
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好 适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。去年,在100 TB Daytona GraySort比赛中,Spark战胜了Hadoop,它只使用了十分之一的机器,但运行速度提升了3倍。Spark也已经成为针对 PB 级别数据排序的最快的开源引擎。
Spark支持Scala、Java、Python、R等接口,本文均使用Python环境进行学习。
Spark在Windows下的环境搭建
https://blog.csdn.net/u011513853/article/details/52865076
https://www.jianshu.com/p/ede10338a932
pyspark官方文档http://spark.apache.org/docs/2.1.2/api/python/index.html
基于PySpark的模型开发
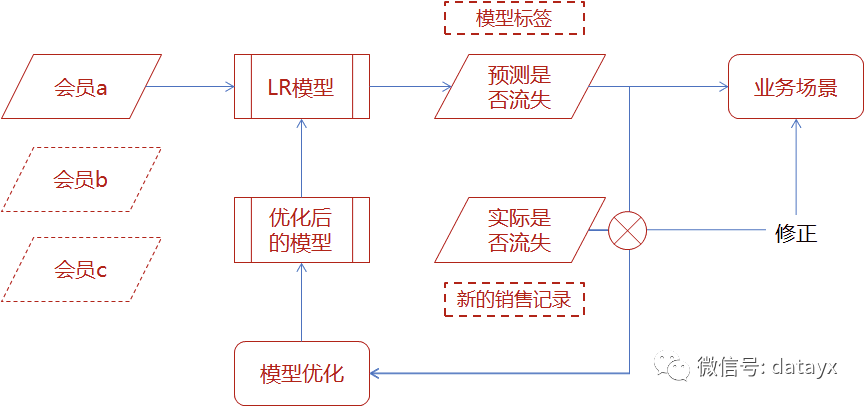
会员流失预测模型
通用模型开发流程
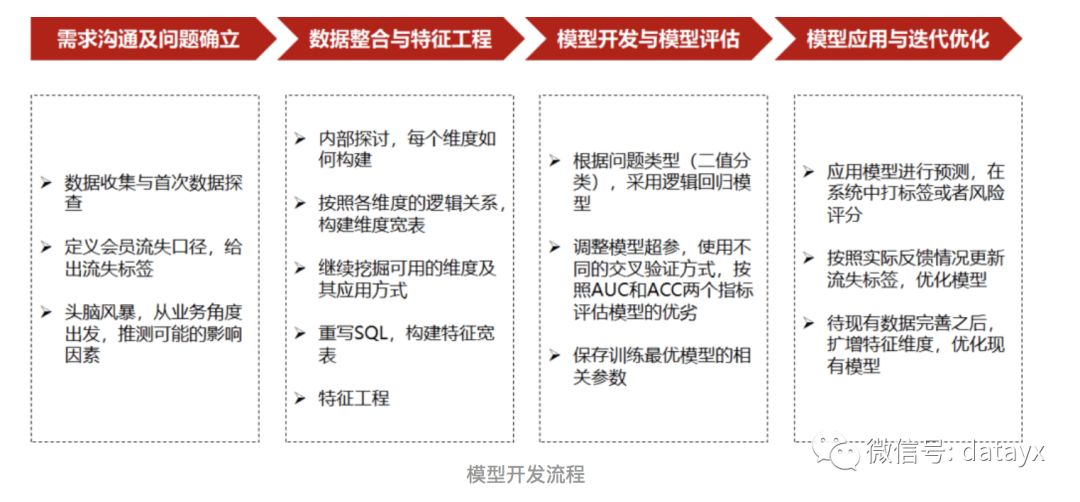
需求沟通与问题确立
定义流失口径:比如,流失客户定义为最近一次购买日期距今的时间大于平均购买间期加3倍的标准差;非流失客户定义为波动比较小,购买频次比较稳定的客户
选定时间窗口:比如,选择每个会员最近一次购买时间回溯一年的历史订单情况
推测可能的影响因素:头脑风暴,特征初筛,从业务角度出发,尽可能多的筛选出可能的影响因素作为原始特征集
数据整合与特征工程
1)把来自不同表的数据整合到一张宽表中,一般是通过SQL处理
2)数据预处理和特征工程

模型开发与效果评估
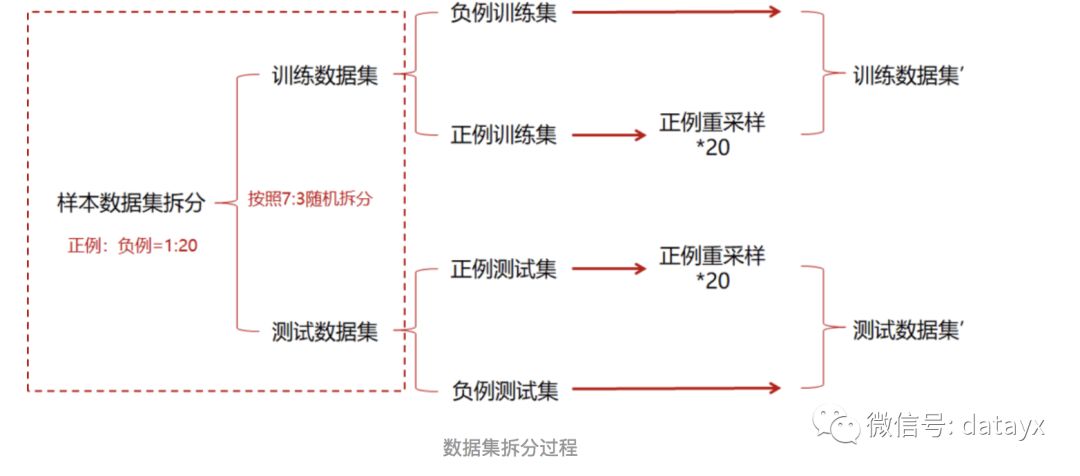
1)样本数据先按照正负例分别随机拆分,然后分别组成训练和测试集,保证训练集和测试集之间没有重复数据,训练集和测试集正负例比例基本一致,最终两个数据集中正负例比例均接近1:1
2)对于建立模型而言并非特征越多越好,建模的目标是使用尽量简单的模型去实现尽量好的效果。减少一些价值小贡献小的特征有利于在表现效果不变或降低很小的前提下,找到最简单的模型。
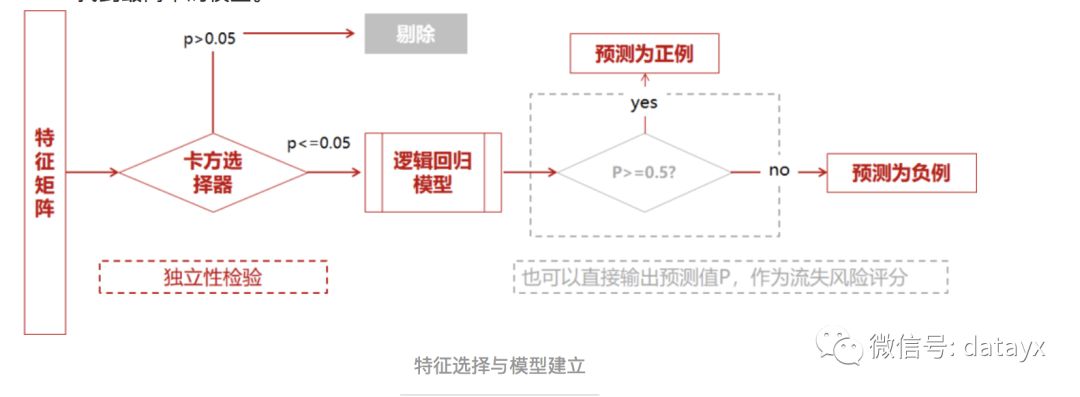
使用卡方检验对特征与因变量进行独立性检验,如果独立性高就表示两者没太大关系,特征可以舍弃;如果独立性小,两者相关性高,则说明该特征会对应变量产生比较大的影响,应当选择。
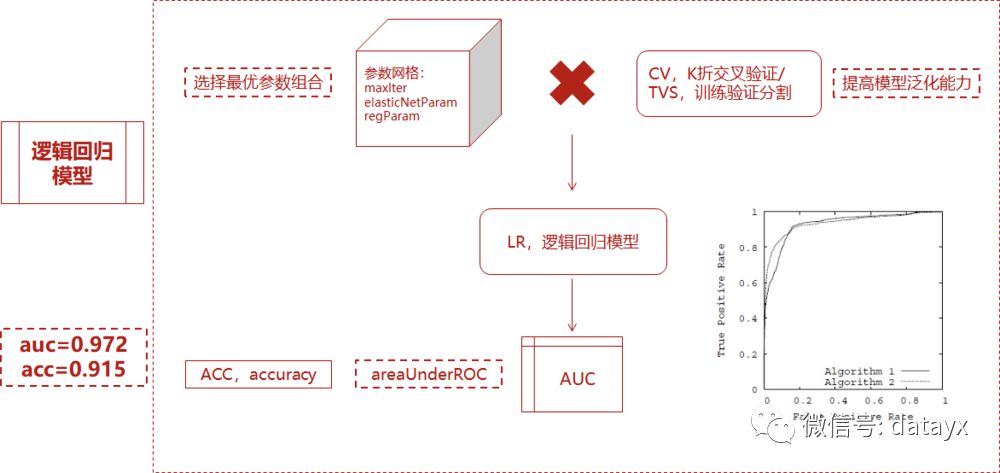
3)CV或者TVS将数据划分为训练数据和测试数据,对于每个(训练,测试)对,遍历一组参数。用每一组参数来拟合,得到训练后的模型,再用AUC和ACC评估模型表现,选择性能表现最优模型对应参数表。
模型应用与迭代优化
应用模型预测结果/评分进行精细化营销或者挽回,同时不断根据实际情况优化模型,再用优化后的模型重新预测,形成一个迭代优化的闭环。
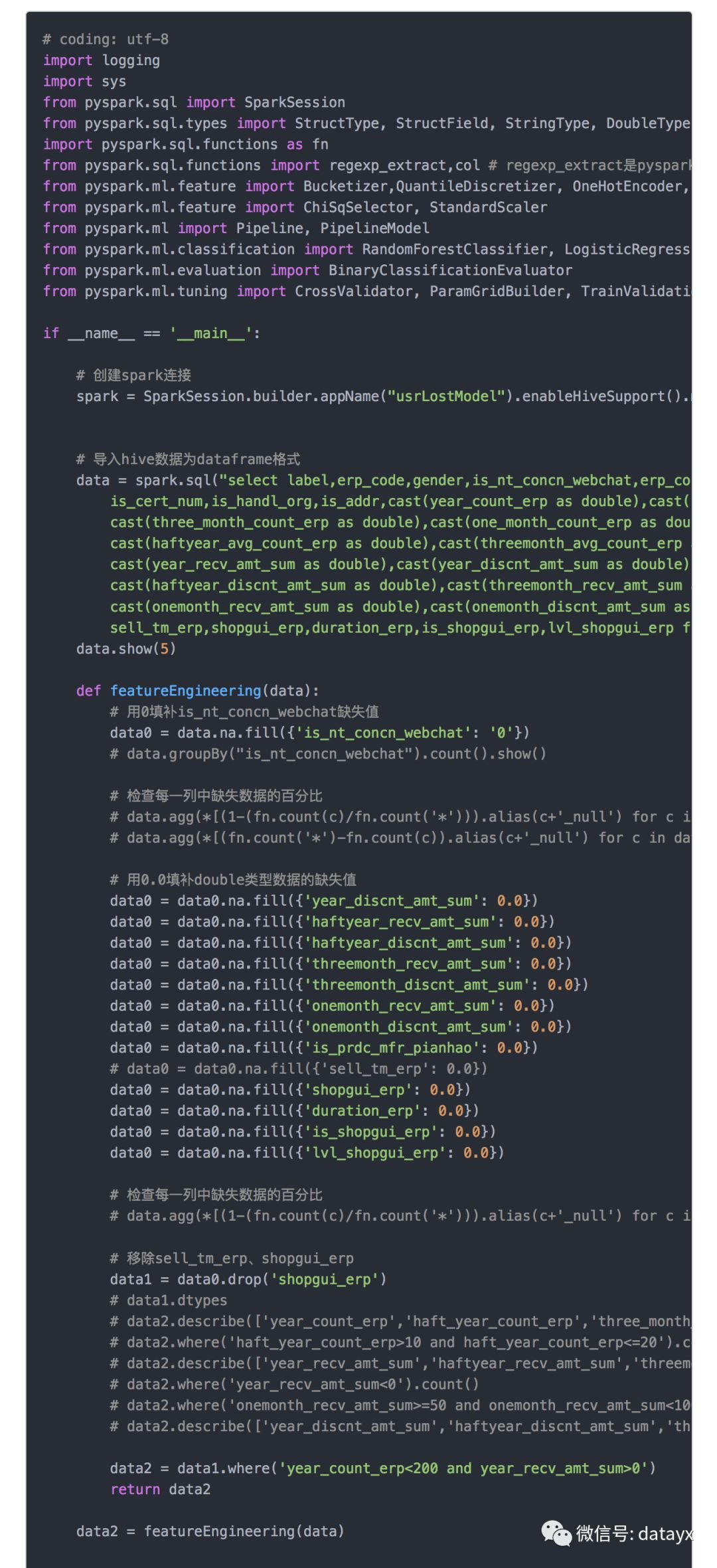
模型代码
附1:本地开发的Python代码
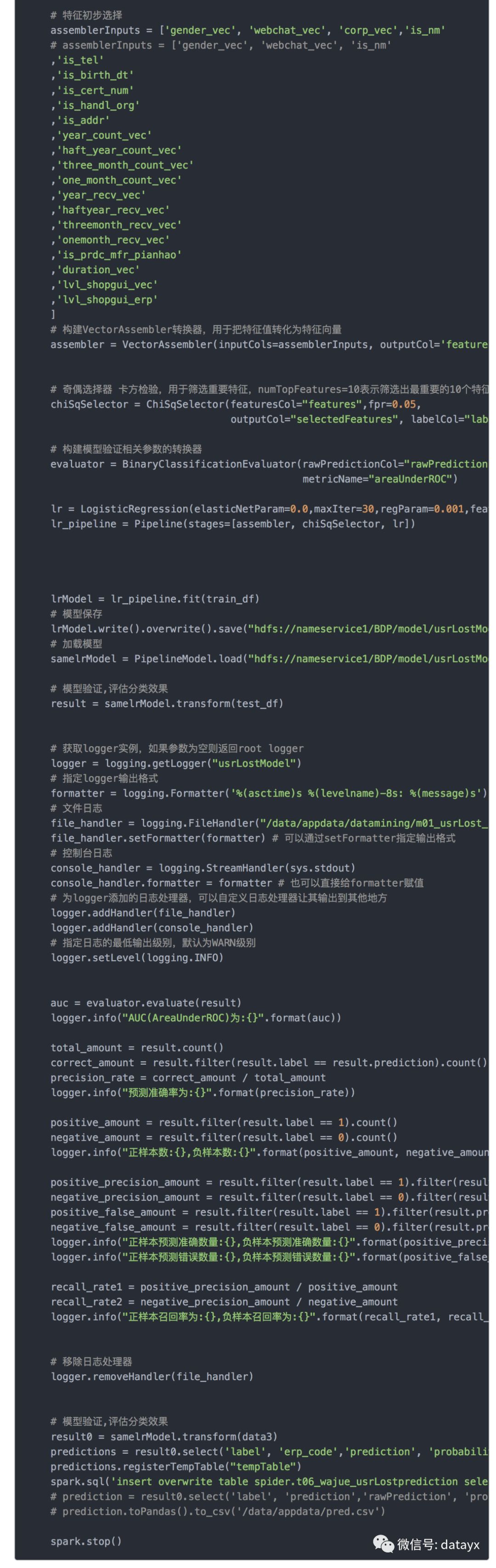
地址 https://www.jianshu.com/p/5a5fc30a7a70
阅读过本文的人还看了以下:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech












