机器之心@微信公众号
在本文中,来自旷视科技、南京大学和早稻田大学的研究者对基于深度学习的细粒度图像分析进行了综述,从细粒度图像识别、检索和生成三个方向展开论述。此外,他们还对该领域未来的发展方向进行了讨论。
计算机视觉(CV)是用机器来理解和分析图像的过程,是人工智能中一个重要分支。在 CV 的各个研究领域中,细粒度,图像分析(fine-grained image analysis, FGIA)是一个长期存在的基础性问题,而且在各种实际应用(比如鸟的种类、汽车模型、商品识别等)中无处不在。由细粒度特性造成的类间(inter-class)小变化和类内(intra-class)大变化使得这一问题具有极大的挑战性。由于深度学习的蓬勃发展,近年来应用了深度学习的 FGIA 取得了显著的进步。
本文系统地对基于深度学习的 FGIA 技术进行了综述。具体来说,本文将针对 FGIA 技术的研究分为三大类:细粒度图像识别、细粒度图像检索和细粒度图像生成。本文还讨论了其他 FGIA 的重要问题,比如公开可用的基准数据集及其在相关领域的特定应用。本文在结尾处强调了未来仍需进一步探讨的几个方向以及待解决的问题。
论文:Deep learning for fine-grained image analysis: A survey
论文链接:https://arxiv.org/pdf/1907.03069.pdf
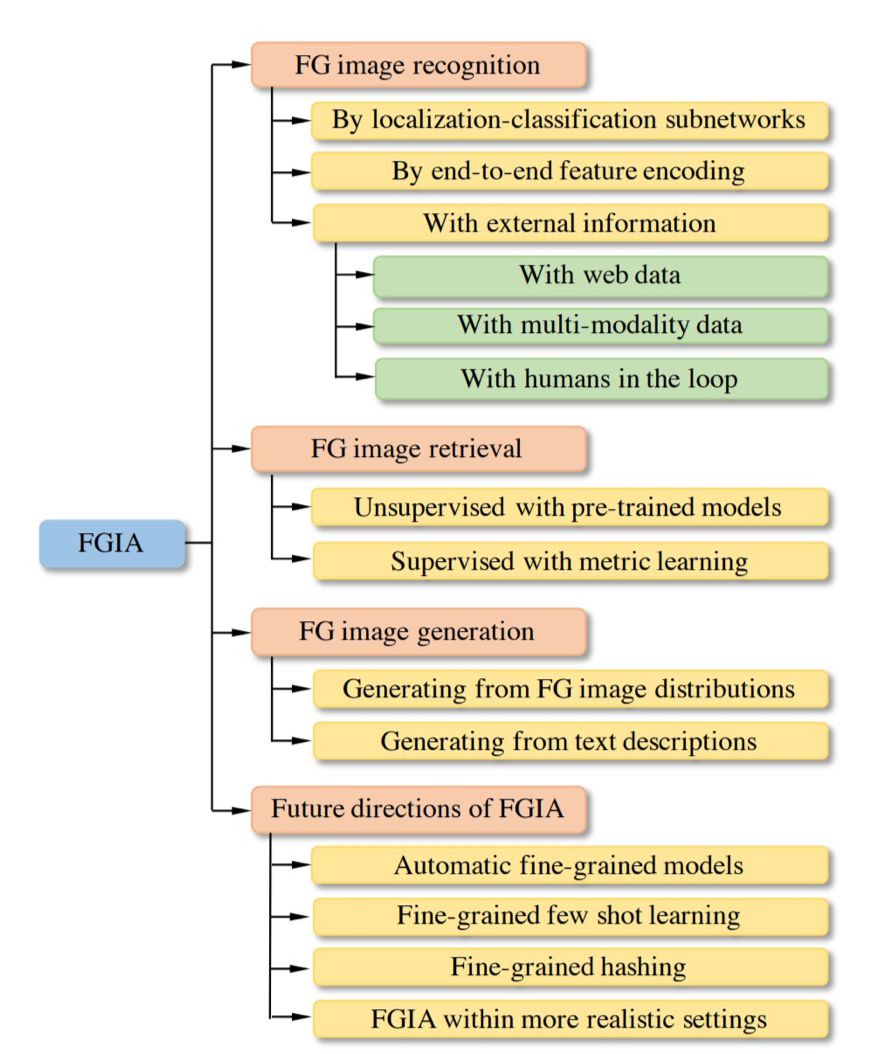
综述结构
在环太平洋国家举办的另一个重要的 AI 会议中,本文作者(魏秀参、吴建鑫)针对细粒度图像分析组织了具体的教程。该教程中提供了一些关于细粒度图像分析的额外的细节信息,所以在此向想深入了解的读者推荐该教程。

教程大纲
教程:http://www.weixiushen.com/tutorial/PRICAI18/FGIA.html
此外,论文作者还开放了一个细粒度图像分析的主页,内含代表性论文、代码、数据集等。

项目目录
项目地址:
http://www.weixiushen.com/project/Awesome_FGIA/Awesome_FGIA.html
背景:FGIA 中的主要问题和挑战
FGIA 与一般的图像分析之间的区别在于:在一般的图像分析中,目标对象属于粗粒度的元类别(例如:鸟、橙子和狗),因此它们看起来非常不同。但在 FGIA 中,由于对象都属于一个元类别的子类,细粒度的特性导致它们看起来非常相似。我们以图像识别为例。如图 1 所示。
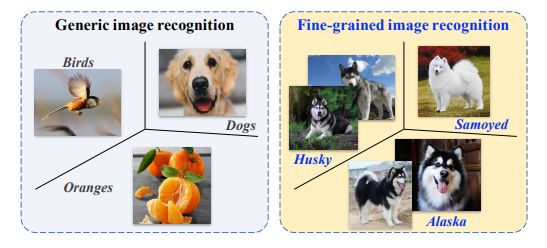
图 1:细粒度图像分析(右)与一般的图像分析(左)
此外,细粒度特性也会导致由子类别高度相似而造成的类间变化较小以及因姿势、尺寸和角度等不同而造成的类内变化大的问题,如图 3 所示。

图 3:细粒度图像分析的关键挑战
基准数据集
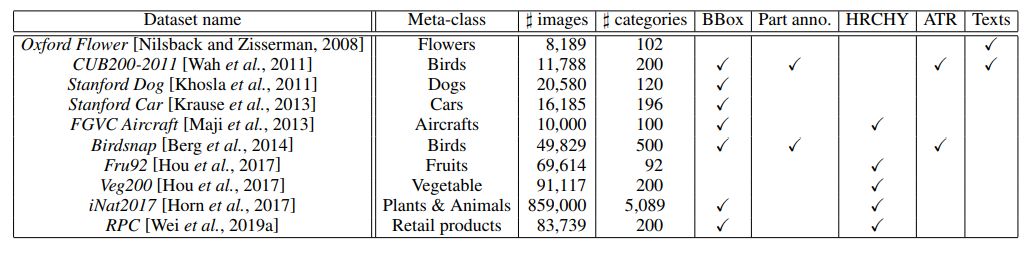
表 1:主流细粒度图像数据集汇总
表 1 中列出了细粒度问题中常用的图像数据集,并特地标出了它们的元类别、细粒度图像的数量、细粒度类别的数量和额外可用的不同种类的监督(即边界框、部位注释、层次标签、属性标签以及文本视觉描述等),参见图 5。
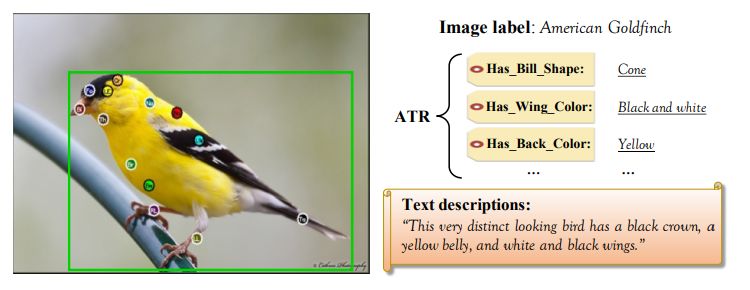
图 5:带有 CUB200-2011 监督信息的示例图像
细粒度图像识别
这些细粒度识别方法可以总结为三个范式:(1)用定位分类子网络进行细粒度识别;(2)用端到端的特征编码进行细粒度识别;(3)用外部信息进行细粒度识别。
其中,第一个范式和第二个范式只用和细粒度图像相关的监督(比如图像标签、边界框以及部分注释等)进行了限制。此外,由于细粒度存在的挑战,自动识别系统还不能实现良好的性能。因此,研究人员逐渐试着在细粒度识别问题中融入外部但易于获得的信息(比如网页数据、文本描述等)来进一步提升准确率,这对应了细粒度识别的第三个范式。细粒度识别中常用的评估指标是数据集所有从属类别的平均分类准确率。
4.1 用定位分类子网络进行细粒度识别
为了缓解类内变化较大的问题,细粒度社区注重捕获细粒度对象具有辨别性的语义部分,然后再建立和这些语义部分相关的中级表征用于最后的分类。具体而言,研究人员为了定位这些关键部位,设计出了定位子网络。之后再连接一个用于识别的分类子网络。这两个子网络合作组成的框架就是第一个范式,也就是用定位分类子网络进行细粒度识别。
有了定位信息(比如部位边界框或分割掩码),就可以获得更有辨别力的中级(部位)表征。此外,它还进一步提高了分类子网络的学习能力,这可以显著增强最终识别的准确率。
属于这一范式的早期工作依赖于额外的密集部位注释(又称关键点定位)来定位目标的语义关键部位(例如头部、躯干)。它们中的一些学习了基于部位的检测器 [Zhang et al.,2014;Lin et al.,2015a],还有一些利用分割方法来定位部位。然后,这些方法将多个部位特征当做整个图像的表征,并将其馈送到接下来的分类子网络中进行最终的识别。因此,这些方法也称为基于部位的识别方法。
但这样的密集部位注释是劳动密集型工作,限制了细粒度应用在现实世界中的可扩展性和实用性。最近还出现了一种趋势,在这种范式下,更多只需要图像标签 [Jaderberg et al.,2015;Fu et al.,2017;Zheng et al.,2017;Sun et al.,2018] 就可以准确定位这些部位的技术出现了。它们共同的思路是先找到相对应的部位,然后再比较它们的外观。具体而言,我们希望能捕获到在细粒度类别中共享的语义部位(比如头部和躯干),同时还希望发现这些部位表征之间的微小差别。像注意力机制 [Yang et al.,2018] 和多阶段策略 [He 和 Peng,2017b] 这样的先进技术可以对集成的定位分类子网络进行复杂的联合训练。
4.2 用端到端的特征编码进行细粒度识别
和第一个范式不同,第二个范式是端到端特征编码,它是通过开发用于细粒度识别的强大深度模型来直接学习更具辨别力的表征实现的。这些方法中最具代表性的方法是双线性 CNN(Bilinear CNNs[Lin et al.,2015b]),它用来自两个深度 CNN 池化后的特征的外积来表征图像,从而对卷积激活的高阶统计量进行编码,以增强中级学习能力。由于其模型容量较高,双线性 CNN 在细粒度识别中实现了优良的性能。但双线性特征的维度极高,因此它无法在现实世界中应用,尤其是大规模应用。
最近也有一些尝试解决这一问题的工作,比如 [Gao et al.,2016;Kong 和 Fowlkes,2017;Cui et al.,2017],[Pham 和 Pagh,2013;Charikar et al.,2002] 试着用张量草图(tensor sketching)来聚合低维嵌入,该方法可以近似双线性特征,还可以保持相当程度或更高的准确率。其他工作,比如 [Dubey et al.,2018] 则专门为细粒度量身设计了特定的损失函数,它可以驱动整个深度模型学习具有辨别性的细粒度表征。
4.3 用外部信息进行细粒度识别
如前文所述,除了传统的识别范式外,另一种范式是利用外部信息(比如网络数据、多模态数据或人机交互)来进一步帮助细粒度识别。详细内容参见论文。
细粒度图像检索
除了图像识别,细粒度检索是 FGIA 的另一个重要方面,它也是当前的研究热点。在细粒度检索中,常用的评估指标是平均精度均值(mean average precision,mAP)。在细粒度图像检索中,给出同一个子类(比如鸟类或车类)的数据库图像和要查询的图像,它可以在不依赖任何其他监督信号的情况下,返回与查询图像属于同一类别的图像,如图 7 所示。
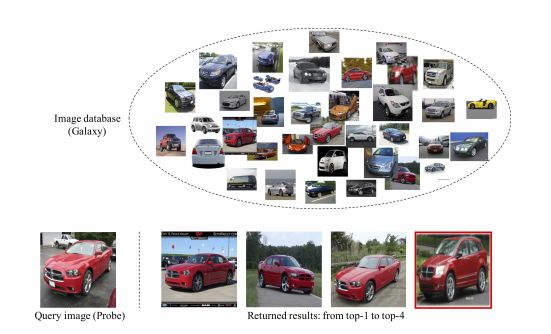
图 7:细粒度检索图示。
一般的图像检索是基于图像内容(比如纹理、颜色和形状)的相似性来检索非常相似的图像,而细粒度检索则侧重于检索属于同一类别(比如同一物种的生物或一种车型)的图像。同时,细粒度图像中目标的差别很小,而在姿势、尺寸以及角度等方面存在差异。
[Wei et al.,2017] 首次试着用深度学习进行细粒度图像检索。该模型用预训练的 CNN 模型,在无监督的情况下,通过在细粒度图像中定位主要目标选出了有意义的深度描述符,进一步揭示了只用去除背景或噪声的深度描述符可以显著提高检索任务的性能。为了打破通过预训练模型进行无监督细粒度检索的局限性,一些实验 [Zheng et al.,2018;Zheng et al.,2019] 倾向于在有监督指标学习范式下,研究出全新的损失函数。与此同时,他们还为细粒度目标量身设计了额外的特定子模块,例如,[Zheng et al.,2018] 受 [Wei et al.,2017] 启发后提出的弱监督定位模块。
细粒度图像生成
除了监督学习任务,图像生成也是无监督学习中的代表性主题。它用像 GAN[Goodfellow et al.,2014] 这样的深度生成模型来学习合成看起来很真实的逼真图像。随着生成图像的质量越来越高,更具挑战性的任务——细粒度图像生成,出现了。顾名思义,细粒度生成可以在细粒度类别(比如特定人物的面部或从属类别中的对象)中合成图像。
这方面的第一项工作是 [Bao et al.,2017] 提出的 CVAE-GAN,它将变分自编码器和条件生成过程下的生成对抗网络结合在一起,来解决这一问题。具体而言,CVAE-GAN 将图像建模成概率模型中的标签和隐含属性的组合。通过改变馈入生成模型的细粒度类别,它就可以生成特定类别的图像。最近,根据文本描述生成图像 [Xu et al.,2018b] 因其多样化和实用性(如艺术生成和计算机辅助设计)而流行起来。执行配备了注意力的生成网络后,模型可以根据文本描述中的相关细节来合成细微区域的细粒度细节。
与细粒度图像分析相关领域的特定应用
在真实世界中,基于深度学习的细粒度图像分析技术在不同领域中都得到了应用,并表现出了很好的性能,例如在推荐系统中检索衣服或鞋 [Song et al.,2017],在电子商务平台上识别时尚图像 [Wei et al.,2016] 以及在智能零售平台中识别产品 [Wei et al.,2019a] 等。这些应用都和 FGIA 的细粒度检索与识别高度相关。
此外,如果我们向下移动粒度范围,极端点说,也可以将人脸识别看作细粒度识别的实例,在这个例子中粒度降到了身份粒度级别之下。此外,人员或机动车的再识别也是细粒度的一项相关任务,这项任务的目标是确定两张图像是否属于同一个特定的人或机动车。显然,再识别任务的粒度等级也在身份粒度之下。
在实际应用中,这些工作都遵循了 FGIA 的思路,来解决相关领域的特定任务,FGIA 的思路包括捕获目标极具辨别性的部位(人脸、人和机动车)[Suh et al.,2018]、发现由粗到细的结构信息 [Wei et al.,2018b] 以及开发基于属性的模型 [Liu et al.,2016] 等等。
未来的方向
在这一部分,研究者明确指出了 FGIA 相关领域中尚未解决的问题,以及一些未来的研究趋势。
自动细粒度模型
AutoML 和 NAS 的最新方法在计算机视觉的各种应用中都取得了和手工设计架构相媲美、甚至更好的结果。因此,希望可以利用 AutoML 或 NAS 技术开发自动细粒度模型,有望找到更好、更合适的深度模型,同时也可以反向促进 AutoML 和 NAS 研究的进步。
细粒度 few-shot 学习
我们最好的深度学习细粒度系统需要成百上千个标记好的样本。更糟的是,细粒度图像的监督不仅耗时而且昂贵,因为细粒度目标是由该领域的专家做准确标记的。因此,现实应用迫切需要开发出基于小样本的细粒度学习方法(fine-grained few-shot,FGFS)[Wei et al.,2019b]。FGFS 任务需要学习系统以元学习的方式,根据少量(只有一个或少于五个)样本构建针对全新细粒度类别的分类器。鲁棒的 FGFS 方法可以很大程度上地增强细粒度识别的可用性和可扩展性。
细粒度哈希
在像细粒度图像检索这样的实际应用中,会自然地出现这样的问题——在参考数据非常大的情况下,找到准确的最近邻的成本是非常高的。哈希 [Wang et al.,2018;Li et al.,2016] 是近似最近邻搜索中最流行也最有效的技术之一,它有处理大量细粒度数据的潜力。因此,细粒度哈希是 FGIA 中值得进一步探索的方向。
在更实际的环境中进行细粒度分析
细粒度图像分析还有许多新颖的主题——用域自适应进行细粒度分析、用知识迁移进行细粒度分析、用长尾分布进行细粒度分析以及在资源受限的嵌入设备上运行细粒度分析等。这些更高级也更实际的 FGIA 都很值得进行大量的研究工作。
-完-








