
深度学习很大程度上仍是一个黑箱,但研究者一直没有停下理解它的步伐。普林斯顿高等研究院的研究者 Nadav Cohen 近日发文介绍了理解深度学习优化的进展以及他们近期在这方面的一项研究成果。
神经网络优化本质上是非凸的,但简单的基于梯度的方法似乎总是能解决这样的问题。这一现象是深度学习的核心支柱之一,并且也是我们很多理论学家试图揭示的谜题。这篇文章将总结一些试图攻克这一问题的近期研究,最后还将讨论我与 Sanjeev Arora、Noah Golowich 和 Wei Hu 合作的一篇新论文(arXiv:1810.02281)。该论文研究了深度线性神经网络上梯度下降的情况,能保证以线性速率收敛到全局最小值。
图景(landscape)方法及其局限性
很多有关深度学习优化的论文都隐含地假设:在建立了损失图景(尤其是临界点的损失图景,临界点是指梯度消失的点)的几何性质之后,就会得到对其的严格理解。举个例子,通过类比凝聚态物理学的球形自旋玻璃模型,Choromanska et al. 2015 的论证变成了深度学习领域的一个猜想:
图景猜想:在神经网络优化问题中,次优的临界点的 Hessian 非常可能有负的特征值。换句话说,几乎没有糟糕的局部最小值,而且几乎所有的鞍点都是严格的。
针对多种不同的涉及浅(两层)模型的简单问题的损失图景,这一猜想的强形式已经得到了证明。这些简单问题包括矩阵感知、矩阵完成、正交张量分解、相位恢复和具有二次激活的神经网络。也有研究者在探究当图景猜想成立时实现梯度下降到全局最小值的收敛,Rong Ge、Ben Recht、Chi Jin 和 Michael Jordan 的博客已经给出了很好的描述:
http://www.offconvex.org/2016/03/22/saddlepoints/
http://www.offconvex.org/2016/03/24/saddles-again/
http://www.offconvex.org/2016/03/24/saddles-again/
他们描述了梯度下降可以如何通过逃避所有的严格鞍点来达到二阶局部最小值(Hessian 为正半定的临界点),并还描述了当将扰动加入到该算法时这个过程是如何有效的。注意这是在图景猜想下,即当没有糟糕的局部最小值和非严格鞍点时,二阶局部最小值可能也是全局最小值。
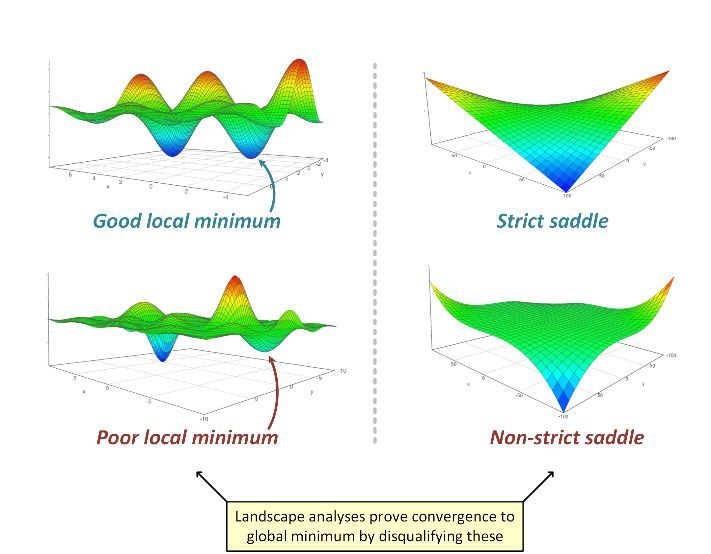
但是,很显然,图景方法(和图景猜想)不能以这种方式应用于深度(三层或更多层)网络。有多个原因。第一,深度网络通常会引入非严格鞍点(比如,在所有权重都为零的点,参见 Kawaguchi 2016)。第二,图景角度很大程度上忽视了算法方面,而在实践中算法方面对深度网络的收敛有很大的影响——比如初始化或批归一化的类型。最后,正如我在之前的文章中谈到的,基于 Sanjeev Arora 和 Elad Hazan 的研究,为经典线性模型添加(冗余的)线性层有时能为基于梯度的优化带来加速,而不会给模型的表现力带来任何增益,但是却会为之前的凸问题引入非凸性。任何仅依靠临界点性质的图景分析都难以解释这一现象,因为通过这样的方法,因为优化一个具有单个临界点且该临界点是全局最小值的凸目标是最困难的。
解决方案?
图景方法在分析深度学习优化上的局限性说明它可能抛弃了太多重要细节。比起「图景方法是否优雅」,也许更相关的问题是「来自特定初始化的特定优化器轨迹(trajectory)具有怎样的行为?」
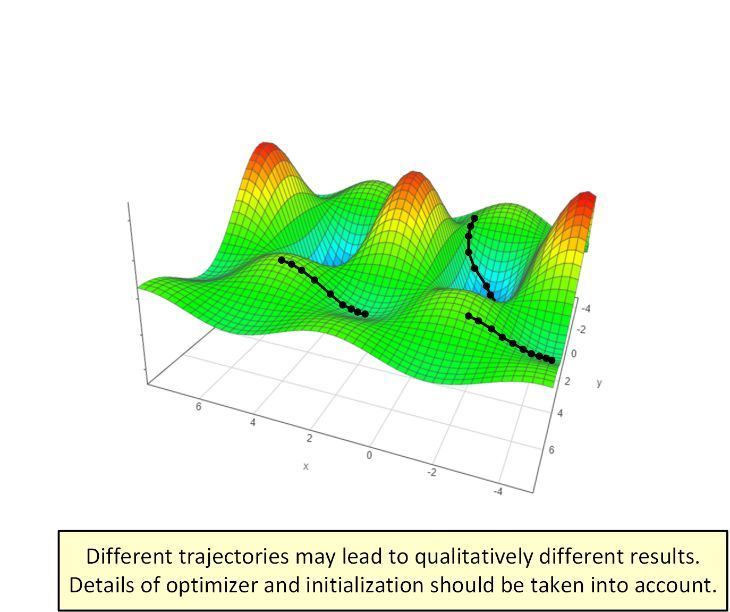
尽管基于轨迹的方法看起来比图景方法繁重得多,但它已经带来了可观的进展。近期一些论文(比如 Brutzkus and Globerson 2017、Li and Yuan 2017、Zhong et al. 2017、Tian 2017、Brutzkus et al. 2018、Li et al. 2018、Du et al. 2018、Liao et al. 2018)已经采用了这一策略,并成功分析了不同类型的浅模型。此外,基于轨迹的分析也正开始涉足图景方法之外的领域——对于线性神经网络情况,他们已经成功确立在任意深度下梯度下降到全局最小值的收敛性。
对深度线性神经网络的基于轨迹的分析
线性神经网络是使用线性激活或不使用激活的全连接神经网络。具体来说,一个输入维度为 d_0,输出维度为 d_N 且隐藏维度为 d_1,d_2…d_{N-1} 的深度为 N 的线性网络是
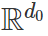
到
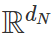
的线性映射,该映射被参数化为
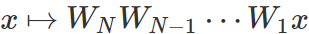
,其中
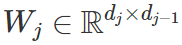
是第 j 层的权重矩阵。尽管这样表示看起来很简单普通,但线性神经网络在优化方面在某种程度上复杂得让人惊讶——它们会导致具有多个最小值和鞍点的非凸训练问题。被视为深度学习中优化的替代理论,基于梯度的算法在线性神经网络上的应用在这段时间收到了极大的关注。
就我所知,Saxe et al. 2014 是首次为深度(三或更多层)线性网络执行了基于轨迹的分析,在白化的数据上处理最小化 ℓ2 损失的梯度流(学习率极小的梯度下降)。尽管这个分析有很重要的贡献,但却并未正式确立到全局最小值的收敛性,也没有考虑计算复杂性方面(收敛所需的迭代次数)。近期研究 Bartlett et al. 2018 在填补这些空白上取得了进展,应用了基于轨迹的方法来分析用于线性残差网络特定案例的梯度下降,即所有层都有统一宽度(d_0=d_1=…=d_N)且同等初始化(W_j=I, ∀j)的线性网络。考虑到数据-标签分布各有不同(他们称之为「targets」),Bartlett 等人展示了可证明梯度下降以线性速率收敛到全局最小值的案例——在
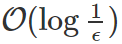
次迭代后与最优的损失小于 ϵ>0;还展示了无法收敛的情况。
在我与 Sanjeev Arora、Noah Golowich 和 Wei Hu 合作的一篇新论文中,我们在使用基于轨迹的方法方面又向前迈进了一步。具体而言,我们分析了任意不包含「瓶颈层」的线性神经网络的梯度下降轨迹,瓶颈层是指其隐藏维度不小于输入和输出维度之间的最小值
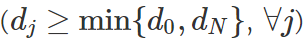
;还证明了以线性速率到全局最小值的收敛性。但初始化需要满足下面两个条件:(1)近似平衡度(approximate balancedness)——
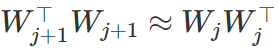
;(2)缺值余量(deficiency margin)——初始损失小于任意秩缺失解的损失。我们证明这两个条件都是必需的,违反其中任意一个都可能导致轨迹不收敛。在线性残差网络的特殊案例中,初始化时的近似平衡度很容易满足,而且对于以零为中心的小随机扰动进行初始化的自定义设置也同样容易满足。后者也会导致出现具有正概率的缺值余量。对于 d_N=1 的情况(即标量回归),我们提供了一个随机初始化方案,能同时满足这两个条件,因此能以恒定概率以线性速率收敛到全局最小值。
我们分析的关键是观察权重是否初始化到了近似平衡,它们会在梯度下降的整个迭代中一直这样保持。换句话说,优化方法所采取的轨迹遵循一个特殊的特征:
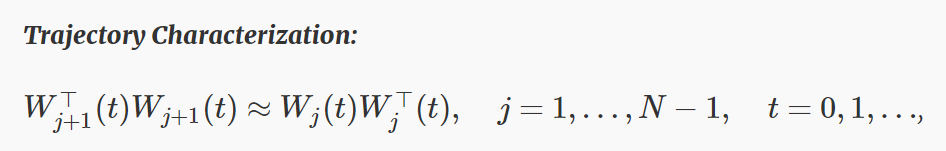
其意思是在整个时间线中,所有层都有(接近)一样的奇异值集合,而且每层的左侧奇异值向量都与其后一层的右侧奇异值向量(接近)一致。我们表明这种规律性意味着梯度下降能稳定运行,从而证明即使是在损失图景整体很复杂的案例中(包括很多非严格鞍点),它也可能会在优化器所取的特定轨迹周围表现得特别良好。
总结
通过图景方法解决深度学习中优化的问题在概念上很吸引人,即分析与训练所用算法无关的目标的几何性质。但是这一策略存在固有的局限性,主要是因为它要求整个目标都要优雅,这似乎是一个过于严格的要求。替代方法是将优化器及其初始化纳入考量,并且仅沿所得到的轨迹关注其图景。这种替代方法正得到越来越多的关注。图景分析目前仅限于浅(两层)模型,而基于轨迹的方法最近已经处理了任意深度的模型,证明了梯度下降能以线性速率收敛到全局最小值。但是,这一成功仅包含了线性神经网络,还仍有很多工作有待完成。我预计基于轨迹的方法也将成为我们正式理解深度非线性网络的基于梯度的优化的关键。
文章来源:机器之心
原文链接:
http://www.offconvex.org/2018/11/07/optimization-beyond-landscape/
识别下图二维码,加“数盟社区”为好友,回复暗号“入群”,加入数盟社区交流群,群内持续有干货分享~~

媒体合作请联系:
邮箱:xiangxiaoqing@stormorai.com







