加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 |刘浪
原文 | https://zhuanlan.zhihu.com/p/61955391
动量(Momentum)算法
带动量的 SGD
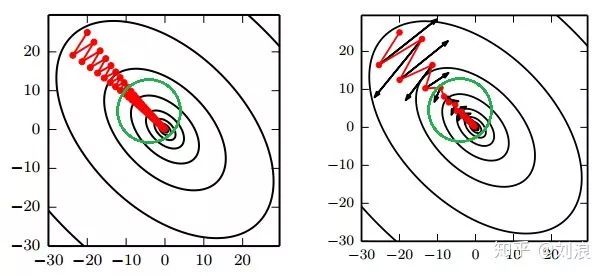
引入动量(Momentum)方法一方面是为了解决“峡谷”和“鞍点”问题;一方面也可以用于SGD 加速,特别是针对高曲率、小幅但是方向一致的梯度。
参数更新公式

 为梯度
为梯度
动量算法描述

如果动量算法总是观测到梯度 g,那么它会在 −g 方向上不断加速,直到达到最终速度。 
在实践中, α 的一般取 0.5, 0.9, 0.99,分别对应最大2 倍、10 倍、100 倍的步长
和学习率一样,α 也可以使用某种策略在训练时进行自适应调整;一般初始值是一个较小的值,随后会慢慢变大。自适应学习率的优化方法
NAG 算法(Nesterov 动量)

自适应学习率的优化算法
AdaGrad

AdaGrad 存在的问题
RMSProp


Adam

偏差修正
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~ 









