令跟随方面世界领先。
从“ AlphaGo” 时刻到 “ChatGPT” 时刻,数字 AI 用十年走完了从专到通的路。当“银河星脑”驱动机器人在真实场景中自主思考与操作,具身智能的“通用时刻”正加速到来。作为这一进程的先行者与引领者,银河通用正在定义人形机器人从“专”到“通”的技术路线,更以完整的全栈自研能力引领具身智能迈向真正的“通用”未来。
下文为王鹤博士演讲原文(部分表述做出不修改原意的编辑):
王鹤:今天在座的很多来宾,真正关心的是人形机器人究竟什么时候能形成生产力、进入千行百业。
这背后的核心技术问题,其实是如何实现通用机器人。所谓通用机器人,是指它像人一样拥有一个能无缝融入人类社会的身体,同时像人一样既有大脑、又有小脑结构的,由具身智能驱动的机器人。

我们先来看看,数字世界里的人工智能是如何一步步走向通用的。我相信,这对于理解今天具身智能所处的时刻、以及思考该如何发展具身智能,都有非常重要的意义。
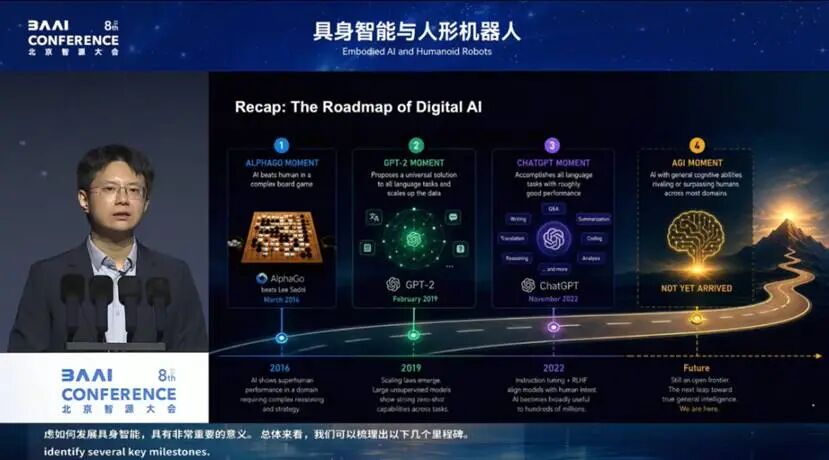
总体来看,可以梳理出几个里程碑:
第一个是 “AlphaGo” 时刻。
智能要先从专走到通,“专”这一步,“AlphaGo” 直接挑战了人类最复杂、最难的棋类游戏——围棋,并在 2016 年首次击败了世界冠军。在 AI 足够专精以后,GPT 系列引领了通用的过程:从 GPT 到 GPT-2 再到 GPT-3,一步步定义了 Scaling-up 的范式,用一个模型完成各种自然语言任务。
直到 2022 年,我们迎来了 “ChatGPT” 时刻,一个能与人自由对话,几乎你跟它说什么,七八成回答都让你满意的模型横空出世。所有 OpenAI 的用户当天就体验到了它的威力。直到今天,这仍然是 GPT 一路走来,大家记忆最深的一个节点。
今天,数字智能正走在通往 AGI
(通用人工智能)的路上,我们还没有抵达,但这条赛道上已经诞生了万亿美金估值的创业公司,涌现出了大量应用。
具身智能在时间线上比数字智能晚了几年。我认为,它要做的第一件事同样是先突破专、精:需要找到一个足够复杂的任务,复杂到能把一个通用人形机器人全身的各种能力都调用出来。一旦突破它,就意味着离走向通用越来越近。那么,什么样的任务值得被定义为具身智能的 “AlphaGo” 时刻?
银河通用选择了打网球。
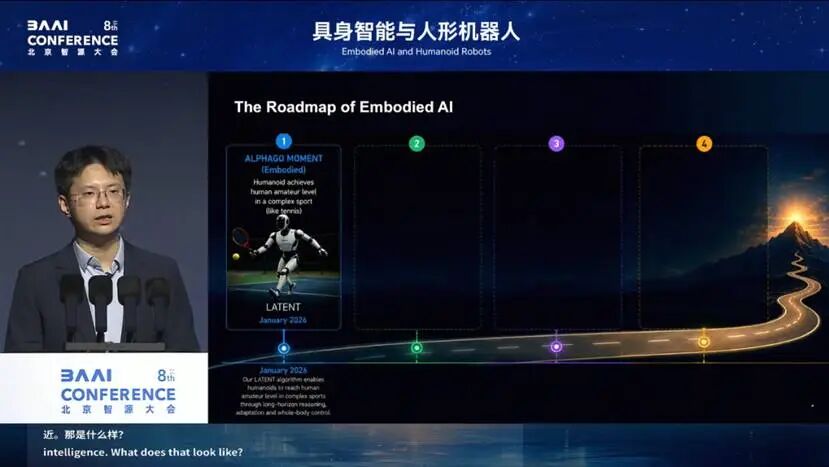
在所有运动场景中,网球是对人形机器人最具挑战性的任务之一。在快速的来回对拉中,机器人必须应对无法预测的落点和不断变化的球路。这是世界上第一次实现、也是目前唯一一例人形机器人全自主打网球,没有任何遥控、没有任何人为介入。机器人在毫秒级别内完成判断,从机械地模仿动作跨越到由智能决策驱动的响应,能够与人持续对拉而不中断。我们看到,网球的高动态性以及它对全身的调动能力,足以让它成为一个足够复杂的球类运动。

事实上,这项工作一经发布到海外视频网站上,Elon Musk 本人立即评论了一句 “insane”。随后陆续有研究者指出,这些都是与我们没有利益关系的客观评论者,评论道:AlphaGo for every sport is coming.(各项运动的“AlphaGo” 时刻都要来了。)过去机器人打乒乓球、做其他运动,大家并没有把它和 “AlphaGo” 联系在一起。
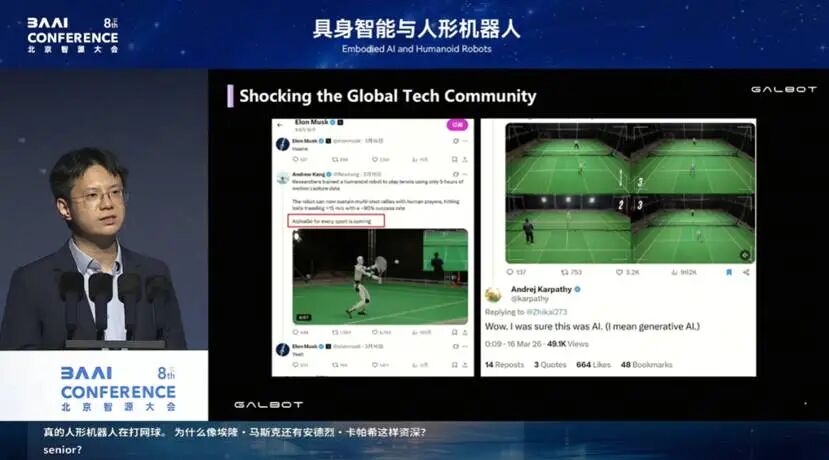
但打网球这件事,让国际技术社区认为,这标志着具身智能的“AlphaGo”时刻即将来临。
不只是 Musk,AI 圈著名研究者 Andrew Kang 也有强烈反应:他第一次看到这个视频时,认为这是视频生成软件做出来的假视频,而不是真的人形机器人在打网球。为什么像 Musk、Kang 这样资深的人工智能乃至具身智能专家,会对打网球有这么大的反应?为什么打网球这么难?
实际上,网球既需要
low-level 的全身控制,尤其是手,如果手腕控制球拍稍有不准,球没有落在球拍中心的甜区(sweet zone),回球就会非常不准。同时,对打时又涉及大量策略(strategy),比如打空当、前后吊球,这些策略又是非常 high-level 的。这样一个任务,同时要求 low-level 和 high-level 精准有效地结合在一起,这正是打网球的突破对人形机器人定义 “AlphaGo” 时刻几乎是决定性的原因。
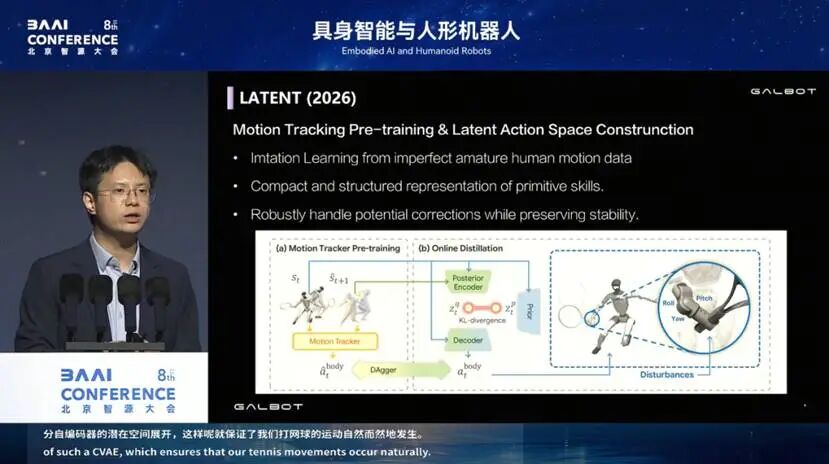
算法上,我们从人类运动员的动作捕捉中获得了大量人类运动的先验分布,把这些先验retarget 到人形机器人上,学习了一个 CVAE 来capture 运动的 motion prior,后续的强化学习就在这个 CVAE 的 latent space 里展开。这样既保证了打网球的动作自然地落在人类运动的分布里,不会做出一些很奇怪的使用球拍的动作,也大大加快了强化学习收敛的速度。

这里还有一个有意思的点:手腕。
我们发现,如果手腕也通过 latent space 来学习,由于重建本身存在不精准,击球会不够准确。因此,手腕的三个自由度是单独建模、直接端到端控制的,如此我们就实现了能与人类连续对打几十拍的网球水平。

这背后离不开银河通用在全域数据运用上的长期发力。
“AlphaGo” 在数字世界下棋和在物理世界下棋是同一个游戏,不存在 Sim-to-Real 的问题。我们的网球是在机器人训练之后,要求它能直接部署到真实世界里与人对打,这中间的
Sim-to-Real gap 非常困难,攻克它也给所有做人形机器人的人极大的信心。
有人会问:你只用到了手腕,那手有没有用上?
今年春晚,我们展示了灵巧手盘核桃的技能。这同样是在仿真器里大量强化学习后,再transfer 到真实世界的。由于灵巧手是典型的 contact-rich 场景,很多人质疑灵巧手的强化学习能不能做 Sim-to-Real。我们通过在仿真器里构建一个较为真实的碰撞模型,让学到的policy 可以直接部署到真实世界,但 performance 只能达到中庸。
在回收大量真实数据之后,我们训练了一个灵巧手神经动力学模型,或者用一个更简单的词汇——灵巧手世界模型,来弥合真实与仿真之间的差距,用这个 DexNDM 回传梯度去更新灵巧手的 policy,从而实现从仿真到真实的高保真迁移。
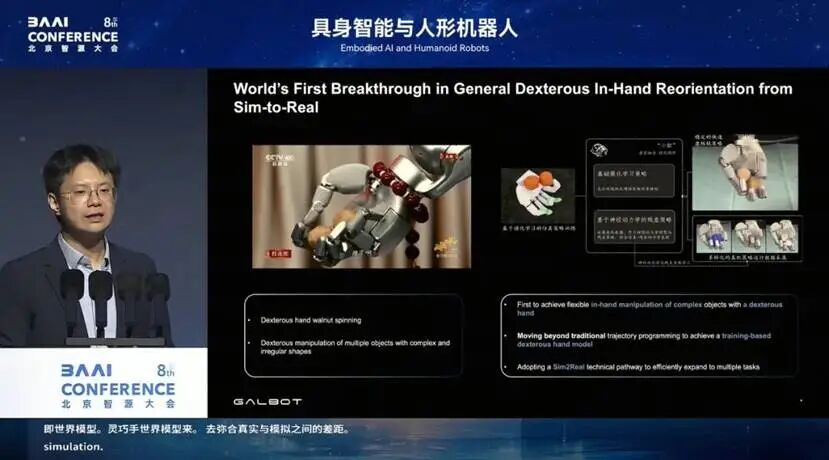
今天的这套 policy(DexNDM)可以操作各种不同的工具、完成各种不同的任务。它是一个通用的灵巧手控制器,手内旋转、手内重定向、物体使用等一般性操作,在 Sim-to-Real 之后都能很好地完成。我们展现的就是一个通用的灵巧手内操作。
有人会问:你和其他灵巧手的 demo 有什么区别?左边是 Figure 开瓶盖,仔细看它的行为,抓住、攥紧、一起拧,再抓住、攥紧、一起拧;换成更细长的螺丝,其实是同一回事,多指之间配合拧螺丝。我们是连贯的动作,它就是抓住、一起拧、松开,为什么?

遥操作时很难采集到多指之间的精细配合,只能抓住、一起攥、松开。这种采集上的天然劣势,导致学出来的 policy 看起来不是最高效、最自然的。而我们用强化学习学出来的技能,和人类一样,最高效、最精准。
左边还有一个例子,是英伟达在仿真器里做的转笔。有人会问:是不是别人都不做仿真器里的强化学习?其实
NVIDIA 早在 2023 年就展示了灵巧手转笔,但这项工作迟迟无法 Sim-to-Real,无法在真实世界里看到灵巧手的操作。而银河通用运用 DexNDM,在全球范围内目前也是唯一实现了真机转笔。

在 ICRA 大会做主旨报告时,我问在座全球的机器人学者:你们有多少人会转笔?很多人其实转不了。所以我问大家,这是不是灵巧手的“AlphaGo时刻”?答案是肯定的。
到这里,我们通过全身、全手的各种挑战性技能,已经在“专、精”上做出了突破。下一步,是如何从“专”走向“通”,如何定义具身智能的 “ChatGPT” 时刻?这需要我们拥有一个像人一样的“大脑”和“小脑”。
银河通用推出的 AstraBrain(银河星脑),目标就是做一个通用人形机器人的基座:既有大脑、又有小脑,中间通过脑桥连接,让更快的小脑与相对较慢的大脑实现异步同步。人脑中的脑桥实际上分为三路、有上传也有下载,我们的架构充分参考了人类大脑的结构,目标就是实现完全通用。
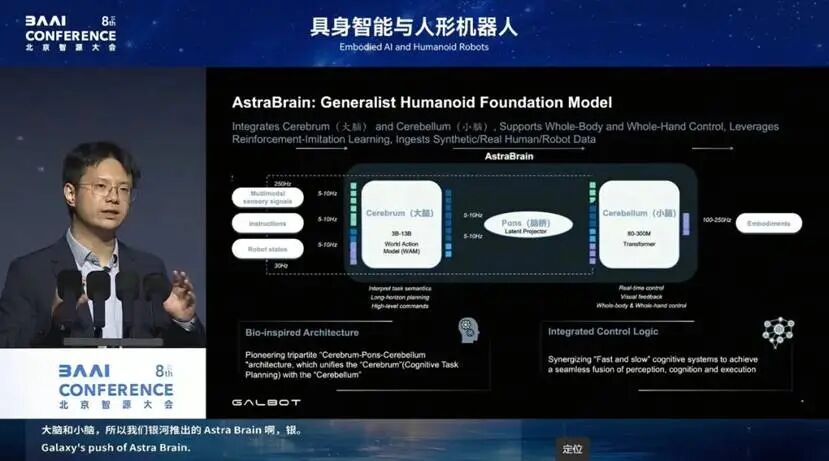
刚才看了很多打网球、灵巧手的内容,我们再来看看这背后的大脑应该是什么样子。
今天的大脑迎来了一个新范式:World Action Model(WAM)。它把 Google 提出的VLA,和 OpenAI Sora 展示出来的 world model 融合在了一起。
这种融合并不只是简单的多任务:因为我们看到 VLA 本质上是预测 action,它的动作监督必须依赖带 action label 的具身数据。而 video generation
不需要 action,完全可以用人类佩戴相机拍下自己干活的纯视频数据来训练,后者拥有更好的 diversity,能 cover 更低的采集成本,更广的任务空间,所以它的学习能够帮助 VLA 扩展到它的任务空间,甚至在生成的 image 里隐含了机器人的手该怎么动,胳膊该怎么伸。
可以认为,前者是一个 explicit 的 action,后者是一种 image representation as action。两者之间有极强的 synergy 作用,且后者真正把无标签视频数据的能量解放了出来,这才是真正能够把具身基础模型 scale-up 的路线。
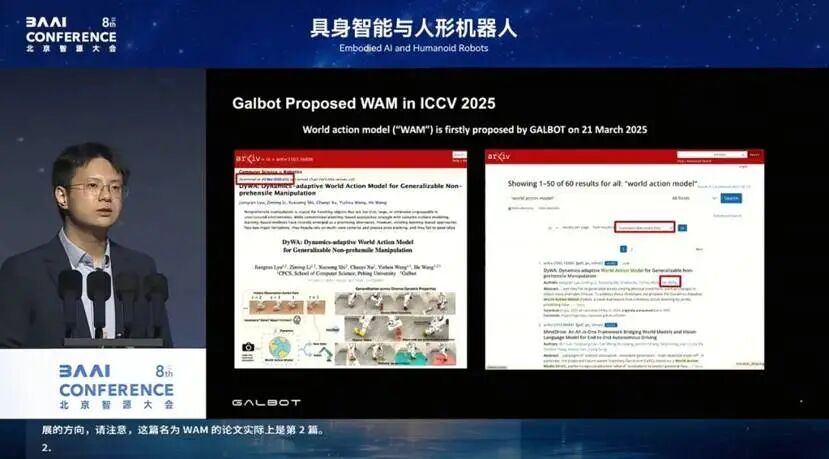
这也是为什么英伟达的 Jim Fan 今年接受采访时说,WAM 是robotics endgame(机器人技术的终局):因为我们终于能让模型吸收各种数据,真正定义一个 scale-up 的方向。

需要说明的是,第一篇名为 WAM 的论文,是我们(银河通用)团队挂到 arXiv 上的。如果今天在 arXiv 上搜索 "world action model" 并按时间排序,第一篇就是我们的成果,2025 年 ICCV 的文章。
随着这个方向得到更多认可,银河通用也在不断迭代。首先是:我们是否要做 RGB 层面的预测。其实人类对未来的预测做不到 pixel-level 的精细度。所以在我们 AstraBrain WAM 的大脑部分 0.5 代际,实际上也是我们 RSS 2026 论文 LDA,第一次提出用 latent space 替代 RGB space 来作为想象的空间。它的分辨率相对更低,把光照、纹理这些不重要的信息尽可能 factorize 掉,转而关注背后的动作和几何本身。我们发现,这样的模型能学得更好,并且能用更少的数据体现出更强的性能。

同时,我们在 2025 年 UW 中提出的 Unified World Model里,除了 VA/VV 两个任务,我们还把前向动力学和逆向动力学这两个任务一起吸收进 WAM 框架,统一了四个任务,并用一个大模型完成了 UWM 没有做的 scaling up。
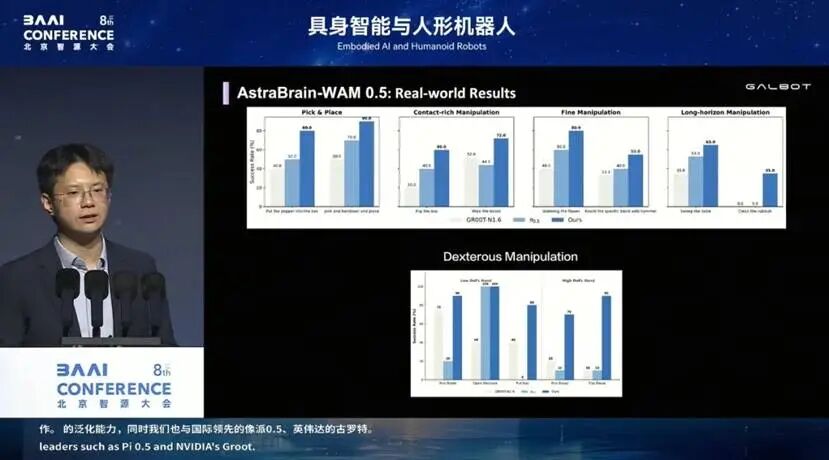
今天,我们的 WAM 0.5 在仿真环境和真实世界里都展现出很好的基座模型性能。举一个做牛排的长程任务的例子:我们让机器人先去抓夹子,再用夹子去夹牛排。本来要夹的是这一片,但我们可以用语言打断它,让它改成抽底下那片牛排、再抽出来。夹出我们想吃的那一片之后,把它放进盘子里、放下夹子,再给它撒胡椒粉。像这样的长程任务,我们用 WAM 0.5 这个模型,经过非常少的真机数据就可以训练完成。

可以看到,今天的 AstraBrain WAM 0.5 具备了多任务能力,覆盖各种各样的任务,也包括跨本体(
cross-embodiment)的能力,无论是灵巧手、二指夹爪,还是其他类型的机器人,我们都能让这个模型做 cross-embodiment 的泛化。同时,我们也和国际领先的模型做了对比,比如 π0.5、NVIDIA 的 Groot N1.6,在全部任务上,我们都超过了 π0.5 和 Groot。
这背后,是我们第一次把合成数据、真实数据、以及 egocentric 数据,大量地全部吸收进同一个模型,这是整个模型性能的基石。
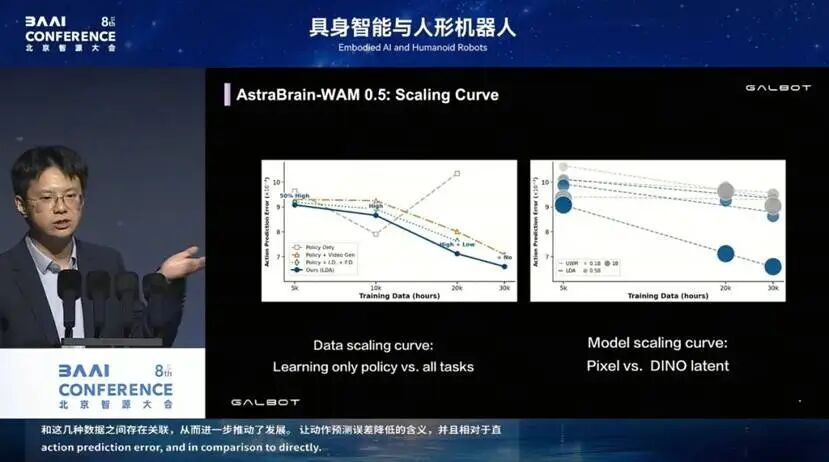
我们的 scaling curve 证明,这几类任务之间、这几种数据之间,都能进一步让 action prediction error 下降。并且对比来看(右图灰线是用RGB 做想象、蓝线是用 latent 做想象),latent方案有更好的 scaling behavior。背后海量的egocentric data,是我们实现scaling curve 的关键。
银河通用团队 2021 年就发布了全球最大的 egocentric 手物交互数据集,当时就定义了由人头戴相机采集自己干活的视频,并配套了一整套人手标注系统,包括手部
hand action label 的提取系统。在 egocentric data 这件事上,银河通用又一次站在了世界最前沿。

看完通用的大脑,我们还需要真正通用的小脑。今天很多跳舞的视频,其实并不是通用的小脑,它只是对一条运动轨迹的追踪,背后只是几层 MLP。
今天真正重要的,是通用的大脑和通用的小脑。所谓通用小脑,是指有一个在上方下达指令的人,可以随时给指令、实时遥控,让小脑负责闭环反馈和执行。这样的小脑,上方给它什么动作,它就应该能执行什么动作。
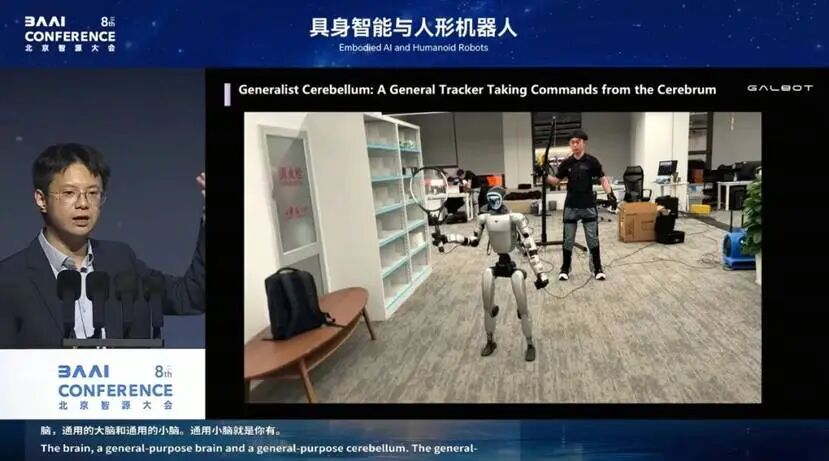
今年,我们的 AstraBrain-WBC 0.5,是基于 CVPR 2026 的工作 HumanoidGPT ,这也全球领先的具身智能通用小脑基座大模型。(编者注:相关工作成果将于近期正式发布,请关注银河通用机器人官方公众号)。
如果 WAM 定义了具身智能的 GPT 范式,那 “ChatGPT” 时刻什么时候出现?
我认为,具身智能在经过预训练之后,要在人类无需专门后训练、无需专门学习就能完成的技能上、zero-shot达到 70% 到 80% 的成功率,这定义了它基模的 capability。
同时还有一个重要指标是 accessibility:这样的技术突破,能不能快速让所有老百姓都感受到,而不是只存在于一家机器人公司内部。当我们的GPT达到 3.5 的水平之后,机器人能不能快速部署?
这里就要讲我们一项具有革命性的技术,WAM-TTT(test-time training),重新定义具身智能后训练新范式。(编者注:相关工作成果将于近期发布,请关注银河通用机器人官方公众号)。
这些工作,真正能把我们的预训练成果快速带到真实世界,并实现长期的、终身的部署。一旦我们突破 ChatGPT 时刻,就会快速向 AGI 发起冲刺。
当我们抵达 AGI 时刻,将迎来第四次工业革命:人形机器人会成为一个有手机的量、汽车的价,并叠加大模型智能的巨大市场,一个数万亿美元的市场。
我相信,在座的同行们会一起为之努力。
谢谢大家。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。







