(给数据分析与开发加星标,提升数据技能)
英文:Ben Sanders,转自:数据派THU(ID:DatapiTHU),翻译:吴慧聪
简介
本文中,数据科学创业公司Yhat的前联合创始人,现任Waldo的联合创始人兼首席技术官Greg Lamp将会为我们这些机器学习菜鸟分享他对机器学习的看法。

目录
一、什么是机器学习?
二、机器学习是如何工作的?
三、机器学习的算法:分类(Classification)与回归(Regression)
四、什么是Tensorflow?
五、为什么机器学习会如此热门?
一、什么是机器学习?
我认为机器学习的定义是使用数据去寻找数据模型。这主要包括两个主要的概念:
使用数学和统计的知识优化模型 ;
这个优化模型的过程称为训练(Training)。
一个可能会令一些人不高兴的观点来了。
人工智能和机器学习是一个相同的东西。
没错,机器学习(Machine Learning)和人工智能(AI)确实是一个回事,但确实言过其实。当那些市场营销的同行讲起人工智能,他们认为人工智能可能最终会发展到统治人类的位置。我也同意这些看法。这确实是一个很好的概括了机器学习的观点,因为机器学习已经可以自学习任何输入的数据。
再者,人工智能在未来还有潜在的发展空间。
我认为机器学习最有趣的应该是它没有真正的新知识。主要流行的机器学习算法已经流行了一段时间。这期间机器学习最大的变化是计算机变得:
因为上述计算机的三大发展特点和机器学习库的不断扩展和便于使用,比如scikit-learn, tensorflow和R(统计学常用的机器学习的语言),越来越多的人会接触到机器学习的内容。可及性在有限的使用量上反过来促进了传播。
二、机器学习是如何工作的?
在机器学习中可以使用不同的算法去寻找数据的模型。虽然这些算法都是做相同的事情:读取数据并赋予这些数据一个权重。但是这些权重可以用于预测未来相同形式的数据。
在过去几年中,机器学习在数据读取上有一个大的跃进,在算法上,对于数据读取的严格的限制条件被减少了。但尽管这样,基本上所有的算法都需要读取简洁,格式一致的数据以提高运算效率。
现在当这些算法需要训练(Train)和校对(Calibrate)的时候, 其实是需要去找出一组点之间的最小距离。让我们看图更能说清楚。
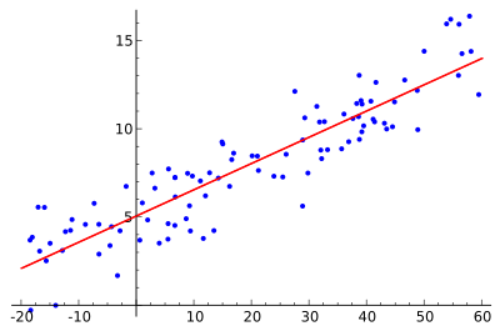
以上图为例。这是一个经典的线性回归(Simple Linear Regression)的例子。蓝点表示想要预测的数据。红线表示“最佳拟和线”,该线是机器学习算法中(用于线性回归的例子)最好地表示数据集特征。
你可以使用这条线去预测后面的观测数据。
三、分类(Classification)与回归(Regression)
我知道我的读者们在想什么了,接下来可能我会来讲讲 Tensorflow以及如何使用它在来满足你最狂野的希望和梦想的同时使得业务盈利。但你们可能误解了。
下面将概述机器学习的两个主要的算法。
绝大多数机器学习任务分为两类:
在回归中,你要尽量计算的是一条将要位于所有数据点“中间”的线(如上所示)。在分类中,你要计算的是一条将要把数据点“分类”的线。
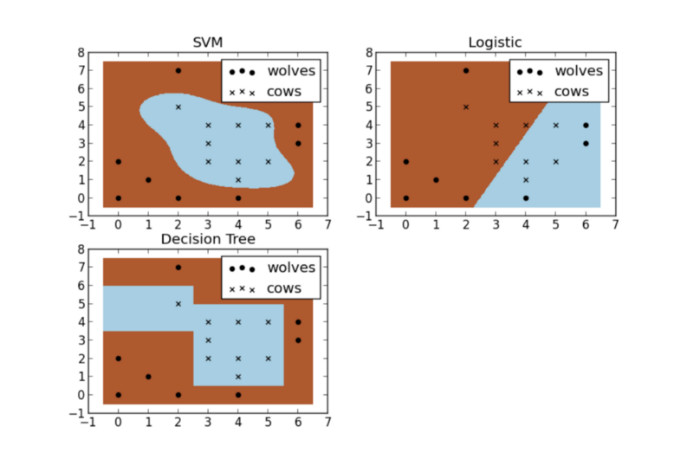
这是最酷的一部分。不同的算法可以使用不同的形状,数字和线的种类来计算中间线或分离线。例如,在上面的狼和牛例子中,有3种不同的算法用于分隔每个类别。如你所见,因为支撑向量机(SVM)的方法是非线性的,这意味着它不必使用直线。但是当使用逻辑回归(Logistic Regression)的方法,因为它是线性的,只能通过直线来分离数据点。第三个例子是决策树(Decision Tree),它使用设置的自动生成的规则来分隔类别。
所以为什么我们不能只使用最复杂的方法呢?
现在仍然不是讲Tensorflow的时候。
好吧,有时候你的模型可能太聪明了。我知道这似乎是倒退了一步,但这是真的。这模型确实是对的。你的人工智能模型可能非常善于理解你所展示的数据集。因此,用于预测未来就不准确了。
举出一个类比的例子。比如在产品管理这样的领域,如果你与一位客户交谈,他们说他们不会购买你的产品,除非按钮是青色的。因为他们公司在徽标和品牌中使用的同样可爱的青色阴影。

青色的按钮
如果您是一名糟糕的产品经理,那么你可能会听取该客户的意见,并使把网站的所有按钮都变成青色。这就是过度拟合。
但你不是一个糟糕的产品经理。你知道,虽然这个客户可能因为你没有青色按钮而不会购买你的产品,但你知道还有很多其他客户不会对按钮颜色不满意。这是因为您对典型客户关心的内容有一个的固有的心理模型。
四、你还打算讲TensorFlow吗?
好,现在来讲一下Tesnorflow。Tensorflow是一个Google生产的机器学习库。但它并不是那么容易使用。你需要知道自己在做什么,才能比用简单直接的库(如scikit-learn)获得更高的投资回报率。

Tensorflow的确做得很好,提供了一种定义和训练神经网络(Neural Network)的简单直观的方法。神经网络是另外一种用来计算线路的算法。神经网络及其同类的深度神经网络(Deep Neural Network)都是便于使用的方法,因为它们可以处理非结构化的数据(如图像,视频等)。我说那些数据是非结构化的是因为最终它们仍然以表格格式输入算法。你不必非常关注数据的精确和纯净程度。十分便于使用!
五、为什么机器学习会如此热门?
机器学习学起来不再困难了,因为它有很丰富的库。如果你看不出来库的区别,我很喜欢用Scikit-learn. 这有很多原因:
在用的时候不需要写很多代码;
它可以实现大部分或者一些机器学习的功能,所以我所做的任何关于机器学习的内容都可以不离开这个库;
它很旧,这意味着它的功能成熟,功能成熟代表不需要处理那些费脑的代码错误;
创建者和维护者他们非常友好地建立了出色的使用说明;
如果我得听一个关于机器学习的讲座,我更喜欢那些像Olivier Grise的人,带着轻微的法国口音,从而增加娱乐价值。

我的那些喜欢机器学习的法语爱好者使用scikit-learn可以把一个非常复杂的机器学习模型减少到5行代码。机器学习的编程不需要很多行的代码。也不需要一个天体物理的博士学位甚至一个技术学位的背景去学习机器学习的知识。
下面是一个随机森林(Random forest)的代码例子:
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
target_variable = 'does-make-more-than-50k'
columns = ['age', 'education', 'hours-worked-per-week']
clf.fit(df[columns], df[target_variable])
看完本文有收获?请转发分享给更多人
关注「数据分析与开发」加星标,提升数据技能

好文章,我在看❤️









