声明:仅用于学习交流,请勿用于任何商业用途!感谢大家!
需求:在千图网http://www.58pic.com中的某一板块中,将一定页数的高清图片素材爬取到一个指定的文件夹中。
分析:以数码电器板块为例
查看该板块的每一页的URL:
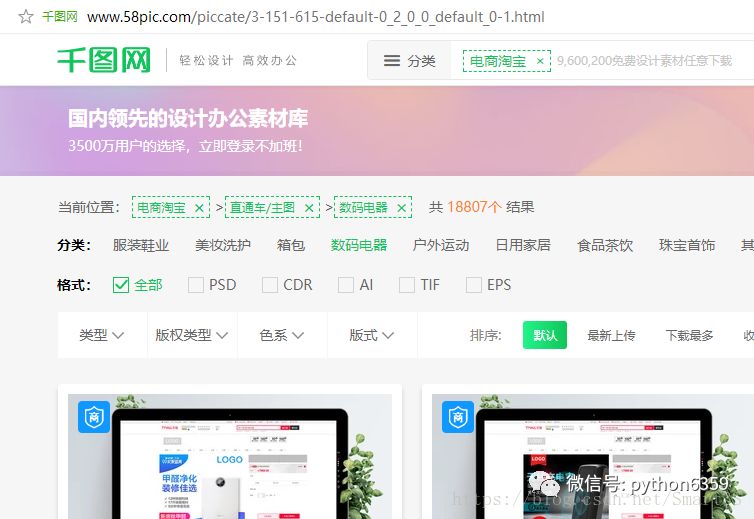
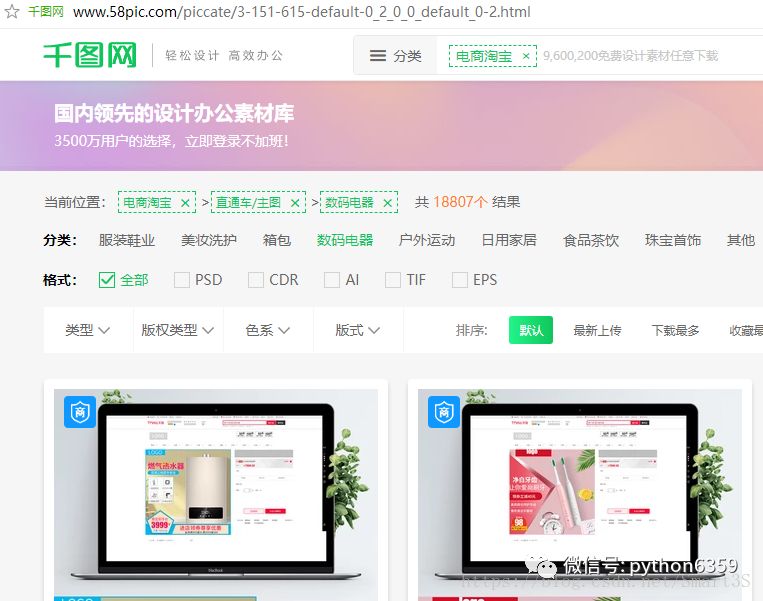
注意到第一页是“0-1.html”,第二页是“0-2.html”,由此可找到规律。
2.查看缩略图片的URL,使用F12开发者工具,通过element选项卡中的工具对网页div进行不断展开,找到图片真正的地址:

例如:

3.查看高清图的URL:进入图片详情界面,直接右键点击图片查看图片地址,如:
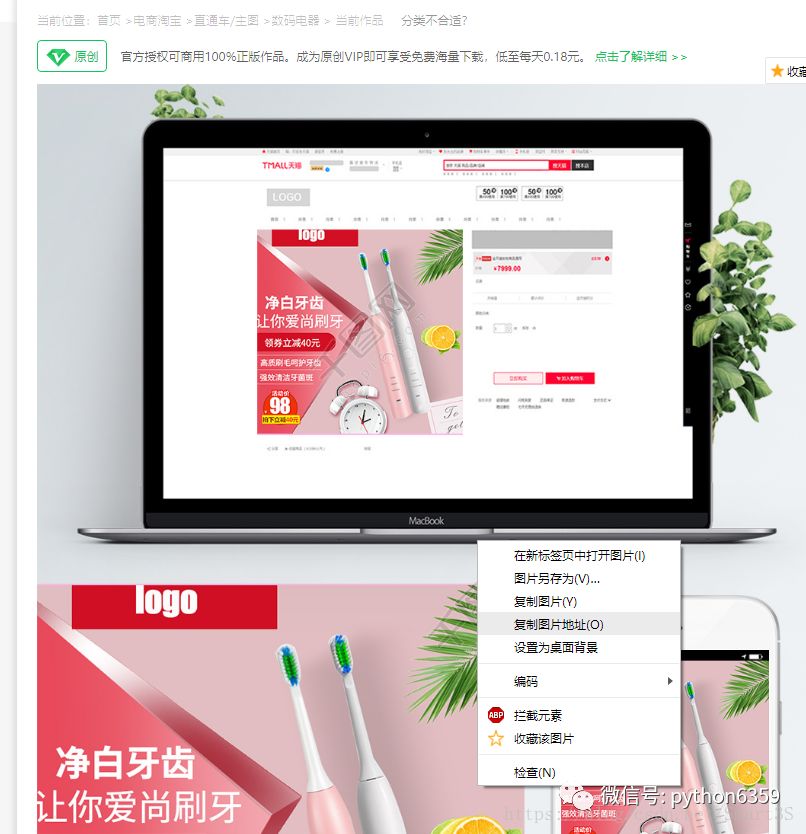
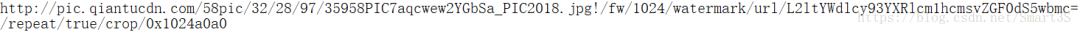
比较缩略图与高清图的URL对应关系,即可得出结论,高清图URL=至“.jpg!”的缩略图URL+“一陀代码”
4.编写代码:
import urllib.request
import re
import urllib.error
for i in range(1,10):
pageurl="http://www.58pic.com/piccate/3-151-615-default-0_2_0_0_default_0-"+str(i)+".html"
data=urllib.request.urlopen(pageurl).read().decode("utf-8","ignore")
pat='











