(给算法爱好者加星标,修炼编程内功)
编译:机器之心,作者:Jean-Louis Queguiner
神经网络就像数数一样简单」,「卷积层只是一个蝙蝠信号灯」……在本文中,一位奶爸从手写数字识别入手,用这样简单的语言向自己 8 岁的女儿解释了一下「深度学习」。当然,用这篇文章向女朋友(如果有的话)科普自己的工作也是可以的。
机器学习,尤其是深度学习是一个热门话题,你肯定会在媒体上看到流行语「人工智能」。
然而,这些并非新概念。第一个人工神经网络(ANN)是在 40 年代引入的。那么为什么最近的热点话题都是关于神经网络和深度学习的呢?我们将在 GPU 和机器学习的一系列博客文章中探讨这些概念。
在 80 年代,我记得我父亲构建了用于银行支票的字符识别工具。检查这么多不同类型的笔迹真的是一件痛苦的事,因为他需要一个方程来适应所有的变化。
在过去几年中,很明显,处理这类问题的最佳方法是通过卷积神经网络。人类设计的方程不再适合处理无限的手写模式。让我们来看看最经典的例子之一:构建一个数字识别系统,一个识别手写数字的神经网络。
我们首先计算最上面一行的红色形状在每个黑色手写数字中出现了几次。
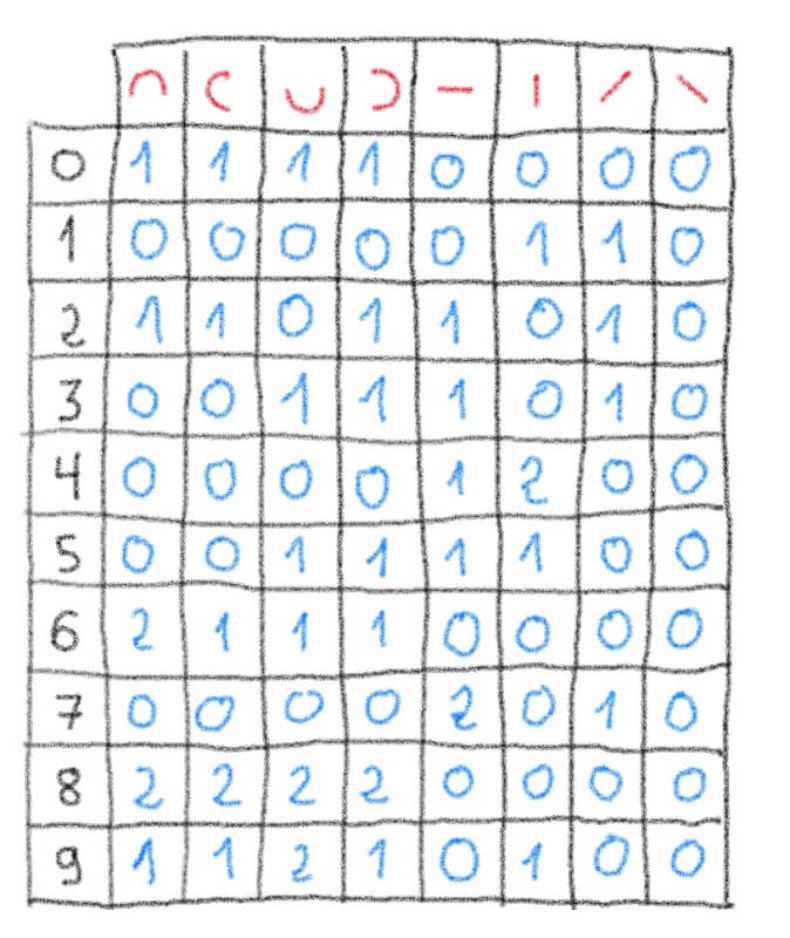
现在让我们尝试通过计算具有相同红色形状的匹配数来识别(推断)新的手写数字。然后我们将其与之前的表格进行比较,以确定这个数字与哪个数字有最强的关联:
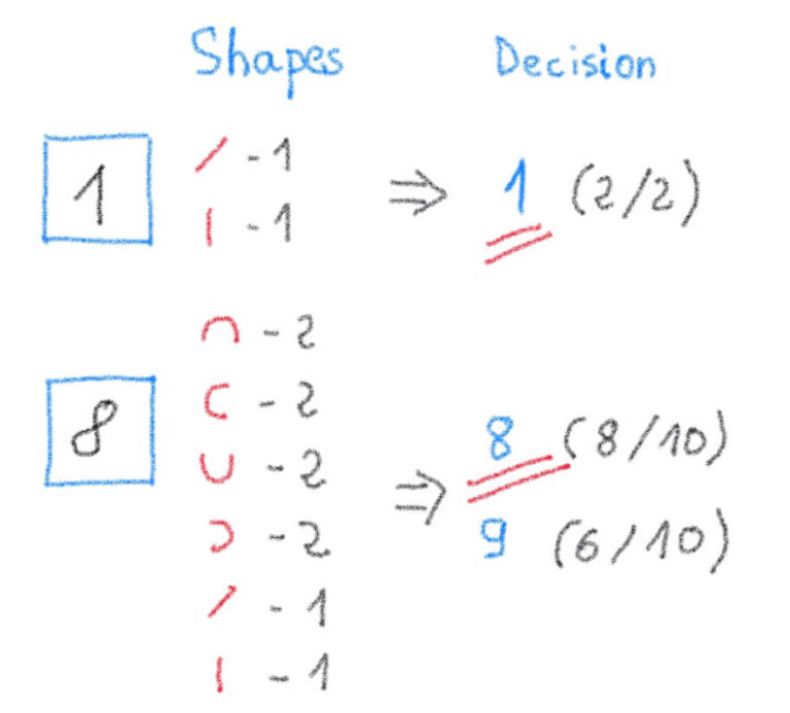
恭喜!你刚刚构建了世界上最简单的神经网络系统,用于识别手写数字。
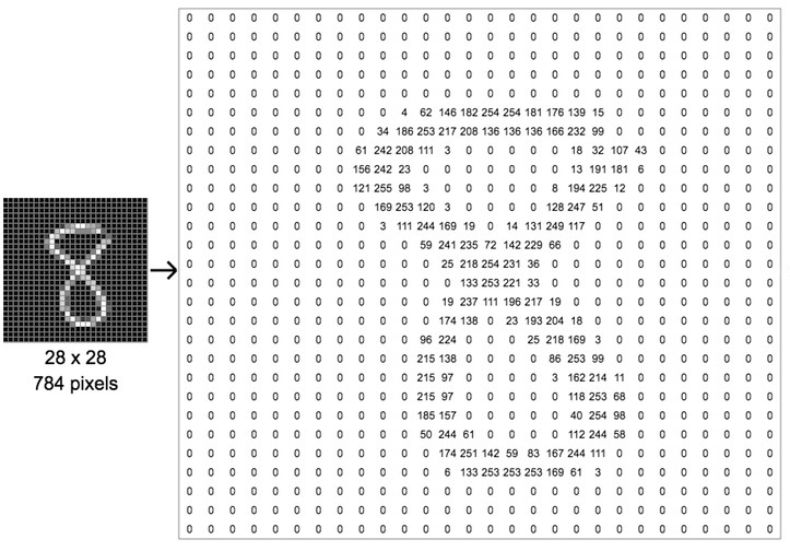
计算机将图像视为矩阵。一张黑白图像是个 2D 矩阵。
我们来考虑一张图像。为了简单起见,我们拍摄一张数字 8 的小黑白图像,方形尺寸为 28 像素。矩阵的每个单元表示从 0(表示黑色)到 255(表示纯白色像素)的像素强度。
为了确定图片中显示的图案(此处指手写数字 8),我们将使用一种蝙蝠信号灯/手电筒。在机器学习中,手电筒被称为过滤器(filter)。该过滤器用于执行 Gimp 等常见图像处理软件中用到的经典卷积矩阵计算。

过滤器将扫描图片,以便在图像中找到图案,并在匹配成功时触发正反馈。它有点像儿童形状分类盒:三角形过滤器匹配三角形孔,方形过滤器匹配方孔等。

更科学地来讲,图像过滤过程看起来有点像下面的动画。如你所见,过滤器扫描的每个步骤都是相互独立的,这意味着此任务可以高度并行化。
要注意,数十个过滤器将同时运行,因为它们不相互依赖。
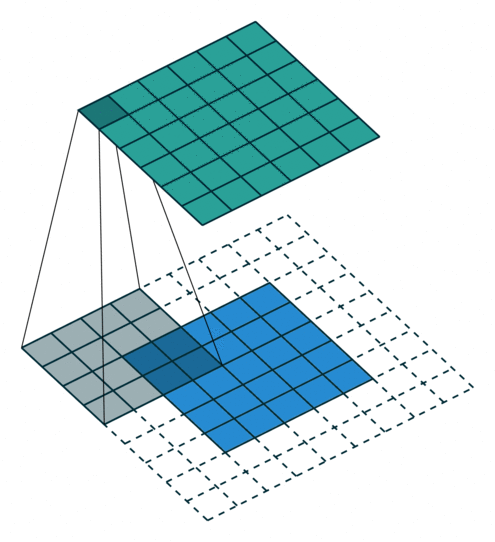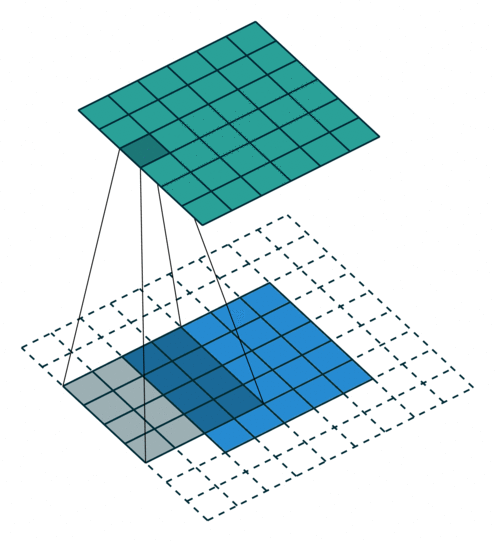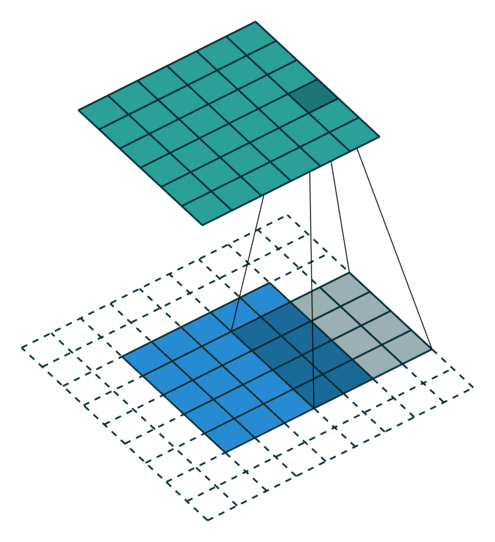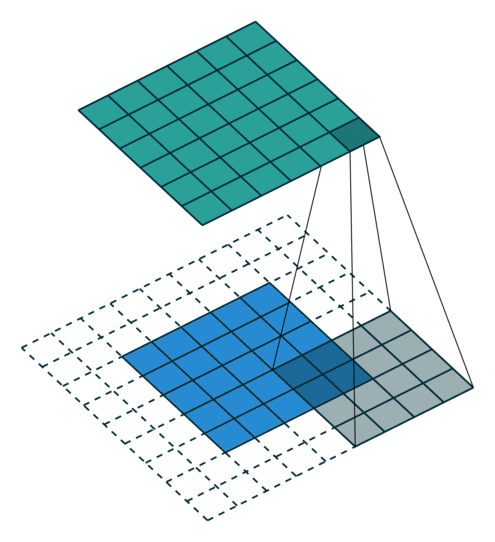
https://github.com/vdumoulin
我们刚刚看到,输入图像/矩阵使用多个矩阵卷积进行过滤。
为了提高图像识别的准确率,只需从前一个操作中获取过滤后的图像,然后一次又一次地过滤......
当然,我们过分简化了一些事情,但通常你使用的过滤器越多,按顺序重复这个操作的次数越多,你的结果就越精确。
这就像创建新的抽象层以获得更清晰的对象过滤器描述,从原始过滤器到看起来像边缘、轮子、正方形、立方体等的过滤器......
一图胜千言:下图是使用卷积过滤器(3×3)过滤的源图像(8×8)的简化视图。手电筒(此处为 Sobel Gx 过滤器)的投影提供一个值。
 应用于输入矩阵的卷积过滤器(Sobel Gx)示例(来源:https://datascience.stackexchange.com/questions/23183/why-convolutions-always-use-odd-numbers-as-filter-size/23186)
应用于输入矩阵的卷积过滤器(Sobel Gx)示例(来源:https://datascience.stackexchange.com/questions/23183/why-convolutions-always-use-odd-numbers-as-filter-size/23186)
这就是这种方法的神奇之处,简单的矩阵运算是高度并行化的,完全符合通用图形处理单元的用例。
事实 7:需要简化和总结检测到的内容吗?只需使用 max()
我们需要总结过滤器检测到的内容,以便学到概括性的知识。
此操作称为池化或下采样,但实际上它是为了减小矩阵的大小。
你可以使用任何缩小操作,例如:最大化,最小化,取平均值,计数,取中位数,求和等等。
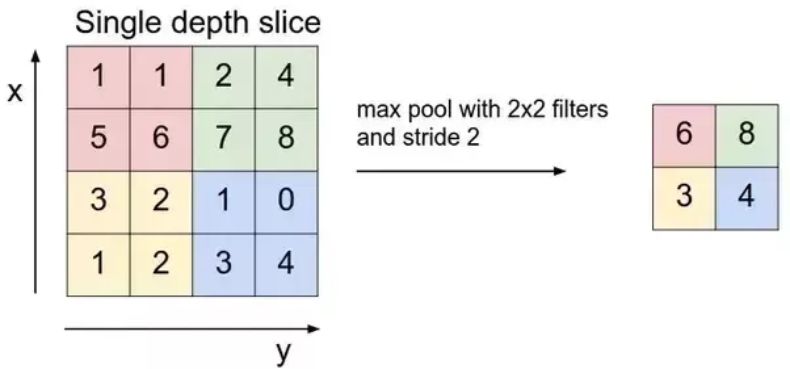
不要忘记我们正在研究的神经网络的主要目的:建立一个图像识别系统,也称为图像分类。
如果神经网络的目的是检测手写数字,那么输入图像最后将被映射到 10 个类:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]。
要在通过所有这些过滤器和下采样层之后,才将此输入映射到类,我们将只有 10 个神经元(每个神经元代表一个类),每个神经元将连接到最后一个子采样层。
以下是由 Yann Lecun 设计的原始 LeNet-5 卷积神经网络的概述,他是早期采用该技术进行图像识别的人之一。
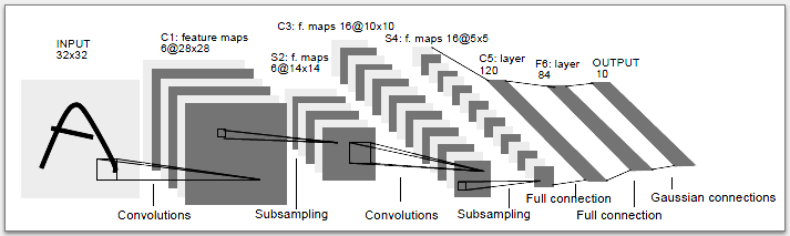
原始论文中的 LeNet-5 架构(来源:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf)
技术之美不仅来自卷积,而且来自网络自身学习和适应的能力。通过实现名为反向传播的反馈回路,网络将使用权重来减轻和抑制不同层中的一些「神经元」。
我们来看看网络的输出,如果猜测(输出 0, 1, 2, 3, 4, 5, 6, 7, 8 或 9)是错误的,我们要看一下是哪个/些过滤器「出了错」,找到之后,我们给这个/些过滤器一个小小的权重,这样它们下次就不会犯同样的错误。瞧!系统在学习并不断改进自己。
提取数千个图像,运行数十个过滤器,采用下采样,扁平化输出...... 所有这些步骤可以并行完成,这使得系统易于并行。它只是 GPGPU(通用图形处理单元)的完美用例,非常适合大规模并行计算。
当然这有点过于简单化,但如果我们看一下主要的「图像识别竞赛」,即 ImageNet 挑战,我们就可以看到错误率随着神经网络的深度增加而降低。人们普遍认为,排除其他因素,网络深度的增加将带来更好的泛化能力和准确性。
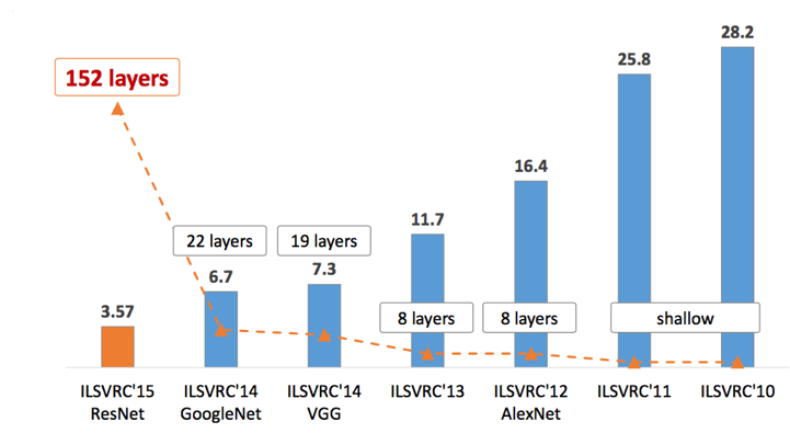
Imagenet 挑战赛获胜者错误率 VS 网络中的层数(来源: https://medium.com/@sidereal/cnns-architectures-lenet-alexnet-vgg-googlenet-resnet-and-more-666091488df5)
我们简要介绍了应用于图像识别的深度学习概念。值得注意的是,几乎所有用于图像识别的新架构(医疗、卫星、自动驾驶......)都使用相同的原理,只是具有不同数量的层,不同类型的滤波器,不同的初始化点,不同的矩阵大小,不同的技巧(如图像增强、dropout、权重压缩...)。概念都是一样的:
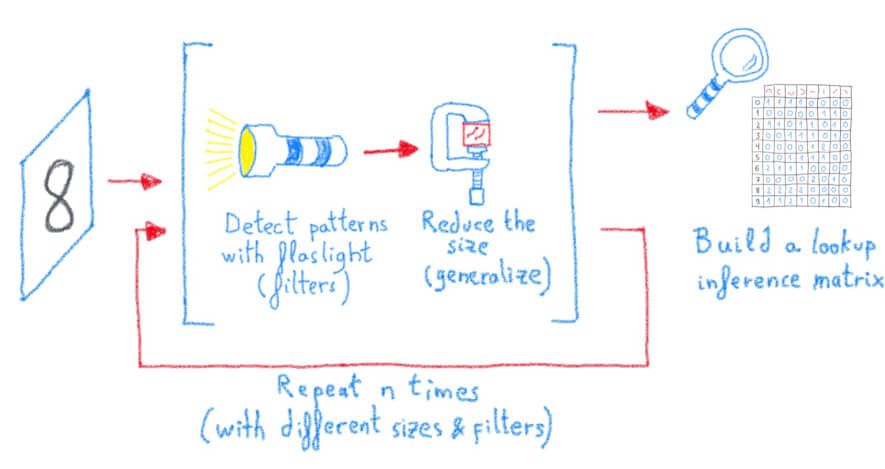
深度学习模型的训练和推理可以归结为并行完成的大量基本矩阵运算,确切地说,这正是我们已有的图形处理器(GPU)的用途。
参考链接:https://www.ovh.com/blog/deep-learning-explained-to-my-8-year-old-daughter/
觉得本文有帮助?请分享给更多人
关注「算法爱好者」加星标,修炼编程内功

好文章,我在看❤️









