
程序员在提升自己的道路,大多还是会选择阅读编程书籍这一途径,但找到一本好书就没那么容易了。
通过查看各大销售网站的销量数据和评价,以及豆瓣评分和评价人数,可以帮助我们更快的挖掘出经典的计算机书籍,还有那些被人们忽视的好书。
最近在GitHub上发现了一个网站,是中国科学院自动化研究所的一大神(lanbing510)用Python写的一个爬虫,他在16年的时候就爬下了豆瓣所有的读书数据并做了个WebApp接口方来挖掘查找和阅读好书。怪我知道的太晚
后来lanbing510再次爬了一遍豆瓣读书的数据,总共更新了3232088本图书信息,共2138386KB,并将其开源
为什么说它很好用呢?猿哥演示一遍你就知道了:
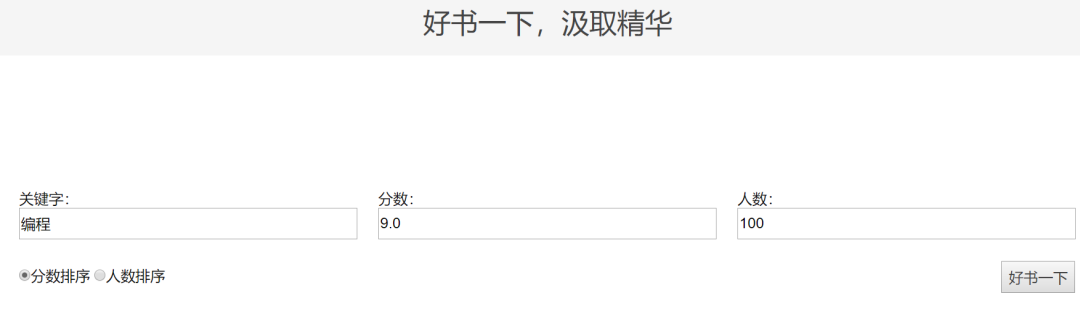
可以看出这网站的界面非常简洁,没有花里花哨的内容,只有干货,你可以直接通过关键字、分数、和评价人数这三个选项进行搜索,比如我们可以搜索关键字:编程;分数:9.0;评价人数:100人以上
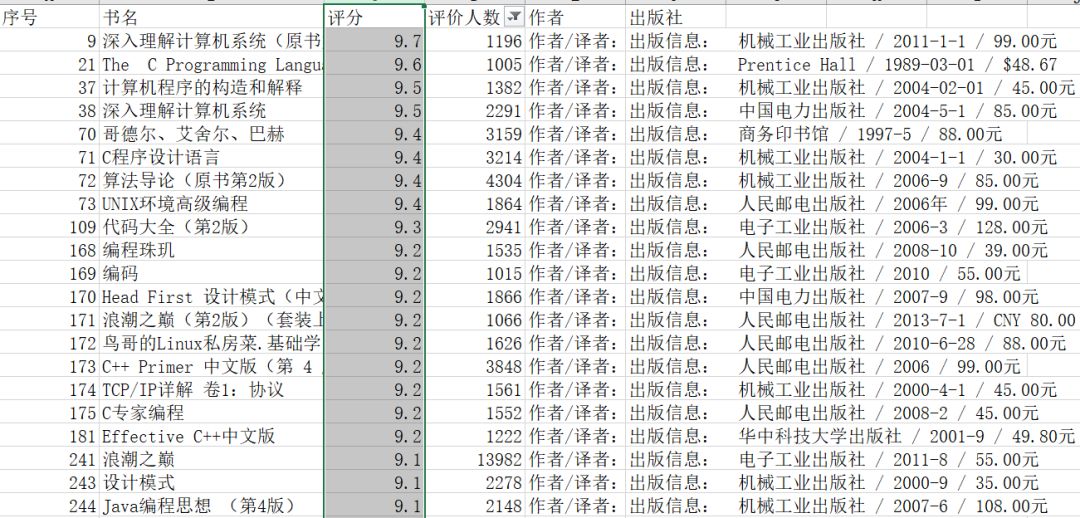
查找结果的显示方式有按照分数排序和人数排序两种,按照分数排序的截图如下:
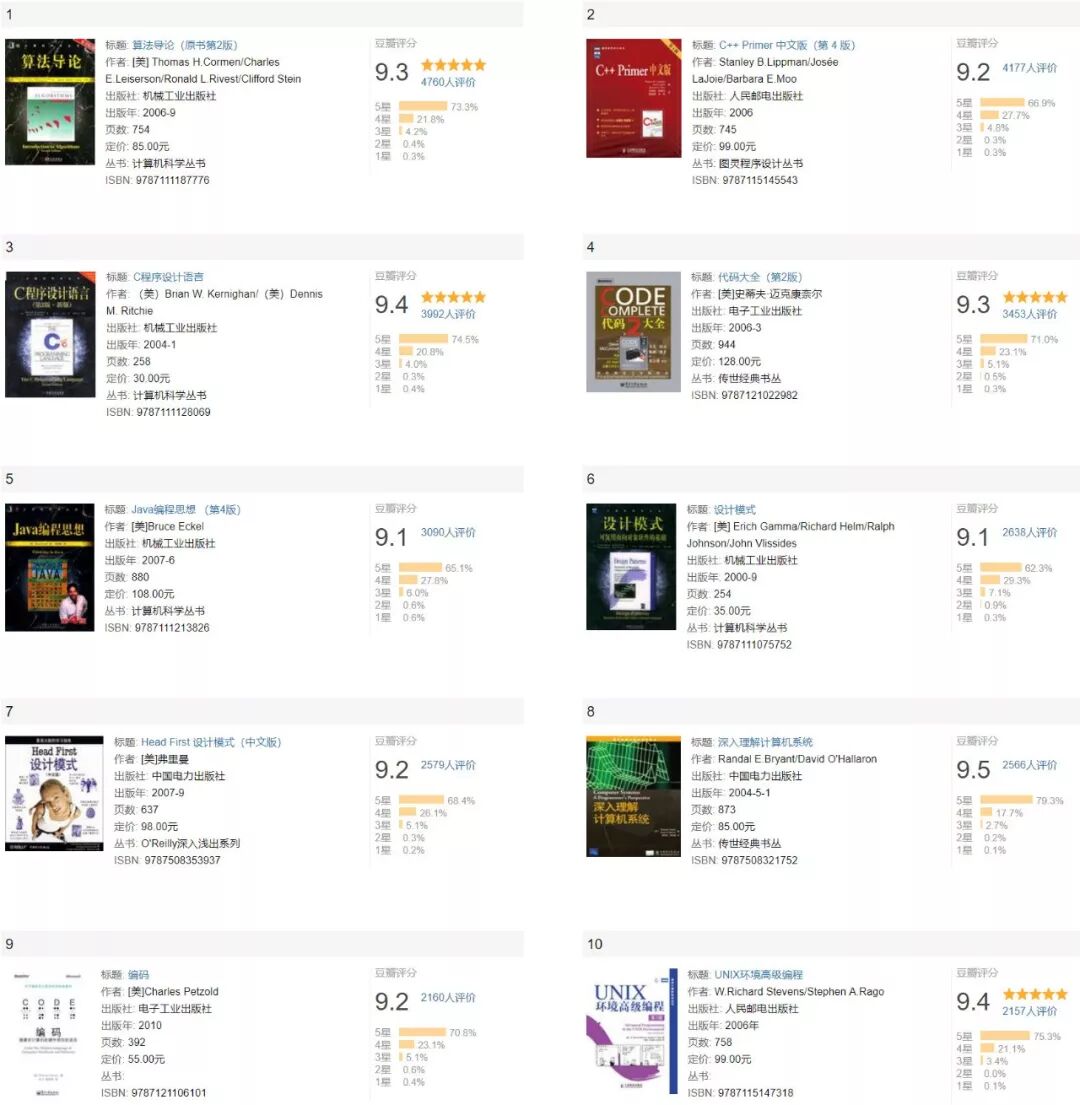
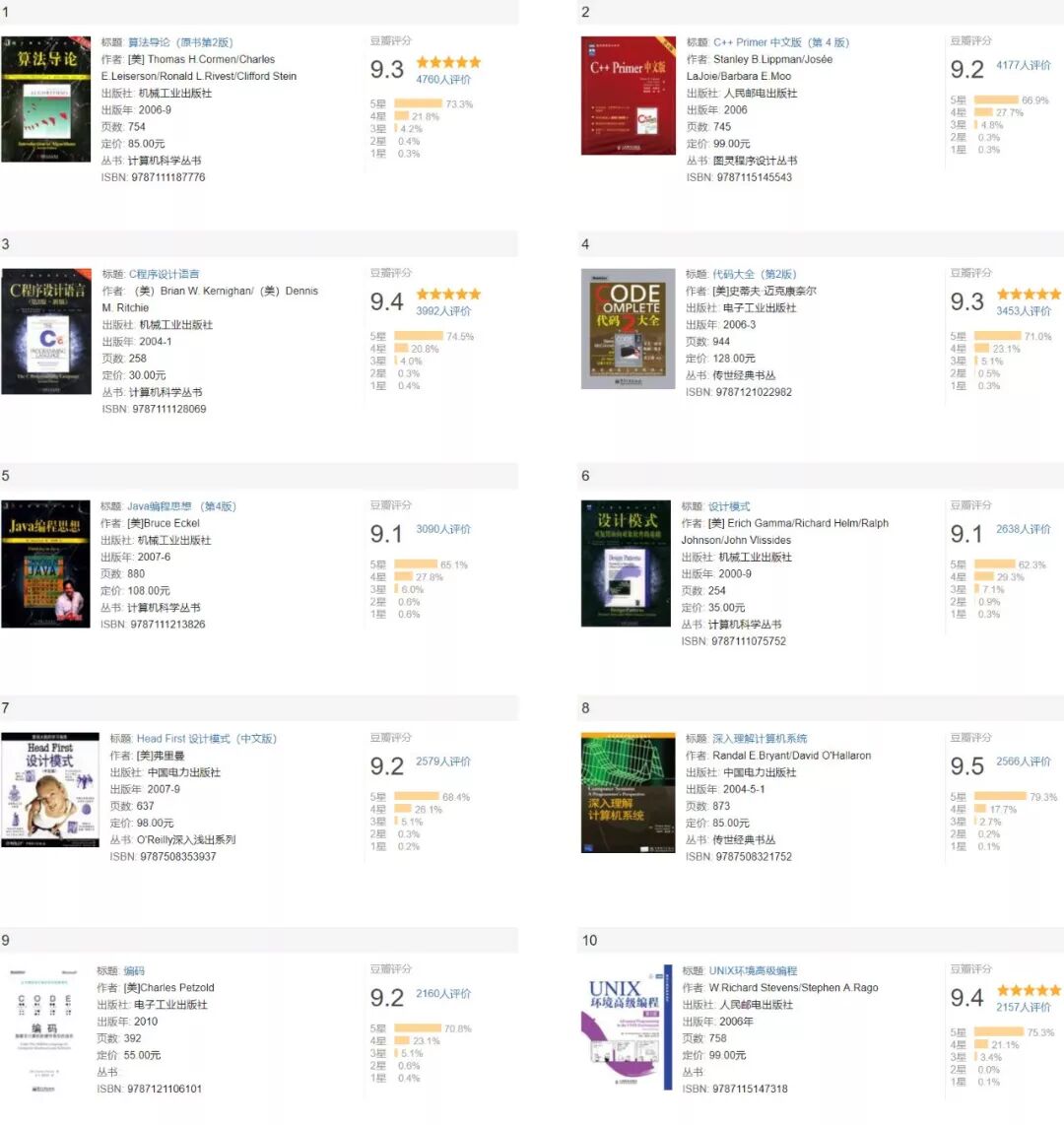
按照评价人数排序的截图如下:
除了以上演示的操作,这个网站并实现了以下功能:
也就是说你不仅可以在网站上搜索,还能通过下载各类目下的Excel书单文件,直接在Excel中搜索
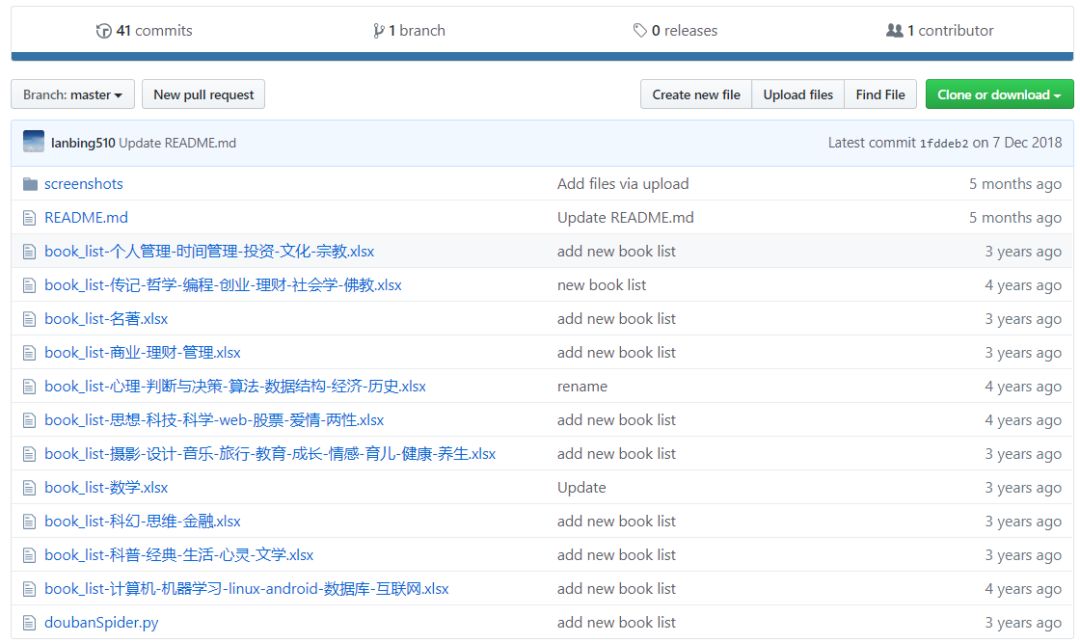
效果截图如下:
最后附上网站地址:http://sobook.lanbing510.info
GitHub地址:https://github.com/lanbing510/DouBanSpider
回复下方「关键词」,获取优质资源
回复关键词「 pybook03」,立即获取主页君与小伙伴一起翻译的《Think Python 2e》电子版
回复关键词「pybooks02」,立即获取 O'Reilly 出版社推出的免费 Python 相关电子书合集
回复关键词「书单02」,立即获取主页君整理的 10 本 Python 入门书的电子版

印度小伙写了套深度学习教程,Github上星标已经5000+
GitHub热榜第四!这套Python机器学习课,免费获取还易吸收
《流畅的 Python》到底好在哪?
如何系统化学习 Python ?
GitHub标星2.6万!Python算法新手入门大全
使用 Vue.js 和 Flask 实现全栈单页面应用
Python 实现一个自动化翻译和替换的工具
使用 Python 制作属于自己的 PDF 电子书
12步轻松搞定Python装饰器
200 行代码实现 2048 游戏
题图:pexels,CC0 授权。








