作者王维栋,网易游戏运维与基础架构部,产品软件设计师,专注于智能监控、性能优化等领域。
本文来自《网易游戏运维平台 (neteasegameops)》微信公众号的投稿,隶属于网易游戏运维与基础架构部,运基部专注于虚拟化、智能运维、SAAS服务、游戏安全、大数据、网络等领域, 服务的产品包括《明日之后》、《梦幻西游》、《大话西游》、《第五人格》等数百款游戏。
投稿邮箱:pythonpost@163.com
前言
借着机器学习的东风,Python近年来大热,一举冲入最受欢迎编程语言榜前三。同时,Python已经在Web、运维、科学计算、游戏等领域广泛应用,很多人使用它来构建原型、实现周边模块、做实验、写性能要求不高的业务逻辑、作为胶水语言完成系统串联,亦有不少公司使用Python来开发大型应用。
如今,拿Python写的代码越来越多,有代码的地方就有bug。虽然bug free是我们的追求,但有时面对复杂需求、大型系统,我们不得不接受一个事实:我们可能要花一半时间写bug,再花另一半时间把它们调试好。代码调试占了如此高的工作比重,那么提升它的效率就是一个很有意义的话题了。
Python是一种强类型动态语言,具有非常活跃的社区和海量的库。所以,我们在使用传统的代码调试方法的同时,还多了一些额外的选择。接下来的章节中我会介绍一些常见的调试方法和Python特有的技巧,并分享一些调试的经验。
Print & Logging
Print和logging可以在代码运行过程中暴露出一些变量的值、打印出关键信息,帮助我们观察和跟踪代码的执行过程。
Print Print Print
作为script programmer,我们在调试时的第一反应是print here, print there, print everywhere. 在写小脚本的时候这样做完全没问题,但当我们开始构建比较复杂的业务模块的时候,print的问题就显现出来了,格式随意、缺乏时间戳等必要信息、通常只print到stdout,写其他的流或者文件还需要额外的代码。最关键的一点是:看起来一点都不专业 233。下面是一个简单的例子:
try:
1 / 0
except ZeroDivisionError as e:
print(
"some text", e)
with open("some.log", 'w') as f:
print("some text", e, file=f)
Logging的实践与价值
Logging是比print更规范和“专业“的做法,下面罗列一些logging的好处和个人觉得比较有用的实践:
规范格式
我们可以定义好日志的规范格式,包含必要信息,并且有利于后续的日志处理和分析。如下是使用logging.Formatter格式化日志的例子:
LOG_FORMAT = '%(asctime)s %(levelname) 8s: [%(filename)s:%(lineno)d] [%(processName)s:%(process)d %(threadName)s] - %(message)s'
DATE_FORMAT = '[%Y-%m-%d %H:%M:%S]'
def get_logger(name):
logger = logging.getLogger(name)
formatter = logging.Formatter(LOG_FORMAT, DATE_FORMAT)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger
logger = get_logger(__name__)
logger.warning("test msg")
得到这样的日志输出:
[2019-01-09 13:36:26] WARNING: [test1.py:33] [MainProcess:16830 MainThread] - test msg
如果想让日志更易处理,更有表现力,可以尝试结构化的日志,一个使用logging.Filter结构化日志的例子:
import json
class JsonLogFilter(logging.Filter):
def filter(self, log):
if isinstance(log.msg, str):
return True
if isinstance(log.msg, (dict, list, tuple)):
log.msg = json.dumps(log.msg)
return True
return False
logger.addFilter(JsonLogFilter())
logger.warning({
"action": "server_start",
"port": 8080,
"engine": {"name": "tornado", "version": "0.1.1"}
})
得到这样的日志输出:
[2019-01-09 13:46:01] WARNING: [test1.py:
57] [MainProcess:17549 MainThread] - {"action": "server_start", "port": 8080, "engine": {"name": "tornado", "version": "0.1.1"}}
这样的日志可以很清晰地携带大量信息,后续的日志解析和处理也更方便。
分级
logging可以定义消息等级,常见的等级:
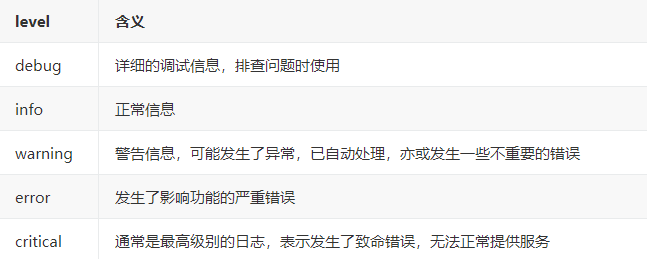
我们可以通过logger的同名成员函数来输出不同等级的日志,设置logger或者logHandler的level,来决定什么级别的日志会被输出:
logger.setLevel(logging.ERROR)
stdLogHandler.setLevel(logging.INFO)
这些工作会在后续的日志处理中产生价值,一些实践例子:
把error和critical的日志输出到单独的error log文件,查问题时优先关注它们;
把error和critical日志直接流入报警系统、故障自愈系统等,触发对应策略;
业务发布时关掉debug日志,在排查问题时通过外部配置、RPC等方式触发进程修改日志等级;
排查问题时,启动一个新的进程,指定debug level的日志,输出debug log来辅助排查;
多种输出流
logging模块提供了文件、标准输出等多种logHandler,我们也可以自定义自己的handler,让日志输出到不同的流。
logger也可以添加多个logHandler,并且分别定义Formatter、Level,让日志同时以不同的方式输出到多个流。
按模块管理
每个logger初始化的时候都可以指定名字,我们通常会以模块名作为logger name,方便后续的管理和日志使用。
例如,我们同时使用了requests和kafka,但我们比较关注kafka的日志,requests只有在error的时候才值得关注,可以这样配置:
logging.getLogger('requests').setLevel(logging.ERROR)
logging.getLogger("kafka").setLevel(logging.WARNING)
Logging准则
通过以上的的介绍,我们已经可以自如地定制日志的输出了,那么什么时候应该输出日志呢?日志太多会影响性能,造成不必要的干扰,难以阅读,日志太少会让我们对进程的执行情况缺乏了解。在实践中,我们应该在生产环境尽可能取得二者平衡。
这里有一些建议:
确保每一次日志输出都是有价值、无歧义、易读的;
Debug日志尽可能详尽地输出细节信息,例如关键函数的调用、输入、输出,某些关键分支步骤的选择等,在生产环境中关闭,必要时再打开;
一些重要变量的变更、重要函数的调用应该尽量输出日志;
做一些周期性指标统计并通过日志等方式输出,以备监控报警和观察执行情况,例如QPS、数据吞吐量、任务堆积数等;
CRUD中的Create、Update、Delete通常需要输出Info log,用作资源操作记录;
对一些可以发生,但大量发生代表可能有严重问题的代码分支,最好输出Warning日志,并在后续日志报警中按数量报警,例如:缓存未命中,RPC Retry等;
可自动恢复的异常通常至少要输出Warning日志;
不可恢复的异常视逻辑严重程度输出Error或者Critical日志,并且要带上堆栈和必要的变量信息;
微服务系统中,确保每条日志都带上可追踪的session id;
不要在频繁调用的函数中输出Info及以上级别的日志,如果真的需要,可以考虑周期统计输出,或者采样输出;
IDE Debugger
无意挑起IDE和编辑器之争,但现代的IDE确实提供了更便捷更强大的Debug功能,这些功能通常需要我们这些vim、sublime、emacs爱好者花费额外的时间才能得到。
对广大IDE使用者来说,最便捷的离线调试方法显然就是IDE Debugger了,我们以PyCharm为例简单介绍下。
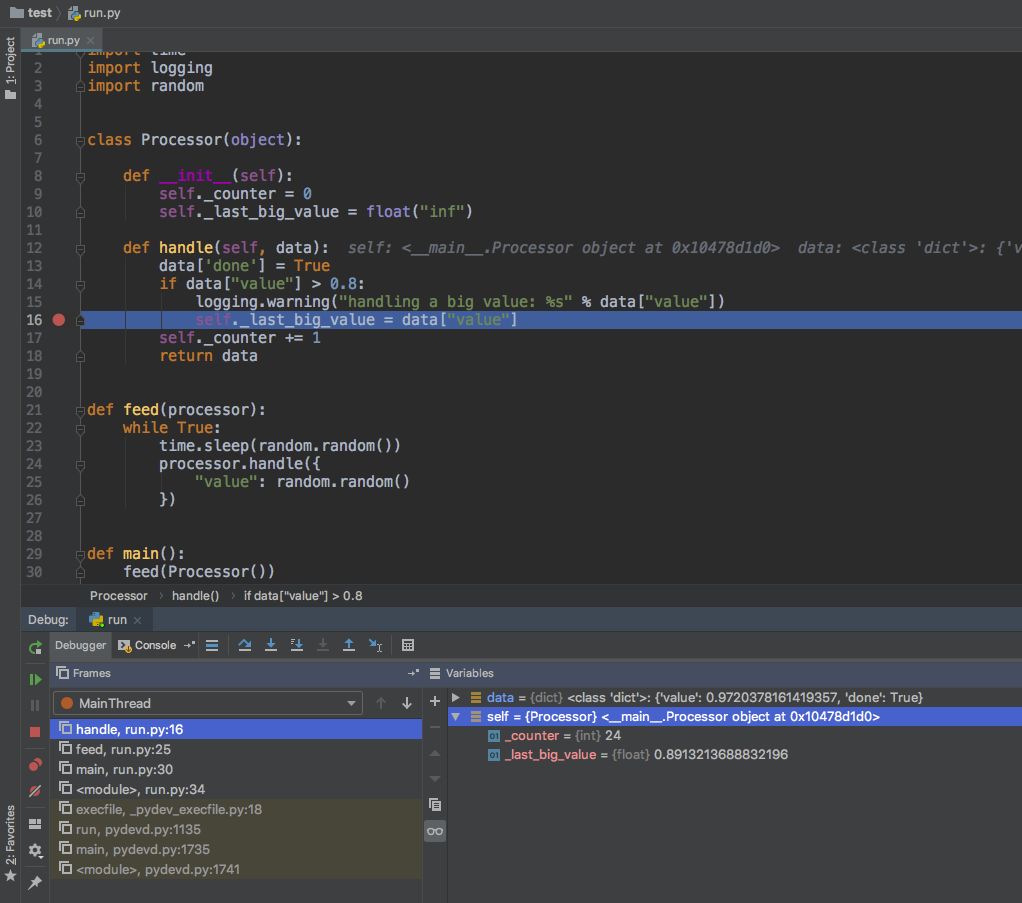
PyCharm Debugger提供了一系列常见的功能:
断点;
step in / out, step over等操作;
Variables窗口,查看当前scope内的变量,也可以自己添加Watches;
Frames窗口,可以切换线程,查看线程的Frames链。
Evaluate窗口,可以直接计算表达式值;
Attach到已运行的进程,并开启Debugger。
GDB系列调试器
仍然有大量程序员是GDB、PDB、IPDB系列Debugger的用户,这些工具同样能在代码调试过程中产生帮助,以ipdb(Ipython pdb)为例。
IPDB调试代码
我们可以直接加载ipdb,启动进程:
➜ test python3 -m ipdb run.py
> /Users/Valens/PycharmProjects/test/run.py(1)<module>()
----> 1 import time
2 import logging
3 import random
ipdb> r
WARNING:root:handling a big value: 0.8740442611857767
> /Users/Valens/
PycharmProjects/test/run.py(18)handle()
17 set_trace()
---> 18 self._last_big_value = data["value"]
19 self._counter += 1
ipdb> p data
{'value': 0.8740442611857767, 'done': True}
ipdb> n
> /Users/Valens/PycharmProjects/test/run.py(19)handle()
18 self._last_big_value = data["value"]
---> 19 self._counter += 1
20 return data
也可以在代码中设置断点,并在断点处停下来,启动ipython debugger:
import time
import logging
import random
from ipdb import set_trace
class Processor(object):
def __init__(self):
self._counter = 0
self._last_big_value = float("inf")
def handle(self, data):
data['done'] = True
if data["value"] > 0.8:
logging.warning("handling a big value: %s" % data["value"])
set_trace() # 断点
self._last_big_value = data["value"]
self._counter += 1
return data
def feed(processor):
while True:
time.sleep(random.random())
processor.handle({
"value": random.random()
})
def main():
feed(Processor())
if __name__ == "__main__":
main()
然后执行
➜ test python3 run.py
WARNING:root:handling a big value: 0.844438382990963
> /Users/Valens/PycharmProjects/test/run.py(18)handle()
17 set_trace()
---> 18 self._last_big_value = data["value"]
19 self._counter += 1
ipdb> p data
{'value': 0.844438382990963
, 'done': True}
GDB调试COREDUMP
GDB是老牌且功能强大的Debugger,在后起之秀更加易用的今天,它出场的机会不算多。但当线上进程Coredump时,我们的选择并不多,这时候GDB的强大之处就显现出来了。
使用GDB调试Python,首先需要准备好必要的包:
libpython 让GDB可以调试python代码,包含pybt pyprint pyup pydown等一系列GDB命令的python版本;
python-dbg python debug扩展,包括python符号文件和libpython等工具,在不同发行版的包名可能不一样;
如果你用到了一些c扩展的python库,需要解与之相关的栈,可能也需要对应的dbg包,例如 python-mysqldb-dbg
通常,如果我们知道一个python进程会core dump,那可以选择用python-dbg运行它(当然会有少量性能的trade off),等待它core dump后,再用gdb打开会获得最全面的信息。非dbg运行的python core dump也可以如此尝试,但可能因为符号表缺失、版本不一致等原因损失一些信息。
我们准备一个测试,还是刚才熟悉的代码,在random数字大于0.9时触发一段“神秘代码“,python2.7下的经典stack overflow bug,让进程因为Seg fault而被内核core dump掉。
import time
import logging
import random
class Processor(object):
def __init__(self):
self._counter =
0
self._last_big_value = float("inf")
def handle(self, data):
data['done'] = True
if data["value"] > 0.8:
logging.warning("handling a big value: %s" % data["value"])
self._last_big_value = data["value"]
if data["value"] > 0.9:
raise_seg_fault()
self._counter += 1
return data
def raise_seg_fault():
logging.error("seg fault")
exec'()'*7**6
def feed(processor):
while True:
time.sleep(random.random())
processor.handle({
"value": random.random()
})
def main():
feed(Processor())
if __name__ == "__main__":
main()
跑起~
valens@some-host:~$ python-dbg run.py
WARNING:root:handling a big value: 0.860424864923
WARNING:root:handling a big value: 0.94984309816
ERROR:root:seg fault
Segmentation fault (core dumped)
然后用gdb打开core dump文件,指定exec为python-dbg
valens@some-host:~$ gdb python-dbg core.python-dbg.some-host.28249
GNU gdb (Debian 7.7.1+dfsg-5) 7.7.1
...
Reading symbols from python-dbg...done.
[New LWP 28249]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Core was generated by `python-dbg run.py`.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x0000000000563415 in symtable_visit_expr (st=, e=) at ../Python/symtable.c:1185
跟踪c栈
(gdb) bt
#0 0x0000000000563415 in symtable_visit_expr (st=, e=) at ../Python/symtable.c:1185
#1 0x0000000000563bde in symtable_visit_expr (st=0x7f3fe9b00110, e=0x20f8150) at ../Python/symtable.c:1256
跟踪py栈和变量
# 列出py栈
(gdb) py-bt
#32710 Frame 0x7f3fe9b17248, for file run.py, line 25, in raise_seg_fault ()
exec'()'*7**6
#32714 Frame 0x7f3fe9b33c60, for file run.py, line 18, in handle (self=
) at remote 0x7f3fe9b0ba00>, data={'done': True, 'value': })
raise_seg_fault()
#32717 Frame 0x7f3fe9aef840, for file run.py, line 32, in feed (processor=) at remote 0x7f3fe9b0ba00>)
"value": random.random()
#32720 Frame 0x7f3fe9b887e0, for file run.py, line 37, in main ()
feed(Processor())
#32723 Frame 0x7f3feb29f060, for file run.py, line 41, in ()
main()
# 向上回到frame: handle
(gdb) py-up
#32714 Frame 0x7f3fe9b33c60, for file run.py, line 18, in handle (self=) at remote 0x7f3fe9b0ba00>, data={'done': True, 'value': })
# 查看这个frame的局部变量
(gdb) py-locals
self = <Processor(_counter=
19, _last_big_value=<float at remote 0x1b7e620>) at remote 0x7f3fe9b0ba00>
data = {'done': True, 'value': <float at remote 0x1b7e620>}
# 读一下value
(gdb) p *(PyFloatObject*) 0x1b7e620
$3 = {_ob_next = 0x7f3fe9b10d30, _ob_prev = 0x7f3fe9b33c60, ob_refcnt = 2, ob_type = 0x8b7580 <PyFloat_Type>, ob_fval = 0.94984309816000645}
通过查看py栈和c栈的调用关系和变量值,大部分的问题都应该能定位了~
Tracers
线上的情况经常是错综复杂的,我们也没办法在写代码和测试阶段就完全预测代码的每一步执行和每个分支。当线上业务出问题通常都会有点难以下手。其实很多linux工具都可以在这时候提供帮助。当然,不仅限于看看cpu内存消耗、查查网络链接和fd那么简单,这里以perf和strace做简单举例,如果大家觉得有用,可以更深入地学习具体用法。
Perf追踪性能
perf是linux下一个非常好用的性能profile工具。在日常用来进行性能优化以外,我们也可以在用它来排查一些线上的问题,当一个数据处理进程消费速度减慢,或者一个server cpu暴增时,不妨perf一下,看看进程现在在干嘛,为我们排查和推断问题原因提供依据。
举例:
# perf 进程 6252 10秒,采集call graph信息
perf record -g -p 6252 sleep 10
perf report --stdio
...
89.67% 3.54% python-dbg python2.7-dbg [.] call_function
|
--- call_function
|
|--99.80%-- PyEval_EvalFrameEx
| |
| |--73.81%-- fast_function
| | call_function
| | PyEval_EvalFrameEx
| | |
| | |--72.77%-- fast_function
| | | call_function
| | | PyEval_EvalFrameEx
| | | |
| | | |--54.21%-- fast_function
| | | | call_function
| | | | PyEval_EvalFrameEx
| | | | |
| | | | |--62.17%-- fast_function
| | | | | call_function
| | | | | PyEval_EvalFrameEx
| | | | | |
| | | | | |--56.99%-- fast_function
| | | | | | call_function
| | | | | | PyEval_EvalFrameEx
...
perf report --stdio -g none
# Samples: 3K of event 'cpu-clock'
# Event count (approx.): 839500000
#
# Children Self Command Shared Object Symbol
# ........ ........ .......... .................. .....................................
#
89.67% 0.00% python-dbg libc-2.19.so [.] __libc_start_main
89.67% 0.00% python-dbg python2.7-dbg [.] main
89.67% 0.00% python-dbg python2.7-dbg [.] Py_Main
89.67% 0.00% python-dbg python2.7-dbg [.] PyRun_AnyFileExFlags
89.67% 0.00% python-dbg python2.7-dbg [.] PyRun_SimpleFileExFlags
89.67
% 0.00% python-dbg python2.7-dbg [.] PyRun_FileExFlags
89.67% 0.00% python-dbg python2.7-dbg [.] run_mod
89.67% 0.00% python-dbg python2.7-dbg [.] PyEval_EvalCode
89.67% 3.54% python-dbg python2.7-dbg [.] call_function
89.67% 1.28% python-dbg python2.7-dbg [.] fast_function
89.67% 0.95% python-dbg python2.7-dbg [.] PyEval_EvalCodeEx
89.67% 14.80% python-dbg python2.7-dbg [.] PyEval_EvalFrameEx
57.89% 0.09% python-dbg python2.7-dbg [.] ext_do_call
57.74% 0.33% python-dbg python2.7-dbg [.] PyObject_Call
57.65% 0.24% python-dbg python2.7-dbg [.] function_call
19.15% 0.03% python-dbg python2.7-dbg [.] do_call
18.82% 0.06% python-dbg python2.7-dbg [.] type_call
18.55% 0.21% python-dbg python2.7-dbg [.] slot_tp_init
18.20% 0.09% python-dbg python2.7-dbg [.] instancemethod_call
15.78% 1.94% python-dbg python2.7-dbg [.] PyObject_GetAttr
13.94% 0.12% python-dbg python2.7-dbg [.] PyObject_GenericGetAttr
...
Strace追踪系统调用
有时我们会遇到进程阻塞,这时候可以通过strace来追踪系统调用看看进程是不是卡在某处io,或者在接收巨量的网络包,以及其他跟系统调用、信号相关的场景。
举例:
# strace -p 1227
Process
1227 attached
select(0, NULL, NULL, NULL, {0, 524306}) = 0 (Timeout)
gettimeofday({1547026076, 550492}, NULL) = 0
write(2, "WARNING:root:handling a big valu"..., 50) = 50
select(0, NULL, NULL, NULL, {0, 195142}) = 0 (Timeout)
Inject Debugger
深究代码调试的本质,是观察代码执行,从中找出不合理的逻辑、未处理的边界情况以及可优化的地方。那么,没有什么比直接进入正在执行的Python进程并近距离观察和把玩它的逻辑更方便的了。作为一个动态语言,Python在Debug On-the-fly方面具有非常大的想象空间。
这里夹带私货地介绍一个Python Inject Debugger:pylane
pylane,网易游戏开源的 Python 调试工具
https://github.com/NtesEyes/pylane
pylane 通过 gdb trace python 进程,然后在该进程的python vm中动态地注入一段python代码,从而对一个运行中的python进程执行一段任意的新逻辑。
作为Debugger,pylane最常用的功能是pylane shell,它对目标进程注入了一个新线程,并在这个线程中启动一个python Interpreter,然后连接到终端的IPython Console。接下来,我们就可以在这个Console中访问目标进程中的所有对象。
继续使用上文中的Processor代码,用pylane shell attach它。
pylane shell
接下来举几个典型的用例。
友情提醒,在生产环境做任何非规范的变更都有危险,请三思。
查看变量
如果我们需要看到某个内部变量的值,但这个变量没有通过log等方式暴露出来,那就可以用pylane来直接查看。
pylane shell 4996
# 用内置tools的get_insts方法获取Processor的实例
In [2]: p = tools.get_insts("Processor")[0]
In [3]: p
Out[3]:
<__main__.>Processor object at 0x7f3d45c6ad68>
# 在代码运行的同时观察p的属性变化
In [4]: p._counter
Out[4]: 252
In [5]: p._counter
Out[5]: 262
In [6]: p._last_big_value
Out[6]: 0.8872528770214453
查看代码
在源文件存在的情况下,可以直接查看某个object的代码。
In [2]: tools.print_source_code(tools.get_classes("Processor")[0])
Out[2]:
class Processor(object):
def __init__(self):
self._counter = 0
self._last_big_value = float("inf")
def handle(self, data):
data['done'] = True
if data["value"] > 0.8:
logging.warning("handling a big value: %s" % data["value"])
self._last_big_value = data["value"]
self._counter += 1
return data
触发函数调用
如果需要调用一次函数,触发某段逻辑,也可以直接调用。
In [4]: p = tools.get_insts("Processor")[0]
In [5]: p.handle({"value": -100})
Out[5]: {'done': True, 'value': -100}
打印线程栈和变量
我们有时会想知道进程目前在干什么,比如任务执行的很慢,进程完全阻塞了的情况。
执行下面的方法打印所有线程的栈和变量:
In [6]: tools.print_threads()
Out[6]:
Thread: MainThread
Stack:
File "/usr/lib/python2.7/threading.py", line 1098, in _exitfunc
t.join()
File "/usr/lib/python2.7/threading.py", line 940, in join
self.__block.wait()
File "/usr/lib/python2.7/threading.py", line 340, in wait
waiter.acquire()
Locals:
{'saved_state': None, 'waiter':
lock object at 0x7fc7c9d062d0>, 'self': <Condition(lock object at 0x7fc7c9d06290>, 1)>, 'timeout': None}
或者,如果我们知道线程名,可以这样指定:
tools.print_threads(["Thread1", "Thread2"])
排查内存泄露
objgraph 是一个非常好用的Python内存排查工具,但它需要入侵代码,如果线上有一个难以复现的内存泄露,用pylane + objgraph可以更容易地排查:
先在跑服务的virtual env中准备好objgraph包,然后打开pylane shell
In [5]: import objgraph
In [6]: objgraph.growth()
Out[6]:
[('function', 1484, 1484),
('wrapper_descriptor', 1105, 1105),
('builtin_function_or_method', 732, 732),
('method_descriptor', 590, 590),
('dict', 581, 581),
('tuple', 529
, 529),
('weakref', 509, 509),
('list', 267, 267),
('getset_descriptor', 234, 234),
('member_descriptor', 229, 229)]
In [7]: objgraph.growth()
Out[7]: [('list', 268, 1)]
修改代码逻辑
如果遇到某个调用比较深的函数执行有问题,我们想知道它每次执行了多久,输入输出是什么,但是之前没有log出来,可以monkey patch它。
In [2]: p = tools.get_insts("Processor")[0]
In [3]: origin_func, p.handle = p.handle, tools.log_it(p.handle)
接下来可以看到新的log了
WARNING:root:handling a big value: 0.821825815755
WARNING:root:func: handle sec_cost: 0.0002 input: (({'done': True, 'value': 0.8218258157546575},), {}) output {'done': True, 'value': 0.8218258157546575}
WARNING:root:func: handle sec_cost:
0.0003 input: (({'done': True, 'value': 0.5901812673170566},), {}) output {'done': True, 'value': 0.5901812673170566}
调试完,回滚即可
In [4]: p.handle = origin_func
显而易见,拥有一个attach console,我们能做的事情远不止此,我们可以用它来修改运行时配置(?),开关某个功能(??),热更新代码(???),当然,注意安全。
重申:在生产环境做任何非规范的变更都有危险,请三思。
结语
这篇文章是按个人的一些经验和见解写就,旨在分享一些个人常用的代码调试方式和思路。能力和精力有限,如有谬误,欢迎指正。文章中提到了的大部分工具,都是简单介绍,浅尝辄止,它们的更多功能请参阅各个工具的文档。
在套路和工具以外,代码调试更多的还是依靠开发者的知识储备、编码经验和想象力,当然,偶尔也需要一点运气。持续不断地学习,多看大神们的代码,多写,多总结,才能在写代码和调代码的时候更加驾轻就熟,离bug free的伟大目标更近一点。









