大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由智亿同学与政委联合推出。
上一节(戳这里)通过火锅团购数据学习了:
如何使用Pandas读入csv、excel文件;
如何使用Pandas过滤重复值、缺失值。
这一节我们继续来学习Pandas这个神器的其他武功:
学习如何使用Pandas进行切片操作;
学习如何进行统计描述分析;
同时介绍一些常用技巧。
首先,咱们假设用Pandas已经读入数据,并且完成了去重与去缺失值(参见上一节)。现在存储的数据名字为raw_data2。
一般情况下“人均”字段里正常情况下只能填100, 200这类数字,但是还偏偏有人填了“人均:100”。你可能要问了,怎么还有“这么贴心”的店家?还别说,真有,大部分店家都“这么贴心”。请看商户信息的第二行与第五行。
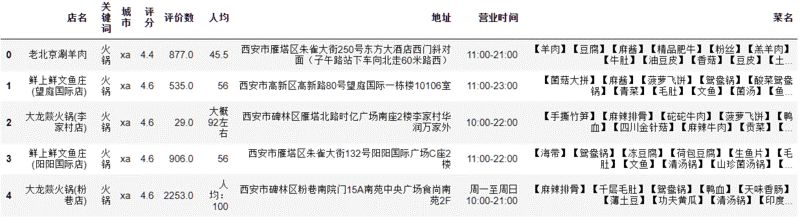
你可能第一反应是:”Pandas判断表达式“。严格来说,这没错。但是,如果又冒出来”人均100“,”大概100左右“,”差不多100“,这就没法用Pandas判断表达式了。这类表达式只能用“==”,“>=”,“>”,“<=”, “
为简单起见,在这一小节只能先采用切片函数,再调用for循环+if判断的方式对上面提到的几种情况进行筛选,在后面的小节,我们将采用【apply()函数 + re正则表达式】进行处理。
表3.1-4-1 切片函数
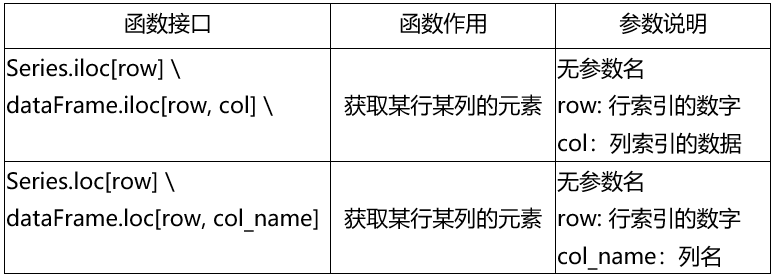
类似于Python内置list类型,Pandas的切片操作也可以指定切片的起始位置或只指定其一。
首先,用上述切片函数查看一下“人均”这一列到底怎么了?
1s1_average = raw_data2.loc[1,'人均']
2print(type(s1_average))
3s2_average = raw_data2.loc[2,'人均']
4print(type(s2_average))
其次,通过返回值应该理解raw_data2中的“人均”这一列用的是Series存储的。数字的地方用float的类型,而有特殊字符的地方用str类型存储。那么下面就来重新清洗“人均”这一列吧。
例1 切片操作
1filter_words = ['人均:', '人均', '大概', '左右', '差不多'] #定义需要过滤的词
2for i in range(len(raw_data2)):
3 value = raw_data2['人均'].iloc[i] #取出人均这一行中的值
4 if type(value) is int or type(value) is float:
5 continue #判断该值是否为整数或者浮点类型数字,如果满足则跳过进入下一步
6 for word in filter_words:
7 if word in value: #判断需要过滤的词是否在value中,如果在则去除
8 raw_data2.loc[i, '人均'] = raw_data2.loc[i, '人均'].replace(word, '')
9
10raw_data2.head()
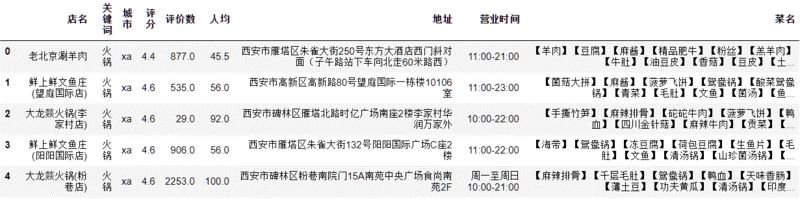
图1
在这里,我们使用了Pandas的iloc和loc方法来选取每一行的元素,再对其进行类型判断,如果为int或者float类型,说明不存在错填的情况,直接continue,对于错误值,采用Python的字符串原生方法replace()替换。
一点题外话,使用【切片函数+for循环+if判断】的方法实现方式并不Pythonic,不建议轻易采用。更推荐采用【apply() 函数 封装for循环 + if判断】的方法,不但更Pythonic,速度也更快。这种方法在后面的章节中会提到。
这一小节中,我们讨论:
astype()函数
使用describe()函数
其他描述性统计函数
表2 其他函数
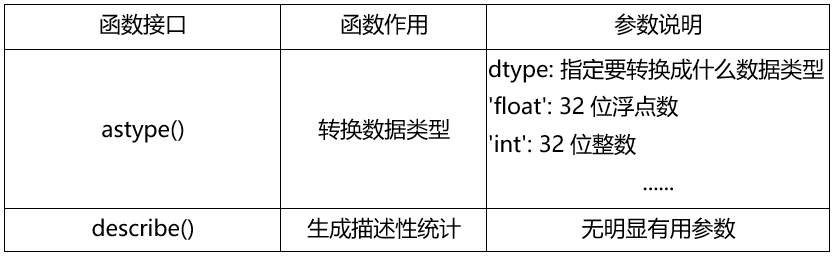
例2 其他函数
1raw_data2['人均'] = raw_data2['人均'].astype(float)
2raw_data2.describe()
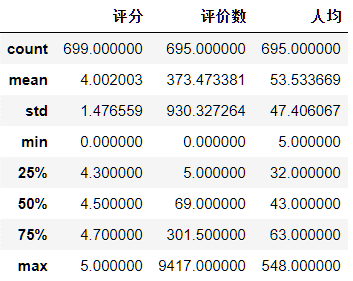
图2 描述性统计
注意,由于在之前小节,“人均”字段中存在冗余的字符串,因此,Pandas在读入数据时会把所有数据都当做字符串处理,调用describe()之前需要转换成float类型。调用describe()可以很方便地观察数据的均值、标准差、最大最小值、四分位数等基本情况。
完整的Pandas统计方法见表3。
表3 其他可直接调用的方法

其他简单操作还包括:
1# 选择其中一列元素
2raw_data2[column1]
3
4# 选择两列元素
5raw_data2[[column1, column2]]
6
7# 选择评分大于3.5分的商家所有信息
8raw_data2[raw_data['评分'] > 3.5]
9
10# 打印所有列名
11
raw_data2.columns
12
13# 打印所有行索引
14raw_data2.index
15
16# 得到每一行的所有值
17raw_data2.values
18
19# 人均这列所有元素加100
20raw_data2['人均'] + 100
21
22# 按“人均”排序,从小到大
23raw_data2.sort_values(['人均'], ascending=True)
24
25# 按index排序
26raw_data2.sort_index()









