10 月 13 日,上海 GDG 联合个推共同举办了以“解构机器学习实践,探讨AI发展趋势”为主题的技术交流活动,整场活动邀请到了 来自Google GDE、网易云音乐、爱奇艺、个推、高校研究所等五位业内资深专家前来分享答疑,现场干货满满。

活动内容涵盖了多个领域的分享,包括技术架构解析、框架组件心得分享、金融领域应用实践、云音乐技术框架、二次元图像特效以及 TensorFlow 应用模块解析等等,每位嘉宾的分享都让到场的小伙伴有所收获。
你们久等的活动回顾来啦!
接着第二篇
【演讲实录】《基于 TensorFlow Lite 在移动端视频直播上的应用》
我们继续为大家带来第三篇回顾
来自嘉宾段石石的《机器学习在云音乐上的一些实践》
本系列嘉宾PPT资料等请在本公众号后台回复“10.13资料”获取
 嘉宾介绍
嘉宾介绍

l五年互联网从业经验,开源爱好者,TF、MXNet、PaddlePaddle、TFLearn contributor,知乎专栏作者,推荐算法出身,因在腾讯工作期间参与无量核心开发,由算法转ML SYSTEM。
l目前就职于网易云音乐,负责云音乐整体机器学习框架的应用于研发,为云音乐提供大规模机器学习框架与基础算法应用能力。
l目前的兴趣点在大规模机器学习框架、图网络等。
开场白
大家好!我是来自网易云音乐的段石石。我最开始在上海一号店,后面去了腾讯工作,前三年做算法。在一个机会下从算法转到做大规模机器学习框架,经过团队十个月的开发构建了一套大规模机器学习框架,并获得2018年腾讯技术突破奖,支持的业务也获得当年的业务奖。做完这个我就开始从算法转到做框架。
网易云音乐基础业务介绍
业务介绍
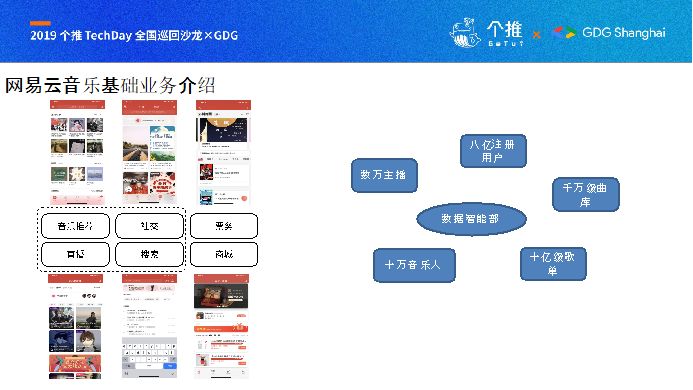
介绍一下我们的业务,广告,音乐推荐、直播,直播是我们现在龙头业务,我们在直播上现在投入很大,也特别欢迎各位同学一起来体验;社交业务,也就是mlog,目前流量还不错;搜索这些基础的业务,还有包括票务、商城业务。网易云音乐业务场景覆盖多种内容载体,比如八亿注册用户,十万音乐人,几十亿歌曲,千万级曲库。
数据智能整体架构
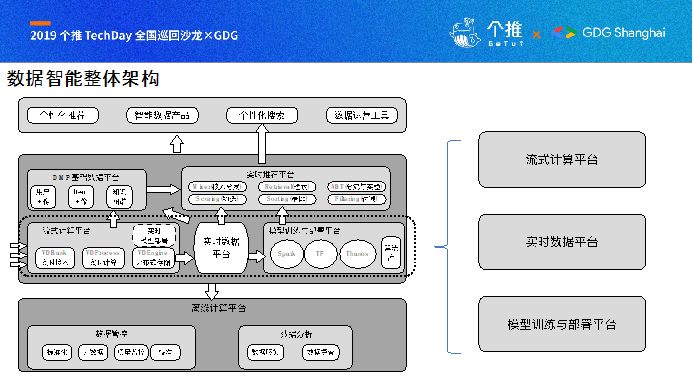
这是云音乐的整体架构,从底层离线计算平到中间实时数据相关的东西,还有包括我们的模型训练、模型部署;最上层就是DMP,基于此技术栈提供个性化推荐,智能数据产品,个性化搜索,数据运营工具,我所在的小组主要负责图中虚线框部分。流式计算平台、实时数据平台、魔性训练与部署平台。
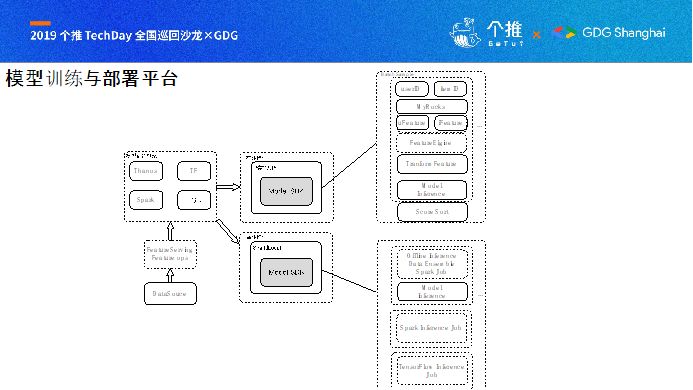
这是大概阐述下网易云音乐框架的现状:模型训练框架,支持TensorFlow、Spark、LGB、TensorFlow等机器学习框架,其中,Thanos是自研的框架,我们的愿景是在大规模分布式机器学习场景下,减少大部分的资源与算力。
训练完模型之后,如果模型要上线,会进入精排系统。精排系统支持包括TF、Thanos、LGB、Spark等模型框架训练的模型的线上服务,精排系统主要包括两个部分:
1.特征的线上处理;
2.模型的在线推理;这两部分目前是集成在精排系统,后续会分开,形成Feature Serving和Model Serving两块内容; 还有离线推理,一般来说推荐系统流程包括:召回、初筛、精排;召回一般是T+1或者T+2的过程,我们有大量的离线数据计算,比如首页歌单,每天要计算将近300亿数据的离线推理,如何高效、稳定地去离线推理来支持数百亿的计算这是很大的难题。离线模型推理,有几种方式:
①.基于TensorFlow现有API,如Estimator的Predict接口来进行离线推理;
②.第一种方法在数据量很大的情况下,效率比较低,比如离线推理数据达到三百亿,使用第一种方法并不高效,其实,TensorFlow保存的模型就是一个Graph,Graph中每个节点有相应的值,每个节点有相应的前向计算逻辑,我们将TensorFlow的C++的Framework打包成so,使用Java Jni封装后再做推理,打成jar包,然后基于Spark去调用jar中的计算接口,Spark集群能够有效地进行大规模数据的离线推理。
Thanos与TensorFlow在云音乐的实践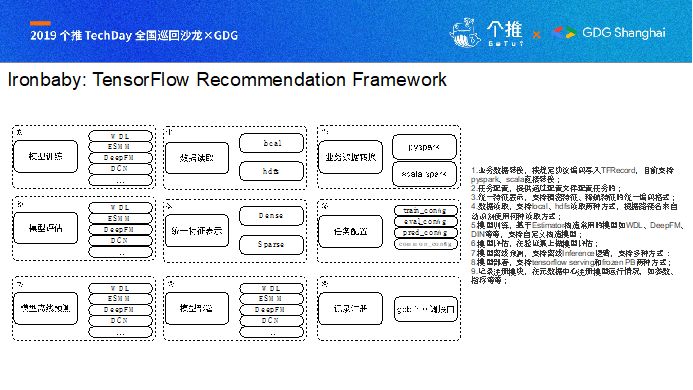
Ironbaby是一套基于TensorFlow下做推荐的框架,主要是基于TensorFlow的Estimator来进行开发,集成了很多经典的算法,也提供业务同学扩展算法模型的能力,Ironbaby主要包括9个部分:
第一部分:业务数据转换,一般业务数据量极大,TensorFlow作为机器学习框架,提供了高效的数据存取格式:TFRecord, 我们选择在Spark端进行大规模数据转换,统一特征编码规范;
第二部分:任务配置,任务配置模块,主要讲模型的训练、评估、预测以及如数据读取这类一般化的配置;
第三部分和第四部分:统一特征表示与数据读取,这里其实是与第一步相关的,基于TensorFlow,我们定义了一套相对比较通用、合理的特征编码协议,来表示特征,数据读取的接口支持相应编码数据的读取,通过对编码协议的限制,杜绝了在TensorFlow这样一套极具灵活性的框架下各种低效、不合理接口的乱用,数据的读取支持local和hdfs文件,用户无感知;
第五部分和第六部分:模型训练与模型评估,基于TensorFlow Estimator,能够有效地集合模型训练与模型评估,针对算法开发,仅仅去实现模型构建与数据读取,即可完成模型训练、模型评估,以及之后的模型部署等需求;
第七部分与第八部分:模型离线预测与模型部署,模型离线预测主要针对离线任务,根据任务数据量划分有两种形式:1,数据量百万、千万级别,可以通过单机部署或者直接调用TensorFlow Estimator接口来进行离线预测;2,数据量特别大的,比如数百亿待预测的数据,单机计算需要花费大量时间,这里我们会通过Java Jni来封装模型计算逻辑,来对数百亿的离线数据进行预测计算;
第九部分:记录注册模块,TensorFlow模型的训练,我们希望能够合理地进行监控,每一个TensorFlow任务,我们均希望能够在元数据中心记录。
这是Ironbaby在搜索重排的case,每天训练数据量七千万,数据量大约是40GB,算法同学只需要像图像配置即可完成搜索场景下四个特征域的DeepFM模型的训练以及后续预测、部署;
所有的操作都是基于我们的机器学习平台Goblin,TensorFlow作为一个组件集成到了Goblin,支持定时调度、依赖调度等,上图中就是依赖上游的大数据任务,每天生成训练数据来进行训练,任务整个耗时大约是35分钟一个epoch,整体速率其实不够快,后续会有专门分析TensorFlow的效率瓶颈问题。
模型完成训练后,如何有效地去做推理,是很多工业界同学关心的工作,这里我们按线上与线下分为两个部分:
1.线上服务:我们选择基于Frozen PB+Jni的方案而不选用TensorFlow Serving,主要有两个方面的考量。首先,在TensorFlow在云音乐大规模使用之前,就有很多的场景使用上机器学习,这部分工作已经完成了相当多的技术积累;其次,基于TensorFlow Serving的线上服务的方案在我看来并不是特别使用推荐场景的模型在线部署,尤其在多field场景下对样本编码、解码产生的时耗,另外TensorFlow Serving本身的优势如双缓存、预热机制,也是在现有的线上服务框架上有了很好的支持;模型转为Frozen PB之后,会重新过下goblin上的TF Inference Eigine,对比验证集上的评估指标差异,如AUC,保证Frozen PB的Inference效果不出现错误,类似于Double Check的逻辑,当AUC能对齐之后,模型就会推送到精排系统,自动为业务提供服务。
2.离线推理,前面也提到当数据量比较小时,直接使用基于TensorFlow Estimator这套的Predict接口,完全能够支持,当数据到一定量级时, 我们选择使用Spark+TensorFlow+Jni Frozen PB来进行大规模数据的预测。
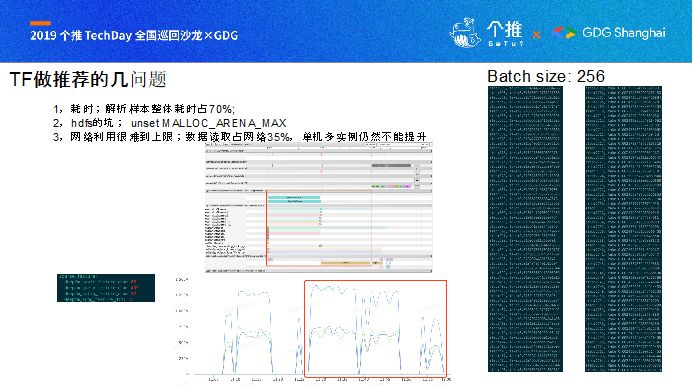
TensorFlow在推荐场景上有一些坑,我这里遇到了几个分享给大家:
一、耗时,解析样本包括读取数据、样本数据解析两块的耗时占整体耗时的70%以上,且这部分耗时在现有API上可以通过一些参数配置来调优,但是整体资源消耗和性能提升并不明显;
二是TensorFlow与HDFS的坑,在配置TensorFlow访问HDFS环境时,默认会被配置上很多环境变量,其中有一个MALLOC_ARENA_MAX默认会被配置为4,在Hadoop接入时,这个没有多大问题,但是在TensorFlow环境下,这个会直接影响内存分配的线程池最大数,严重影响读取HDFS数据的性能;
三、TensorFlow对数据处理通常会导致CPU成为瓶颈,而导致在数据读取中网络利用率极低,在我们环境下,最好的约是占网络带宽35%,且由于CPU成为瓶颈单机多实例仍然不能提升。而在推荐场景中,通常计算量相对于CV、NLP并不大,反而是数据读取,会占更大的部分,而TensorFlow在这块性能并不冒尖。
基于上面所提到的问题,TensorFlow在大规模推荐系统上支持力度有限,尤其是在业务本身已经十分完备的业务场景上,社区也有很多基于TensorFlow的改善方案,而云音乐在针对大规模场景,自研了一套基于参数服务器的大规模机器学习框架,并期望在此基础上无缝集成TensorFlow这类工业界流行框架,借此利用TensorFlow本身Graph的便利以及自研框架本身的大规模分布式能力,更好地为业务服务。
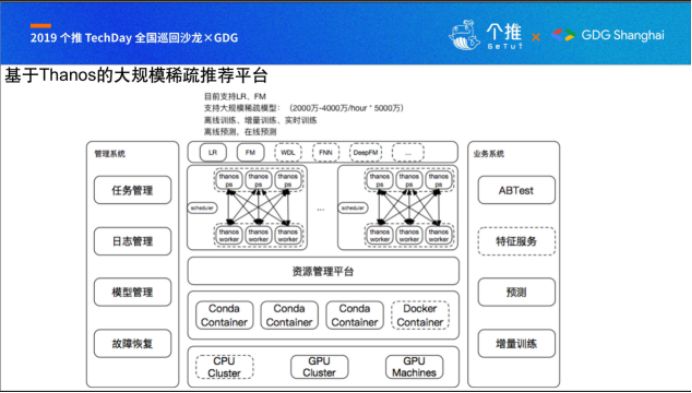
基于Thanos的大规模推荐平台,目前已经有了一套比较完整的生态,主要包括四个部分:
第一部分:管理系统,主要是基于现有的Goblin系统,主要支持机器学习场景下的任务管理、日志管理、模型管理、故障恢复等相关功能,目前已经完全适配Thanos这一套大规模推荐框架;
第二部分:资源管理平台,主要包括CPU集群、GPU集群、GPU机器, 基于CPU集群、GPU集群,利用conda来做环境的隔离,目前正打算基于docker+k8s来做环境的部署与资源的隔离;
第三部分:Thanos大规模分布式机器学习框架,主要基于参数服务器来实现高效的大规模分布式算法;
第四部分:业务系统,主要支持业务系统在机器学习上的各种需求,比如ABTest、增量训练以及接入kafka进行增量训练。
目前在Thanos上,已经支持了2000万-4000万/小时,5000万维度的数据训练。
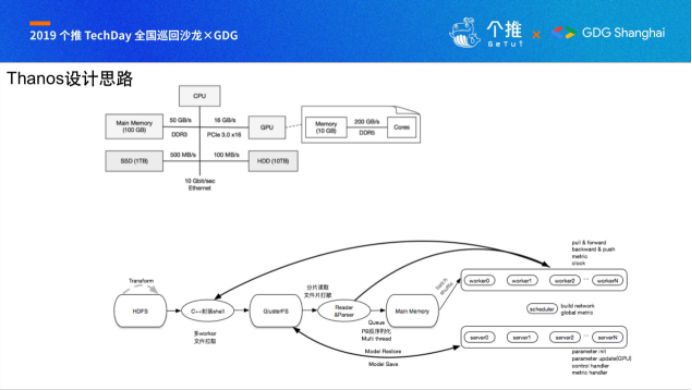
Thanos作为云音乐机器学习框架的一部分,在设计上我们充分尊重并且利用不同分布式计算机系统各部件的差异,Thanos的具体设计思路已在GDG上进行分享,这里文档就不详述了。
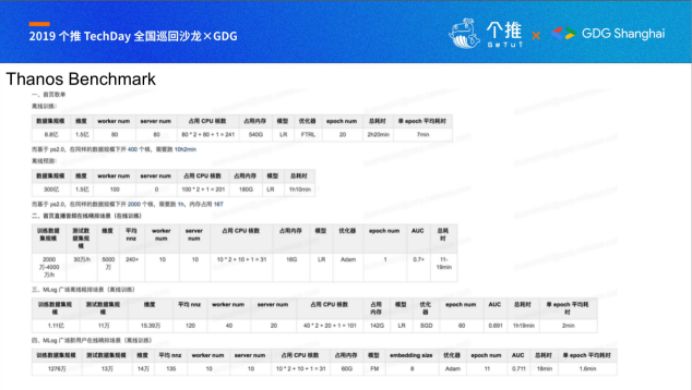
这套Benchmark数据是我们在接入云音乐真实数据的训练性能,整体看来Thanos有极其高效的训练以及推理速度,另外有业务同学反馈在相关业务场景的数据对比上,Thanos相对TensorFlow有接近10倍训练速度的提升。
实践
Case1: TensorFlow On Flink

最近云音乐在直播业务上有很大的发展,也培养了很多平台的直播大v,也有其他竞品的公会来挖云音乐的直播大v,这里我们自己标注了大约4万条样本,得到了4000余条有效的拉人样本,也得到一批相关的种子词。
利用这些样本,我们基于字向量+TextCNN训练了私信拉人的文本分类模型,该模型在保证分类指标的同时,也保证了模型的推理速率,达到了低于1ms/样本,之后利用现有基于Frozen PB+Jni,利用Flink接入分类模型,在私信产生同时,对模型进行私信拉人的分类。
基于Flink的TensorFlow部署是相对比较窄一些的领域,且并不是所有场景均适合部署在Flink,私信拉人识别在短文本场景下,且使用字向量+TextCNN能够高效地完成推理,整体看起来十分适合这类流式的快速检测的场景,当然也可以部署Serving服务,但是相对于Flink的方案,无疑增加了额外的流程消耗,有相关业务的读者完全可以来做相关的尝试。
Case2: 直播实时优化

直播实时化项目,实时化不是简单的模型训练,是整套系统架构的问题。以往直播的模型训练任务是T+1更新,导致很多实时性的特征数据没有被利用,比如直播间观众数、有效观看人数、送礼数、发言数等等,现阶段,我们采用小时级别更新模型,每小时数据量约为2000万-4000万,数据量每天约为8亿条,1.2T。
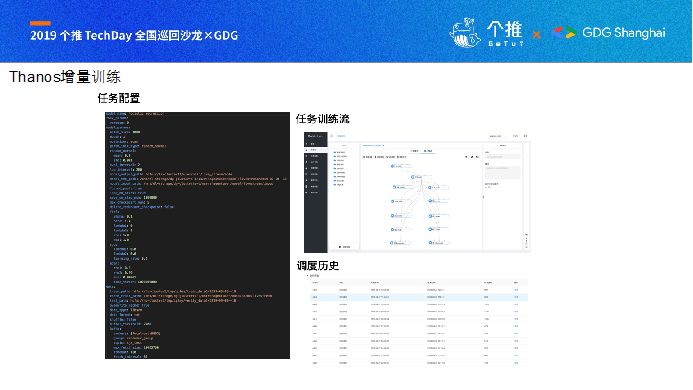
Thanos任务的配置全部集中在配置文件,配置好相关项之后,即可在Goblin上完成模型的训练,当确认无误后,即可上线调度,上线调度可选择包括文件目录是否存在的各种依赖,自定义时间进行任务的调度。
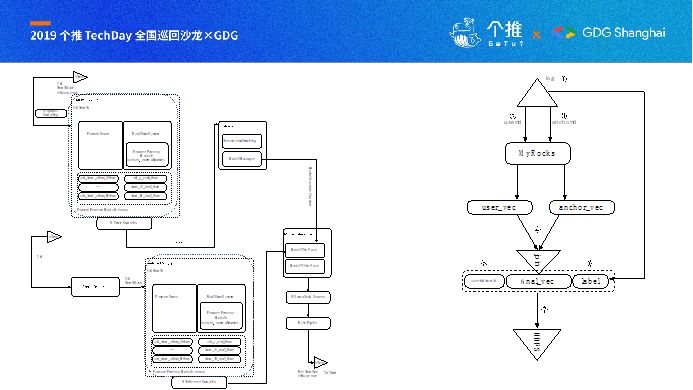
增量的模型训练,通常我们会简化数据特征的处理过程,复杂的特征处理逻辑通常应用在离线特征上,处理完成之后进入KV数据库如MyRocksDB,以供实时拼接,通常对实时特征只做相对比较简单的处理,如分桶、Hash、交叉等等,样本特征数据处理完成之后,每小时保存至HDFS目录,训练任务部署为依赖该目录,每小时调度,整个流程就自动化完成。
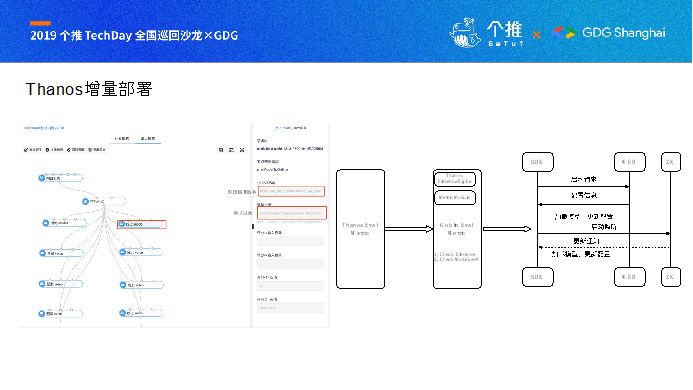
完成模型训练之后,自动化部署增量训练的模型,依靠Goblin组件,可以简单实现Double Check+自动化部署的过程。

直播实例化项目存在一些很明显的挑战,主要集中在以下几个方面:第一,线上线下数据对齐困难:因为数据产生是实时的,不保留的,没有快照的概念,很难校验,确保数据准确性;第二,在线处理的数据对齐难做,容易产生特征穿越等问题;第三,实时特征数据比交叉数据模型更敏感,相对比离线数据模型,需要更多的准确性处理方案;最后,这一套流程特别长,整套系统由于是首次尝试,各种问题频出,系统架构方面发现了很多问题,也做了比较大的改善。
精彩预告
接下来还会有其他嘉宾的演讲实录,将通过上海 GDG 小编精心整理后,陆续逐一发出与小伙伴们见面啦,尽请期待吧~
Google Developer Groups 谷歌开发者社区,是谷歌开发者部门发起的全球项目,面向对 Google 和开源技术感兴趣的人群而存在的公益性开发者社区。GDG Shanghai 创立于 2009 年,是全球 GDG 社区中最活跃和知名的技术社区之一,每年举办 30 – 50 场大大小小的科技活动,每年影响十几万以上海为中心辐射长三角地带的开发者及科技从业人员。
社区中的各位组织者均是来自各个行业有着本职工作的互联网从业者,我们需要更多新鲜血液的加入!如果你对谷歌技术感兴趣,业余时间可调配,认同社区的价值观,愿意为社区做出贡献,欢迎加入我们成为社区志愿者!
志愿者加入方式:关注上海 GDG 公众号:GDG_Shanghai,回复:志愿者。
社区成员加入方式:请发邮件至以下邮箱
gdg-shanghai+subscribe@googlegroups.com









