点击上方“Datawhale”,选择“星标”公众号
第一时间获取价值内容

从“价值、必要、讨论和工具”这四个角度,把一些容易踩的坑提示给你,助你顺利完成研究论文撰写。
挫折
我的一个三年级研究生,最近比较焦虑。
焦虑的原因,是预答辩的效果不理想。
最重要的原因,你肯定能猜到,是他拖延症犯了。不到最后一刻,也不肯交出初稿,说要继续修改(其实是一直没写完)。最后一行字刚落笔,就直接去预答辩了。装备都没配齐全,就冲入了枪林弹雨的战场,后果可想而知。
但是,他的焦虑,目前主要来自于另外一个方面,就是面对批评意见,一时有些懵。
我在文中不止一次描述过这种“文科生”——没有IT技术背景,本科专业属于文科类,硕士毕业论文用技术手段解决应用问题。
他的研究中,就使用了机器学习中的监督式方法,对社交媒体文本是否包含隐私内容,进行了分类训练。在验证集上,准确率和F1分数,都为60%多。
这几年,他在我的鼓励下,不断学习数据科学相关教程。
他看到了自己的进步,信心越来越强。从前认为永远无法企及的机器学习方法,现在会用了;从前面对数据无从下手,想不到解决思路,现在水到渠成。而且因为学习MOOC,英文和数学能力也有了提升。所以,预答辩之前,他对自己论文的评价预期很高。
他没有想到,自己的论文居然存在这么多的严重问题。一时感到很是沮丧和挫折。
我把老师们给他提出的意见,在这里列出来:
你使用了机器学习的方法,但只是调用了已经标准化的工具(scikit-learn)而已。文中对工具本身和使用方法做了过于细致的描述,却并没有体现出自己的技术改进;
你对机器学习的使用,满足于做出一个分类的结果,就如同做了一个项目作业一样,缺乏深入的讨论;
你的分类效果,只有60%多的准确率,远不及人工水平。这样的结果,是否有价值?
你的流程参考了一篇英文文献对Twitter文本的隐私分类。人家已经探索了,在英文文本上自然语言处理可以分类隐私曝露程度。那你这份研究,无非是从英文换成了中文而已,是否还有必要性?
老师们的说法,是委婉而克制的。我翻译了一下,就是说这篇论文“工具化、缺讨论、无价值、没必要”。
现在,你明白为什么他要焦虑了吧?
这样下去,连毕业都堪忧。
对于拖延,他很愧疚。给我写了一份长长的检查,读来还算实事求是。
亡羊补牢,为时未晚。
我于是帮他分析了目前存在的问题,以及对应的修改策略。下文我会一并分享给你。
你可能会奇怪——老师,这东西针对你学生问题写的,为什么要分享出来呢?
因为自从我开始在网上写数据科学教程以来,收获了许多读者的反馈。从这些反馈中,我看到了来自许多专业的同学,特别是那些“文科生”,都在努力掌握机器学习方法,并且应用到自己的研究,甚至是毕业论文中。
而与此同时,从指导研究生,参加开题答辩、学术论坛,以及给期刊审稿的过程里,我也发现,许多这样应用了数据科学,特别是机器学习方法的研究,做出来的结果,也多会存在同类问题,让人有类似的质疑。
很多时候,问题并非来自于研究本身缺乏价值。而在于作者在写作的过程中,抓不住重点,不知道应该着重汇报和讨论哪些东西,导致了很多的误解。
如果你也有计划,把机器学习应用在自己的研究论文里,我觉得后面的内容,可能会对你有帮助。
下面针对他论文里面存在的问题,我分别谈以下4个方面:
细心的你,一定注意到了,咱们这里的内容,和老师们提出问题是相呼应的,但是顺序并不一致。
为什么呢?
希望读完全文之后,你能自己体悟到这个顺序的意义。
价值
咱们先说说价值。
研究价值,是一篇论文的灵魂。文字写得再精妙,如果没有研究价值,也不值得做。
更为详细的论述,请你参考我那篇《什么样的开题报告会被毙掉?》。
这里涉及到一个具体的价值评判标准问题:如果机器分类效果,比不上人工水平,那么值不值得做?
直觉会第一时间告诉你——不值得啊!既然人可以做得更好,就让人做呗。只有机器性能超越了人类,研究成果才值得发表嘛!
但是,仔细想想看,这种论断,不仅和学术界的共识不同,也违背你的常识。
你叫来一个人,让他分辨一张照片是猫还是狗。他会觉得小菜一碟,准确率也会很高。
反之,你让机器来判别猫和狗。即便是目前最尖端的计算机视觉技术,也会出现在人类看来,非常显而易见的疏漏。
你可能会因此对机器的“智能”嗤之以鼻。
且慢。
刚才的情境,只是去分辨一张照片。对吧?
十张八张呢?似乎也没问题啊。
可假如,你让这个人分辨一千万张照片呢?
他扭头就跑了,对不对?
因为这个任务,不仅繁重,而且枯燥,机会成本太高。
有做这件事的时间,他可以做很多更有意义和趣味的活动。
机器的好处,这时候就体现出来了。它任劳任怨,不知疲惫,运算速度还快。可以帮我们在很短的时间内,完成成千上万张照片的分辨结果。
你说分析这么多张照片,真的有用吗?
当然有。往远了说,你可以看看电影《少数派报告》,了解一下大规模图片分析的前景。往近了说,你可以回顾一下新闻,看看那些过马路闯红灯的行人,是如何立即连同个人信息,被展示在大屏幕上的。
这就是人和机器的区别。我们懒,我们喜欢精彩,不喜欢重复。发明机器,让它们替我们做自己不愿意从事的工作。哪怕机器做的,不如自己做得好,我们也能忍受。或者说,也得选择忍受。
你现在做的这个研究,是通过机器学习的方法,来辅助用户判断,他即将发布的信息是否包含隐私,并且进行提醒,防患于未然。
一个主流社交媒体平台,每天要有多少人发信息?每一条信息都让人来帮你判断是否包含隐私,来得及吗?靠谱吗?谁又能来支付这么庞大的成本?
而且,你立即想到了一个更大的不妥吧。
对,你要发布的内容,如果包含了隐私,却已经被平台雇佣的审核人员一览无余,预先看了去。那还何谈隐私保护呢?
所以你看,这个任务,交给计算机来做,比交给人来做,靠谱许多。
因此,在你的研究中,把分类效果与人工水准进行对比,没有必要,也没有道理。
但是人工分类水准却不可不提,它应该出现在你的数据标注环节。
监督学习是需要训练数据的,即数据要有标签。这些标签,是人打上去的。人标注的准确率,直接关系到你的数据质量。马虎不得。
你训练的模型,分类效果如果不跟人比,那跟谁比呢?
跟别人的模型比吗?
要对比别人的模型,前提有两个:
假设别人的模型,准确率做到了70%,那么你即便做到69%,也别写了。因为没有价值。
但是,每一个学科领域,甚至是具体的研究问题,如果要应用机器学习监督分类,都会有第一篇文献,对吧?这可算作是探索性研究。
这样的研究,该跟谁去比呢?
通例是,跟一个空模型(null model)去对比。
什么是空模型?
还记得许多教科书里面,告诉你对数据要做平衡分类吗?就是二元分类任务,训练集和测试集里面,都是50%猫,50%狗。
你可能一直约定俗成也这样做。但是为什么?
现在原因就呼之欲出了。
这么做,你可以很容易构造空模型。
所谓空模型,就是在猫狗分类中,不分青红皂白,也不去分析图片特征,把所有的样本都猜测成“猫”(或者全都猜成“狗”)。这就是一本正经地乱猜。
想想看,这样的空模型,准确率是多少?
当然一定是50%了。不会更高,却也不会更低。稳定得很啊。这个数值,也称作随机基线准确率(Random Baseline Accuracy)。
好了,你就跟它比。
只要比空模型好,就意味着你的模型存在意义,因为看起来,它从样本的特征中把握到了有用的信息,比瞎猜强。
注意,这里你要通过完整的规范论述流程,排除随机性的影响。后文会有详细说明。
看到没有,只要你的模型,是这个细分领域中的第一个,那你就不需要跟别人的模型,锱铢毫厘去争短长。
这也是为什么,我一直对你的拖延症有意见。
科研活动不是一次散步,可以让你从容游览把玩。它是一场赛跑。跑到第一个,你只需要跟空模型比。你的研究,会被赋予开创性、探索性的标签。而且很有可能,因为这种先发优势,被后续许多研究引用,让你获得与自己的实际投入并不相称的学术声誉。这是典型的“低垂果实”,也叫做“甜买卖”。
而一旦跑慢了,成了第二名进入者。那不好意思,你就只能沦落到和别人去比了。如果你研究的,是一个很有价值的问题,那即便你拼尽全力,让自己的结果短暂领先。人们也几乎可以断言,你很快就会被后来者超越和淹没。而且这些后来者会不会记得引用你的成果?难说。
你做的到底是开创性,还是探索性研究?
这个问题,只有你自己才能回答。因为你系统梳理过文献啊。在中文社交媒体文本上进行隐私分类,别人做过了吗?
你当时告诉我说,没有。
我相信你,认为你说的是事实。
然而,我必须提醒你注意,事实是在不断变化的。
一年前,你开题的时候,没人做;并不代表一年后的今天,也没人做。所以,你得不断跟踪研究进展。万一很不妙,因为你手慢,已经有人做了。那你的研究,就不是探索性研究了。和空模型对比,就不再合适。你必须转而正面迎战,和别人的结果去对比。想尽一切办法提升模型效果,形成竞争优势。
如果遇到这种情况,你大概会叹息自己的运气糟糕。但是,那也是没有办法的事。谁让你拖延呢?你不该做的,是“选择性失明”,假装视而不见。要知道掩耳盗铃,可是大错特错,直接会影响别人对你学术品德的判断。
必要
因为被批评后信心不足,于是你开始怀疑自己。你说虽然自己做的是中文文本隐私分类,之前文献回顾中,没见到有人做。但是英文文本隐私分类不仅有人做过,而且你还参考了人家的流程步骤。那么自己的研究是否有必要性?
如果你在这一点上,质疑自己的研究,我只能说,你对机器学习的本质,还没有充分领悟。你对数据分类的理解,还停留在 software 1.0 阶段。
什么叫做 software 1.0 ?这是 Andrej Karpathy 提出的概念。
解决一个问题,software 1.0的手段,是人来设计算法,机器照章执行。
所以,它即便再高妙,也不可能超越人的思维局限。它的复杂度,也就到那儿了。
例如前几天有个刷屏的游戏,据说是中文系毕业的人做的。因为程序员跑路,这位仁兄不得不亲自上阵。因为缺乏算法基础知识,所以他自己手写了几十万个 if 语句。这样居然还没有 bug !听起来非常励志。
励志归励志,但是所有 software 1.0 程序的复杂度,和基于机器学习的 software 2.0 一比,差距高下立判。
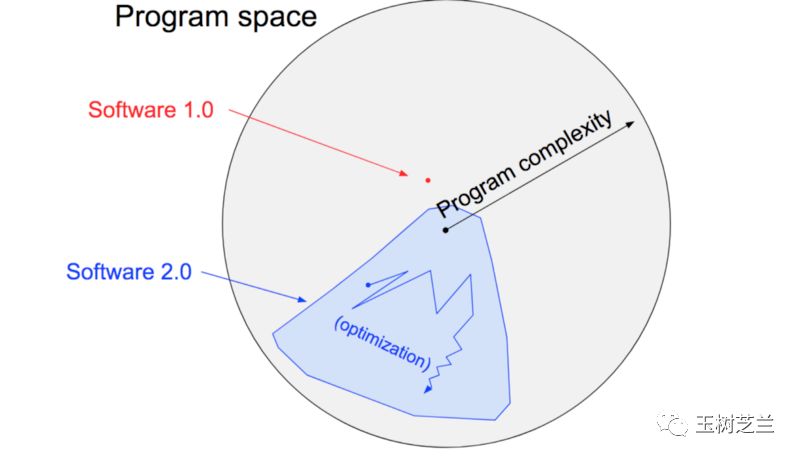
software 2.0的定义,是以不断积累的数据作为约束,在算法空间搜寻,利用优化器,自动构建软件模型。
这么说有些抽象,给你举个例子。
曾经,人造出来的下棋程序,根本打不过人类顶尖高手。
然而,一旦用上了机器学习,围棋大师也只好黯然神伤。
因为机器是自己从数据中尝试挖掘规律,自己构造模型。这样,它可以通过大规模增长见识,迅速提升表现,甚至是超越人类。因为“人为设定算法”这个玻璃天花板,已经被悄悄移除了。
因此,对于机器学习来说,你用的模型越复杂,就越需要高质量、大规模的数据支持。
听明白我在说什么了吧?
数据的地位,空前提高。特别是那些大规模标注数据。
你做这个研究的时候,有现成数据吗?
没有吧。
虽然社交媒体的数据,可以通过爬虫来便捷获取。但是对这些数据的分类标注,才是重点。
你组织人力,付出时间和经济成本,才获取了有标注的数据集合。这个过程中,你实际上已经解决了很多问题。
例如说,怎么把数据标注样本进行拆分,让若干标注者有序并行工作?怎么把任务描述得清晰无歧义,让个体的标注具备稳定性和一致性?标注结果该如何取信,如何评估,如何验证?什么才算做足够多的数据?……
对机器学习来说,如此重要的环节和内容,被你一笔带过。仿佛你用的,不过又是一个别人早已采集、清理和发布的公共数据集而已。因此,读者误解你的实际工作,把全部注意力,放到你模型的准确率评判上面。
你这么写论文,就叫做暴殄天物。
要知道,现在有的期刊,已经可以刊载“数据论文”了。你构造了一个好的数据集,本身就可以看做科研成果。是可以跟研究论文获得同等贡献对待,也是可以被引用的。

例如上图这篇论文中,3位作者利用 Zalando 图像数据库,构建了一个机器视觉分类的数据集 Fashion-MNIST,并公开发布。论文发表1年,已经被引用了154次。
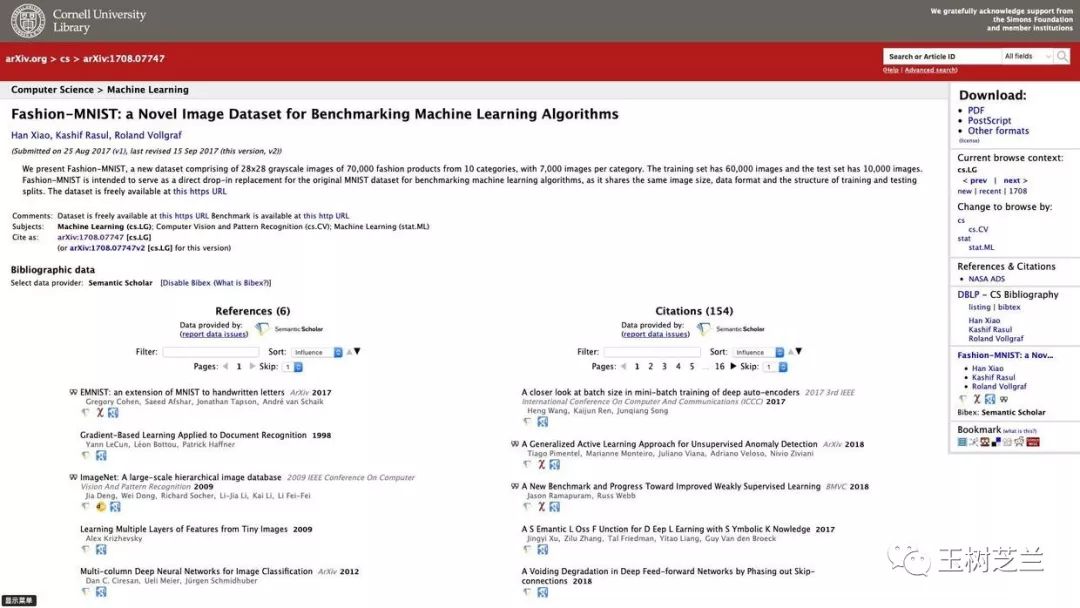
另外,你真的只是构建了一个数据集而已吗?
然后,你就拿着那篇英文文献的方法,开心地套用到这个中文文本数据集了?
开玩笑!
你不用分词吗?你不需要构建和迭代停用词表吗?你不需要选择模型结构吗?
该重点写的,研究里面的独特内容和实际工作,你都不好好写。不该写的,你反倒写了个不亦乐乎。说你不会讨论,不冤枉吧?
讨论
我之前为你写的教程,很多都会结束在“做出结果”。我给你推荐的 Coursera 平台的 MOOC 里面,项目作业也只会要求到这一步。
这没有错啊。教程的目的,是让你会用方法和工具。
但是不要忘了,你现在撰写的,不是教程,也不是作业,而是论文。
什么是论文?
它是你和学术共同体沟通的信息单元,反映的是你做的研究。写作的目的,是让他人相信和接受你的研究。
论文要被别人接受和采信,得靠能自圆其说。
你提出了一个问题,找到了数据,应用了方法,做出了结果。但是结果本身,是不是能够让人信服,说你解决了问题呢?
这可不一定。即便你的结果很显著,也不一定。做到这一步,只能叫做演示。
因为这个世界上,存在着一种叫做小概率事件的东西。中彩票头奖概率很低,但时常也有人会中。俗话说得好,谁家过年不吃顿饺子?
所以你写论文的时候,脑子中时刻要有一根弦儿,就是得说服别人,你的模型达到这种效果,不是巧合。
查科同学前几天在咱们团队群里,分享了一篇自然语言处理最新进展的论文。我希望你认真读一下,看看该文的作者,是如何讨论结果的。
仅从结果来看,模型效果已经是非常显著了。因为按照表格中数据对比,这种模型,已经超越了人工水平。
然而,你会看到作者是在非常认真细致地讨论这种结果取得的途径。他尝试了各种排列组合,在多个数据集上进行了对比……最终,读者会被说服,这个模型确实由于设计的精妙,达到了目前最高水准(state of the art)。
别误会,我不是让你照搬该论文的讨论流程和叙述方式。因为人家就是在跟别人的模型比;而你,是在跟空模型比较。
而你做出来结果之后,其实是在乱比较。居然用随机森林和决策树模型,对比效果。
你讨论的重点该是什么呢?并不是你的模型最优(不论是决策树,还是随机森林这模型,都不是你提出的),或者你的工具最好(scikit-learn的研发你也没有参与),而是机器学习方法,适合于解决中文文本隐私分类问题。
你不觉得很奇怪吗?随机森林模型的效果,在大多数情形下,就应该优于决策树模型。那在咱们讨论分类模型选择的时候,为什么二者都保留了下来呢?
因为你不应满足于演示模型分类效果优于空模型,关键是说服读者,这种优势不是随机获得的。
怎么办呢?
我在《如何有效沟通你的机器学习结果?》一文中给你讲过,可视化是一种非常好的结果沟通手段。而在《贷还是不贷:如何用Python和机器学习帮你决策?》一文中,我曾经给你展示过,决策树模型的一大优势,就是可以做出这样的可视化图形:
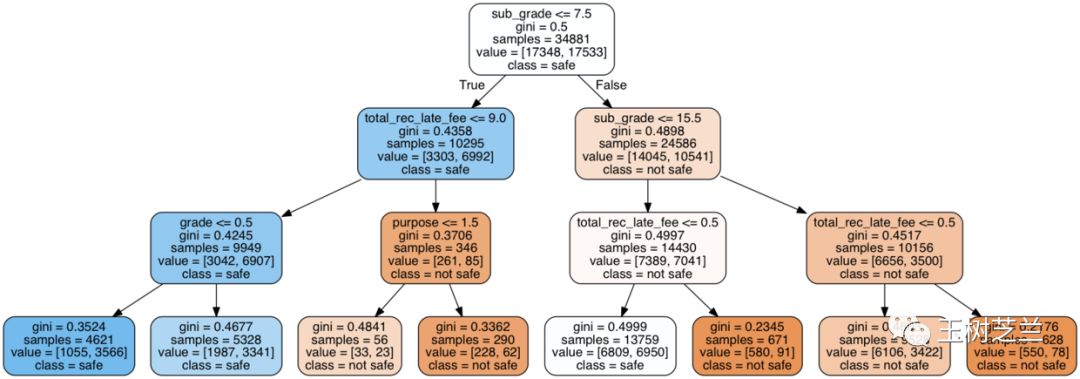
想想看,你用的方法,是基于关键词的特征。那么如果能够描绘决策判断过程中,哪些词会导向隐私分类结果,哪些词能导向非隐私分类结果,是不是就可以帮助读者了解,你的模型是否真正抓住了自然语言中蕴含的信息表征(representation)?
另外,演示了一个决策树可视化图形,你又觉得完事大吉,不知道后面该讨论什么了?
注意,模型自身算法并不重要。重要的是,它是怎么被训练出来的。
莫非你对于每个分类模型,都满足于直接调用默认参数了?
有没有进行超参数(hyper parameter)的调整?
有没有遇到过拟合(over-fitting)或者欠拟合的(under-fitting)问题?你是如何处理的?
有没有继续采集更多数据?有没有尝试更换不同模型结构?
优化器(optimizer)你是如何选取的,为什么?
学习速率(learning rate)你是怎么设定的?会不会导致模型学习太慢?或是难以收敛?亦或陷落到局部最优中,难以自拔?
你在特征工程(feature engineering)上做了哪些努力?要知道,你做的并不是深度学习,所以特征的有效提取和转化,是非常必要的。
如果你把上图的例子都忘了,请务必复习回顾我在《如何用机器学习处理二元分类任务?》为你做的详细解读和说明。
工具
虽然我一直鼓励你学习机器学习和深度学习这样的方法,用好 Keras 和 scikit-learn这样的优秀框架工具。但是你真的不应该因为掌握了它们,而沾沾自喜。现在看你的论文,就弥散着这种味道。似乎你会用机器学习,所以很了不起。
这种骄傲的态度,也会让读者和评阅专家反感。
说句让你不那么开心的话——你能够如此快速地掌握和应用这些前沿技术,主要是因为门槛越来越低。
以图像处理为例。2012年以前,如果你要让计算机对猫狗照片分类,并且获得很高的准确率,几乎所有前沿学者都会告诉你:
那是不可能的!
因为他们用的方法,是手工提取特征。然后再让机器,对手工提取后的特征,进行分类操作。
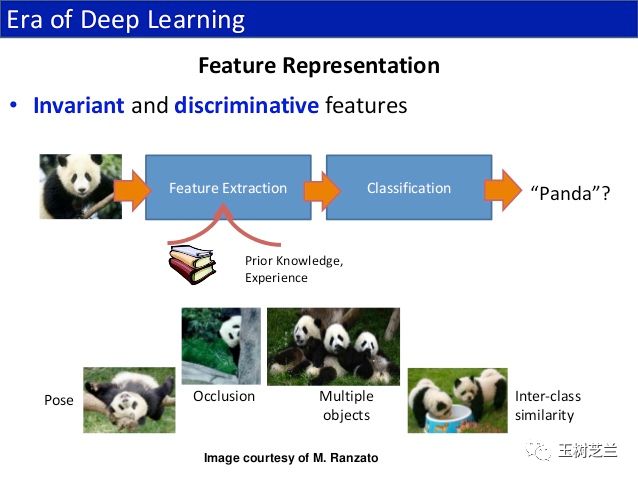
上图来自这里。它介绍了手工特征提取的不足。不难看到,为了给“熊猫”图片有效提取特征,你需要考虑多少种情况。特别是看到熊猫打滚的时候,你会有怒火中烧的感觉,恨不得勒令它保持一个姿势,不要动。
因此,当时的分类算法,特别“劳动密集型”。如果你想在国际大赛中取得佳绩,真是得“一分耕耘,一分收获”。
可是现在呢?
假如你用 fast.ai 深度学习框架,进行猫狗分类,那你根本不需要考虑任何特征提取的问题。写以下几行代码就可以了:
from fastai import *
from fastai.vision import *
from fastai.docs import *
untar_data(DOGS_PATH)
data = image_data_from_folder(DOGS_PATH, ds_tfms=get_transforms(), tfms=imagenet_norm, size=224)
img,label = data.valid_ds[-1]
learn = ConvLearner(data, tvm.resnet34, metrics=accuracy)
learn.fit_one_cycle(1)
好了,从数据获取,到模型构建,甚至是结果分析,全都做完了。
这几行代码构建的模型,能有多高的准确率呢?
答案是这样的:
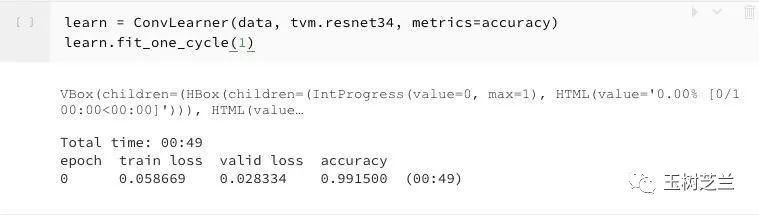
对,你没看错,即便是这几行代码,只把数据跑了一个来回(epoch),猫狗分类准确率就已经超过 99% 了。
正是 Scikit-learn, Tensorflow, Keras, fast.ai 这样的开源框架不断涌现,大批优质教程扩散传播,机器学习才能在几年的时间里,从高不可攀的“秘密武器”,变成了每个人触手可及的研究工具。
你要明白,能让你这么简单使用如此强大的工具,是千千万万人协作的结果。而你,是这一张协作网络中的一份子。
你应用机器学习工具,做有意义的研究,就是在给这张网络做出回馈。
尝试扩大机器学习的应用领域,让更多的人意识到新工具的特点和功能,并且一起来学习使用它。这些,都会给你论文的意义和价值加分。
既然没有门槛,大家都能用,那你这么强调它干嘛?
我在《如何选研究题目?》一文中,也给你谈到了信息科学界一流学者的共识,即千万不要工具导向。
当你手里只有一把锤子的时候,看什么都像钉子。但是当你拥有丰富的工具箱时,你会实事求是,用合适的工具处理对应的问题。
时刻记住,你的研究,无论如何应该是从问题出发的。机器学习恰好适合解决这个问题,那就用它。否则,该用什么适合的方法,就用什么。
小结
针对预答辩的反馈意见,我从“价值、必要、讨论和工具”这四个角度,帮你分析了论文中问题产生的原因,以及具体的对策。
小结一下,就是:
首先,一定要把握价值。根据研究的特殊性,选择合适的评价体系,加以合理阐释;
其次,说明必要性的时候,一定要了解机器学习和传统算法解决问题的本质差异。尤其是不要忽视数据这个重要维度;
第三,论文不是演示,不能缺乏讨论。通过读文献,掌握讨论、比较的具体方法,利用可视化的方法提升证据说服力,要着重强调模型是如何被训练出来的,而不是模型自身的算法;
第四,千万不要踩进“工具导向”的坑。要看清楚简单易用的机器学习框架背后,这个巨大的、快速进化的协作网络。既要随时跟踪最新进展,站在巨人肩膀上前进,又要时刻告诫自己不要高估自己个体的作用。
另外,就是我希望你也能够通过自己的研究,给学术界和机器学习技术社区以正向反馈。
写得内容有点儿多,希望你能认真读完。抓紧时间修改完善论文吧,力争顺利毕业。








