

作者 | zone7
责编 | 郭芮
最近各大一二线城市的房租都有上涨,究竟整体上涨到什么程度呢?我们也不得而知,于是乎笔者为了一探究竟,便用 Python 爬取了房某下的深圳租房数据。以下是本次的样本数据:
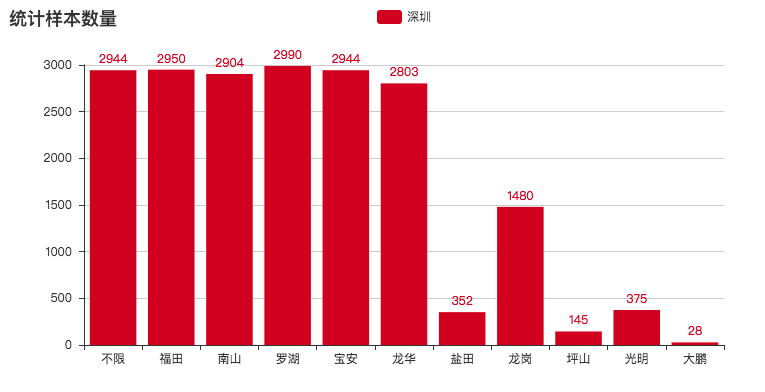
除去【不限】的数据(因为可能会与后面重叠),总数据量为 16971 ,其中后半部分地区数据量偏少,是由于该区房源确实不足。
因此,此次调查也并非非常准确,权且当个娱乐项目,供大家观赏。

统计结果
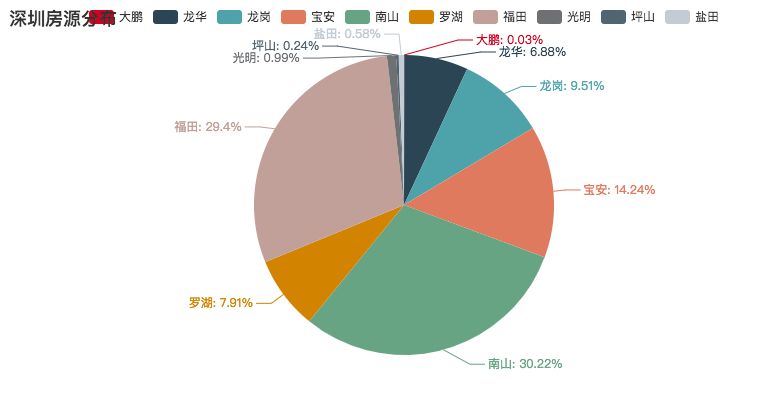
我们且先看统计结果,然后再看技术分析。深圳房源分布如下,按区划分的话,其中福田与南山的房源分布是最多的。但这两块地的房租十分不菲。
房租单价即 1 平方米 1 个月的价格。方块越大,代表价格越高:
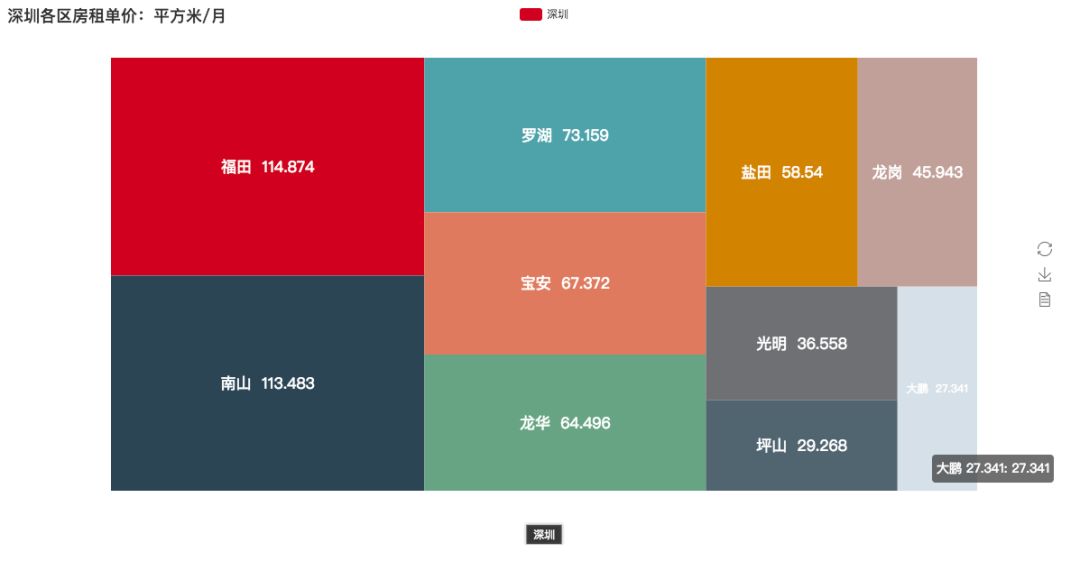
房租单价:平方米/月
可以看出福田与南山独占鳌头,分别是 114.874 与 113.483 ,是其他地区的几倍。如果以福田 20 平方的房间为例算一下每个月的开销:
福田 20 平方房间的租金:
114.874 x 20 = 2297.48
再来个两百的水电、物业:
2297.48 + 200 = 2497.48
我们节俭一点来算的话,每天早餐 10 块,中午 25 块,晚饭 25 块:
2497.48 + 60 x 30 = 4297.48
是的,仅仅是活下来就需要 3997.48 块。隔断时间下个馆子,每个月买些衣服,交通费,谈个女朋友,与女朋友出去逛街,妥妥滴加个 3500:
4297.48 + 3500 = 7697.48
给爸妈一人一千:
7697.48 + 2000 = 9697.48
月薪一万妥妥变成了月光族。
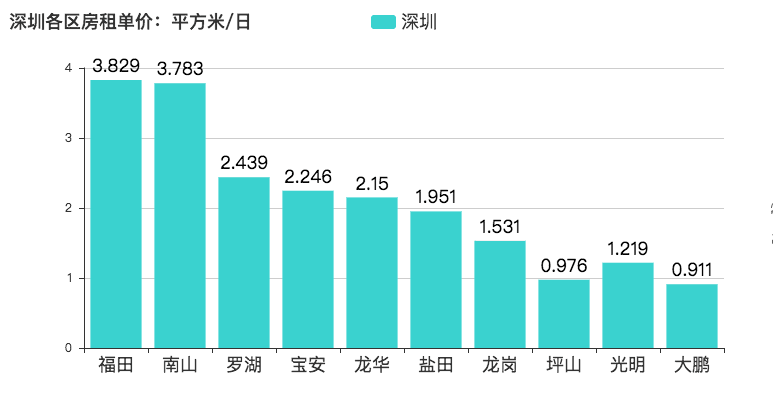
租房单价:平方米/日
如果在乡下没有寸土寸金的感觉,那么可以到北上广深体验一下,福田区每平方米每天需要 3.829 元。
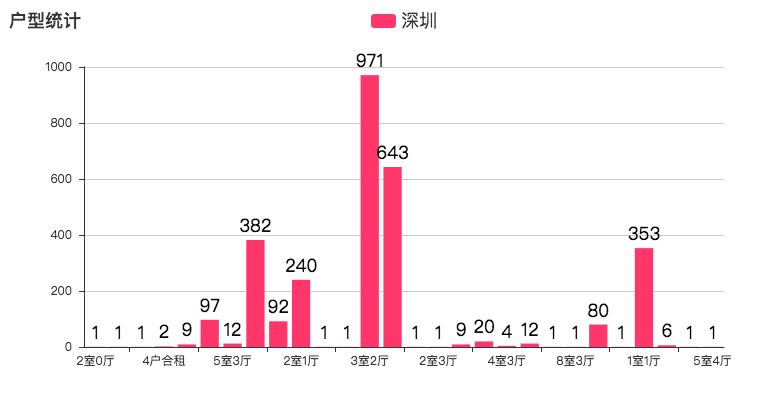
户型方面主要以 3 室 2 厅与 2 室 2 厅为主。与小伙伴抱团租房是最好的选择了,不然与不认识的人一起合租可能会发生一系列让你不舒服的事情。字体越大,代表户型数量越多。

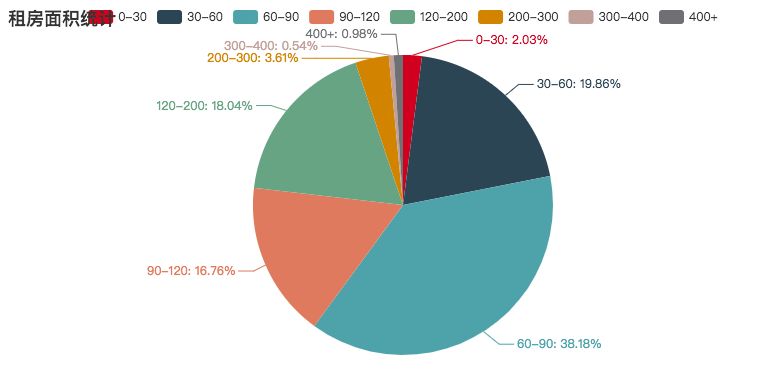
租房面积统计,其中 30 - 90 平方米的租房占大多数——所以,组团租房是最好的选择。
然后是租房描述词云,字体越大,标识出现的次数越多。其中【精装修】占据了很大的部分,说明长租公寓也占领了很大一部分市场。


爬虫思路
先爬取房某下深圳各个板块的数据,然后存进 MongoDB 数据库,最后再进行数据分析。

数据库部分数据:
/* 1 */
{
"_id" : ObjectId("5b827d5e8a4c184e63fb1325"),
"traffic" : "距沙井电子城公交站约567米。",//交通描述
"address" : "宝安-沙井-名豪丽城",//地址
"price" : 3100,//价格
"area" : 110,//面积
"direction" : "朝南\r\n ",//朝向
"title" : "沙井 名豪丽城精装三房 家私齐拎包住 高层朝南随时看房",//标题
"rooms" : "3室2厅",//户型
"region" : "宝安"//地区
}

爬虫技术分析和代码实现
爬虫涉及到的技术工具如下:
请求库:requests
HTML 解析:Beautiful Soup
词云:wordcloud
数据可视化:pyecharts
数据库:MongoDB
数据库连接:PyMongo
首先右键网页,查看页面源码,找出我们要爬取的部分。
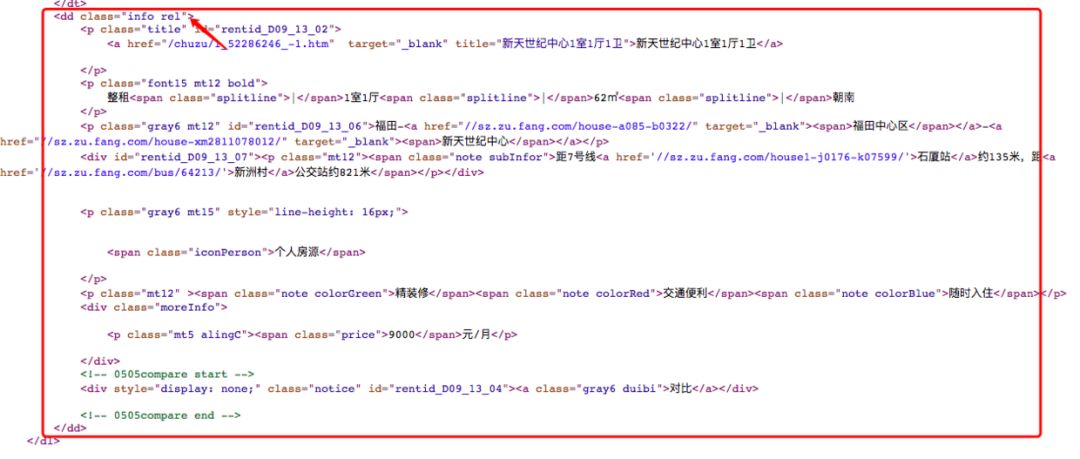
代码实现,由于篇幅原因只展示主要代码:(获取一个页面的数据)
def getOnePageData(self, pageUrl, reginon="不限"):
rent = self.getCollection(self.region)
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'})
res = self.session.get(
pageUrl
)
soup = BeautifulSoup(res.text, "html.parser")
divs = soup.find_all("dd", attrs={"class": "info rel"}) # 获取需要爬取得 div
for div in divs:
ps = div.find_all("p")
try: # 捕获异常,因为页面中有些数据没有被填写完整,或者被插入了一条广告,则会没有相应的标签,所以会报错
for index, p in enumerate(ps): # 从源码中可以看出,每一条 p 标签都有我们想要的信息,故在此遍历 p 标签,
text = p.text.strip()
print(text) # 输出看看是否为我们想要的信息
print("===================================")
# 爬取并存进 MongoDB 数据库
roomMsg = ps[1].text.split("|")
# rentMsg 这样处理是因为有些信息未填写完整,导致对象报空
area = roomMsg[2].strip()[:len(roomMsg[2]) - 2]
rentMsg = self.getRentMsg(
ps[0].text.strip(),
roomMsg[1].strip(),
int(float(area)),
int(ps[len(ps) - 1].text.strip()[:len(ps[len(ps) - 1].text.strip()) - 3]),
ps[2].text.strip(),
ps[3].text.strip(),
ps[2].text.strip()[:2],
roomMsg[3],
)
rent.insert(rentMsg)
except:
continue
数据分析:
# 求一个区的房租单价(平方米/元)
def getAvgPrice(self, region):
areaPinYin = self.getPinyin(region=region)
collection = self.zfdb[areaPinYin]
totalPrice = collection.aggregate([{'$group': {'_id': '$region', 'total_price': {'$sum': '$price'}}}])
totalArea = collection.aggregate([{'$group': {'_id': '$region', 'total_area': {'$sum': '$area'}}}])
totalPrice2 = list(totalPrice)[0]["total_price"]
totalArea2 = list(totalArea)[0]["total_area"]
return totalPrice2 / totalArea2
# 获取各个区 每个月一平方米需要多少钱
def getTotalAvgPrice(self):
totalAvgPriceList = []
totalAvgPriceDirList = []
for index, region in enumerate(self.getAreaList()):
avgPrice = self
.getAvgPrice(region)
totalAvgPriceList.append(round(avgPrice, 3))
totalAvgPriceDirList.append({"value": round(avgPrice, 3), "name": region + " " + str(round(avgPrice, 3))})
return totalAvgPriceDirList
# 获取各个区 每一天一平方米需要多少钱
def getTotalAvgPricePerDay(self):
totalAvgPriceList = []
for index, region in enumerate(self.getAreaList()):
avgPrice = self.getAvgPrice(region)
totalAvgPriceList.append(round(avgPrice / 30, 3))
return (self.getAreaList(), totalAvgPriceList)
# 获取各区统计样本数量
def getAnalycisNum(self):
analycisList = []
for index, region in enumerate(self.getAreaList()):
collection = self.zfdb[self
.pinyinDir[region]]
print(region)
totalNum = collection.aggregate([{'$group': {'_id': '', 'total_num': {'$sum': 1}}}])
totalNum2 = list(totalNum)[0]["total_num"]
analycisList.append(totalNum2)
return (self.getAreaList(), analycisList)
# 获取各个区的房源比重
def getAreaWeight(self):
result = self.zfdb.rent.aggregate([{'$group': {'_id': '$region', 'weight': {'$sum': 1}}}])
areaName = []
areaWeight = []
for item in result:
if item["_id"] in self.getAreaList():
areaWeight.append(item["weight"])
areaName.append(item["_id"])
print(item["_id"
])
print(item["weight"])
# print(type(item))
return (areaName, areaWeight)
# 获取 title 数据,用于构建词云
def getTitle(self):
collection = self.zfdb["rent"]
queryArgs = {}
projectionFields = {'_id': False, 'title': True} # 用字典指定需要的字段
searchRes = collection.find(queryArgs, projection=projectionFields).limit(1000)
content = ''
for result in searchRes:
print(result["title"])
content += result["title"]
return content
# 获取户型数据(例如:3 室 2 厅)
def getRooms(self):
results = self.zfdb.rent.aggregate([{'$group': {'_id': '$rooms'
, 'weight': {'$sum': 1}}}])
roomList = []
weightList = []
for result in results:
roomList.append(result["_id"])
weightList.append(result["weight"])
# print(list(result))
return (roomList, weightList)
# 获取租房面积
def getAcreage(self):
results0_30 = self.zfdb.rent.aggregate([
{'$match': {'area': {'$gt': 0, '$lte': 30}}},
{'$group': {'_id': '', 'count': {'$sum': 1}}}
])
results30_60 = self.zfdb.rent.aggregate([
{'$match'
: {'area': {'$gt': 30, '$lte': 60}}},
{'$group': {'_id': '', 'count': {'$sum': 1}}}
])
results60_90 = self.zfdb.rent.aggregate([
{'$match': {'area': {'$gt': 60, '$lte': 90}}},
{'$group': {'_id': '', 'count': {'$sum': 1}}}
])
results90_120 = self.zfdb.rent.aggregate([
{'$match': {'area': {'$gt': 90, '$lte': 120}}},
{'$group': {'_id': '', 'count': {'$sum'
: 1}}}
])
results120_200 = self.zfdb.rent.aggregate([
{'$match': {'area': {'$gt': 120, '$lte': 200}}},
{'$group': {'_id': '', 'count': {'$sum': 1}}}
])
results200_300 = self.zfdb.rent.aggregate([
{'$match': {'area': {'$gt': 200, '$lte': 300}}},
{'$group': {'_id': '', 'count': {'$sum': 1}}}
])
results300_400 = self.zfdb.rent.aggregate([
{'$match': {'area': {'$gt': 300, '$lte'
: 400}}},
{'$group': {'_id': '', 'count': {'$sum': 1}}}
])
results400_10000 = self.zfdb.rent.aggregate([
{'$match': {'area': {'$gt': 300, '$lte': 10000}}},
{'$group': {'_id': '', 'count': {'$sum': 1}}}
])
results0_30_ = list(results0_30)[0]["count"]
results30_60_ = list(results30_60)[0]["count"]
results60_90_ = list(results60_90)[0]["count"]
results90_120_ = list(results90_120)[0]["count"]
results120_200_ = list(results120_200)[0]["count"]
results200_300_ = list(results200_300)[0]["count"]
results300_400_ = list(results300_400)[0]["count"]
results400_10000_ = list(results400_10000)[0]["count"]
attr = ["0-30平方米", "30-60平方米", "60-90平方米", "90-120平方米", "120-200平方米", "200-300平方米", "300-400平方米", "400+平方米"]
value = [
results0_30_, results30_60_, results60_90_, results90_120_, results120_200_, results200_300_, results300_400_, results400_10000_
]
return (attr, value)
数据展示:
# 展示饼图
def showPie(self, title, attr, value):
from pyecharts import Pie
pie = Pie(title)
pie.add("aa", attr, value, is_label_show=True)
pie.render()
# 展示矩形树图
def showTreeMap(self, title, data):
from pyecharts import TreeMap
data = data
treemap = TreeMap(title, width=1200, height=600)
treemap.add("深圳", data, is_label_show=True, label_pos='inside', label_text_size=19)
treemap.render()
# 展示条形图
def showLine(self, title, attr, value):
from pyecharts import Bar
bar = Bar(title)
bar.add("深圳", attr, value, is_convert=False, is_label_show=True, label_text_size=18
, is_random=True,
# xaxis_interval=0, xaxis_label_textsize=9,
legend_text_size=18, label_text_color=["#000"])
bar.render()
# 展示词云
def showWorkCloud(self, content, image_filename, font_filename, out_filename):
d = path.dirname(__name__)
# content = open(path.join(d, filename), 'rb').read()
# 基于TF-IDF算法的关键字抽取, topK返回频率最高的几项, 默认值为20, withWeight
# 为是否返回关键字的权重
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=False)
text = " ".join(tags)
# 需要显示的背景图片
img = imread(path.join(d, image_filename))
# 指定中文字体, 不然会乱码的
wc = WordCloud(font_path=font_filename,
background_color='black',
# 词云形状,
mask=img,
# 允许最大词汇
max_words=400,
# 最大号字体,如果不指定则为图像高度
max_font_size=100,
# 画布宽度和高度,如果设置了msak则不会生效
# width=600,
# height=400,
margin=2,
# 词语水平摆放的频率,默认为0.9.即竖直摆放的频率为0.1
prefer_horizontal=0.9
)
wc.generate(text)
img_color = ImageColorGenerator(img)
plt.imshow(wc.recolor(color_func=img_color))
plt.axis("off")
plt.show()
wc.to_file(path.join(d, out_filename))
# 展示 pyecharts 的词云
def showPyechartsWordCloud(self, attr, value):
from pyecharts import WordCloud
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", attr, value, word_size_range=[20, 100])
wordcloud.render()
不管怎样,最近房租的暴涨真得让人无能为力。应对外界条件的变动,我们还是应该提升自己的硬实力,这样才能提升自己的生存能力。
作者:zone7,一只爱折腾的后端攻城狮,爱写作爱分享。
声明:本文首发于公众号 zone7,作者投稿,版权归对方所有。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
————— 推荐阅读 —————









