
随着神经网络体系结构、深度学习和机器学习研究的快速发展,以及不断增加的硬件+软件资源,很多特别棒的演示项目数量正以令人眼花缭乱的速度增长。
从人工智能生成的艺术品到实时跟踪人类运动甚至更进一步,我们总结了一些我们最喜欢的深度学习项目,并附带了视觉演示。
毫无疑问,我们可以找到和强调的项目数不胜数,但希望这份清单能让你对研究人员、从业者,甚至艺术家在 2019 年用机器学习和深度学习创造的东西有一个高层次的了解。
一个有趣(也许并不奇怪)的注意是,这些演示很多都是使用了生成对抗网络来创建的:它们自然会产生很好的视觉效果,而且体验很好。
为了补充演示,我尝试在可用的地方提供链接资源(论文、代码、项目页面、完整视频等)。
带样式转换的 wikiart+StyleGAN
——Gene Kogan
在这里,我们基本上看到了将样式转换与 StyleGAN 相结合时可能出现的情况。我们将参考图像的样式直接应用到潜在的空间图像。
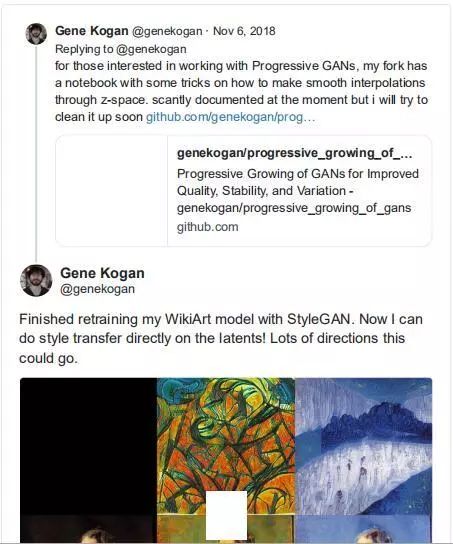
至少在该项目的 GANs 部分,Gene 分叉并使用 Nvidia 的回购协议来促进 GANs 的逐步增长:

github:https://github.com/genekogan/progressive_growing_of_gans
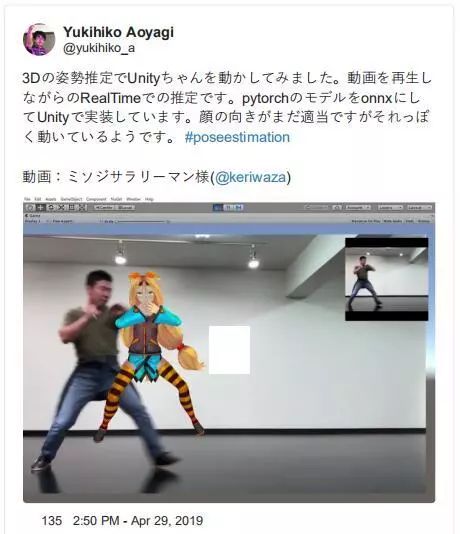
统一的 3D 姿态估计
—— Yukihiko Aoyagi
将 3D 姿态估计与 3D 开发平台和 unity 这样的渲染引擎结合起来,就可以实现像这样迷人的 AR 项目。通过将这两种强大的技术结合起来,AR 对象可以更精确地跟踪三维空间中的人体运动。
提示,这个项目暂时只支持单人姿态。
twitter 网址:https://twitter.com/yukihiko_a
代码:https://github.com/yukihiko/ThreeDPoseUnitySample
建筑机器翻译
——Erik Swahn
该项目以对象的视频帧作为输入,输出现代建筑效果图。这是一个有趣的机器翻译应用。

twitter 网址:https://twitter.com/erikswahn
这里是代码——找不到直接的源代码,所以如果有人知道在哪里可以找到它,请在注释中给我留言:
github:https://github.com/memo/webcam-pix2pix-tensorflow
消除图像和视频中的汽车
——Chris Harris
Chris 可能没有我们对这个演示印象深刻。A Vanilla Sky——esque 的项目,通过车辆检测网络屏蔽在城市街道上移动和停放的车辆,并在检测到的车辆上添加 AR 模糊效果。
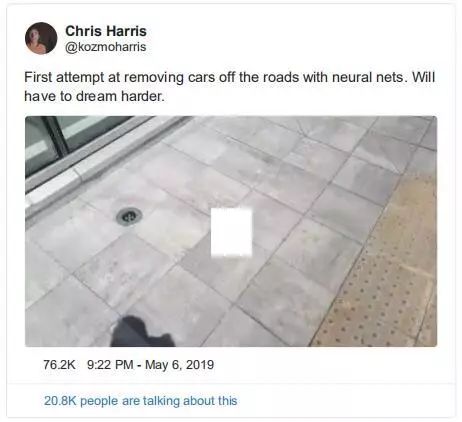
twitter:https://twitter.com/kozmoharris/status/1125390364691640321
这里有一个详细的概述,讨论如何做这个项目以及相关的原因。网址:http://harrischris.com/article/biophillic-vision-experiment-1
有灵感吗?Fritz AI 拥有自己创建的优秀项目和将 itt 部署到 mobile 所需的工具、专业知识和资源。从 Fritz AI 开始,教你的设备去看,去听,去感觉,去思考。
用 gan 将图像转换为看不见的域
——Ming-Yu Liu, NVIDIA
摘要:
从少数样本中提取新对象的特征并归纳总结,我们寻求 few-shot,无监督的图像到图像的翻译算法。我们的模型通过将对抗性训练方案与一种新的网络设计相结合来实现这种 few-shot 生成能力。
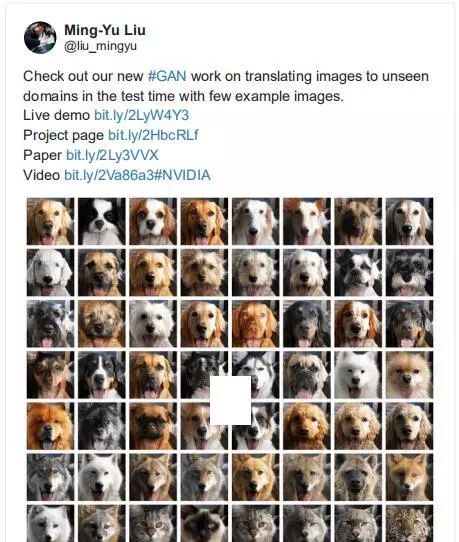
twitter:https://twitter.com/liu_mingyu
项目页面:
网址:https://nvlabs.github.io/FUNIT/
论文:
网址:https://arxiv.org/abs/1905.01723
无限模式
——Alex Mordintsev
Alex 在谷歌工作,他是 DeepDream 的创始人,这是一个计算机视觉程序,它使用神经网络来发现和创建图像中的模式。这些无限循环经常是梦幻的,甚至是幻觉。我几乎认为这些是移动墙纸。他在下面的 twitter 上有一些,所以一定要按照链接查看。

twitter:https://twitter.com/zzznah/status/1125393901815238656
这篇文章在谷歌的实验中探索了这个项目,并讨论了它是如何与 Pinar&Viola,一个数字艺术组合合作的:
网址:https://experiments.withgoogle.com/infinitepatterns
从单张图片进行完整的 3d 家庭试镜
—— Angjoo Kanazawa
最近,我们看到对尝试体验的兴趣激增,像古驰(gucci)这样的零售商正在探索如何让他们的用户在自己家(或在地铁上,或在工作中)舒适地使用他们的产品。
但这些体验只会和支撑它们的 3D 表示一样好。该项目引入了「像素对齐隐式函数(PIFu)」,这是一种高效的隐式表示,它将二维图像的像素与其对应的三维对象的全局上下文局部对齐。

twitter:https://twitter.com/akanazawa
项目页面:
网址:https://shunsukesaito.github.io/PIFu/
论文:

网址:https://arxiv.org/abs/1905.05172
GANs+像素艺术
——Max Braun
一个有趣的人工智能艺术项目,将一个 GAN 组合在一个无限循环中,在 eBoy 数据集上进行训练。对于那些不熟悉的人,eBoy 创建可重用的像素对象,并使用这些对象来创建艺术品、制作玩具等。

twitter:https://twitter.com/maxbraun
代码:
网址:https://github.com/maxbbraun/eboygan
Colab Notebook:
网址:https://colab.research.google.com/drive/1IXI9cBgqS1_4A9Quhhve3B7uPMshauKX
eBoy:
网址:http://hello.eboy.com/eboy/
花更少的时间搜索,更多的时间建设。报名参加每周一次的深度学习活动,深入了解最新的新闻、最佳教程和最重要的项目。
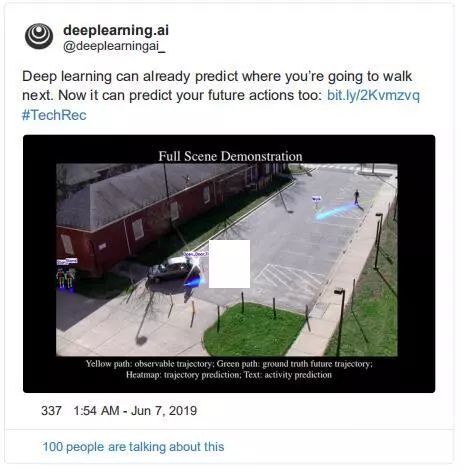
轨迹预测
——由 deeplearning.ai 发布,来自 Carnegie Melon, Google AI 和 Stanford 的研究
在人类活动跟踪领域,预测人们将要移动到哪里是一个非常有趣的项目。这样的应用比比皆是,从理解零售业中的客户行为到群体分析等等。更进一步的说,这个演示包括对特定人活动(如交通、工作等)的性质和背景的预测。
论文:
网址:https://arxiv.org/abs/1902.03748
以橙汁为切入点走进 AR 世界
——キヨ
这是一个令人惊奇的,关于如何利用增强技术将富有想象力的数字世界与现实世界中的物体融为一体的项目。虽然找不到任何底层代码或项目页面,但是这个演示显示了 AR+ML 在释放这些想象力和艺术体验方面的潜力。
网址:https://heartbeat.fritz.ai/combining-artificial-intelligence-and-augmented-reality-in-mobile-apps-e0e0ad2cfddc?gi=757dae3f21e5
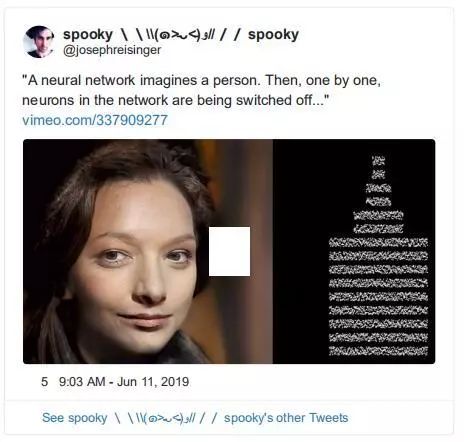
学着忘记一张脸的模型
——posted by Joseph Reisinger
下面 tweet 中的引用很好地总结了这个项目。我们看到了很多演示,展示了一个神经网络生成新的、真实照片的人和图像。但在这里,我们看到的过程是相反的——解构一个生成的肖像,网络的神经元被一个接一个地切断。
twitter:https://twitter.com/josephreisinger/status/1138250263934857217
使用 tensorflow.js 进行身体部位分割
——Google Developers
在 Google I/O 2019,这个来自 tensorflow 团队的演示展示了实时运动跟踪和图像分割。为了让这种体验实时工作,他们运行两个身体部位分割模型,将它们匹配起来,运行动态时间扭曲,然后播放和编码视频。以 Tensorflow Lite 的 GPU 加速为特色。
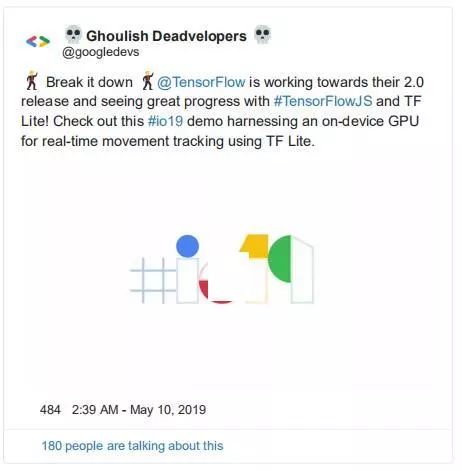
twitter:https://twitter.com/googledevs
用姿态估计把自己变成 3D 化身
——青絵
这种体验结合了姿态估计和 AR,将用户转化为怪物(或任何 3D 角色化身)。这个演示在这个词最字面的意义上是变革性的。最让人印象深刻的也许是移动跟踪的精确性和精确性——化身与用户的移动非常匹配。还有一些很酷的用户体验,包括一个基于手势的转换机制,以及一个整洁的声音效果,同时化身正在生成。
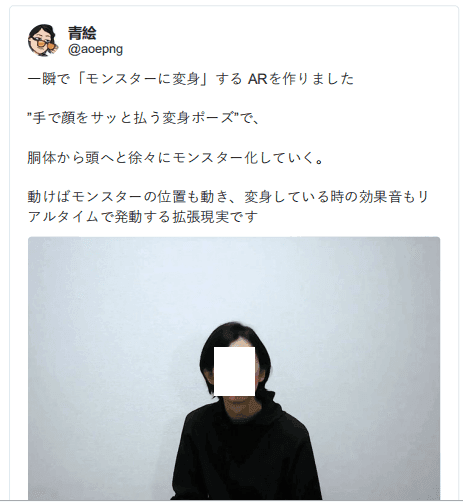
twitter:https://twitter.com/aoepng
利用目标检测跟踪垃圾和其他人行道障碍物
——Paula Piccard
最让我印象深刻的是被检测到的性质——摄像机移动的速度,以及瞬时检测。这种应用程序有可能改变我们对所谓「智慧城市」的看法。
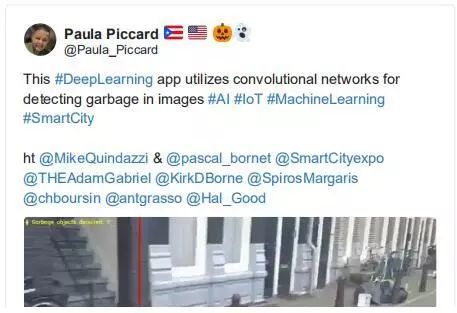
twitter:https://twitter.com/Paula_Piccard
用 GANs 画出逼真的风景
——作者 Kevin Lim
如果你观看此演示,你会注意到左侧的人造绘图看起来像你在诸如 MS Paint 之类的旧应用程序中看到的东西。如何将这些粗糙的景观生成和渲染为照片级真实风景是值得注意的。这类应用程序会错使我认为我实际上是一个艺术家!
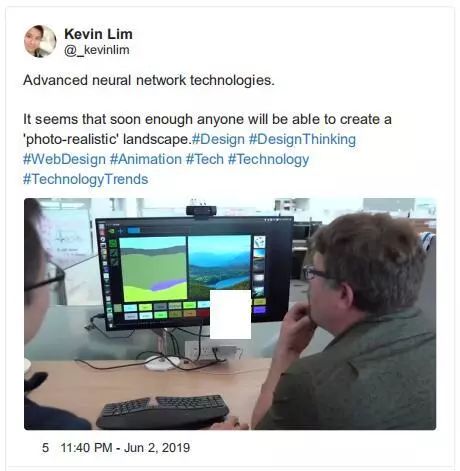
twitter:https://twitter.com/_kevinlim
神经网络延时(GAN)
——作者 Spiros Margaris
很难找到这个项目的作者,但它的新奇性和可重复性有着令人难以置信的吸引力。
它的 YouTube 视频描述是这样的:
左边是源脸,Theresa May。下一个步骤是学习她的脸,然后使用它的学习到的模型重建她的照片。接下来是目标脸和它正在建立的模型。最后,在最右边的第五栏(lol)是对 Theresa May 脸部的再现,需要与目标脸部的位置和表情相匹配。
YouTube 视频:https://www.youtube.com/channel/UCkMQyMq7xVjtMP2nl3uAQjg
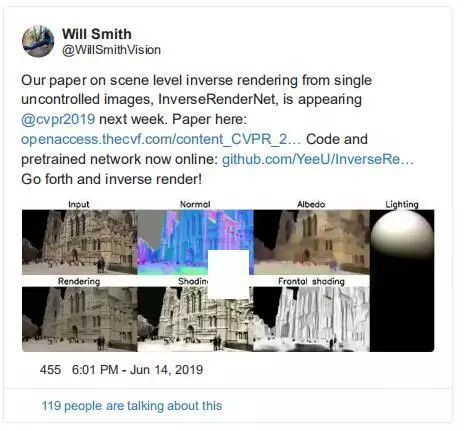
从单个图像进行反向场景渲染
——Will Smith
摘自论文摘要:
我们展示了如何训练一个完全卷积的神经网络来从单个的,不受控制的图像进行逆向渲染。该网络以 rgb 图像为输入,利用回归反射率计算法向光照系数。
twitter:https://twitter.com/WillSmithVision
代码和实践:
网址:https://github.com/YeeU/InverseRenderNet
论文:
网址:https://arxiv.org/abs/1811.12328
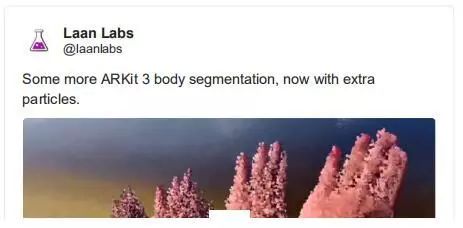
基于粒子效应的 ARKit 3 人体分割
——Laan Labs
另一个非常吸引人的视觉演示,是将增强现实效果与深度学习结合起来。在这里,laan labs(一家专营边缘技术的精品 ML/CV 店)在一个人体分割模型上应用了一种溶解粒子效应。
twitter:https://twitter.com/laanlabs
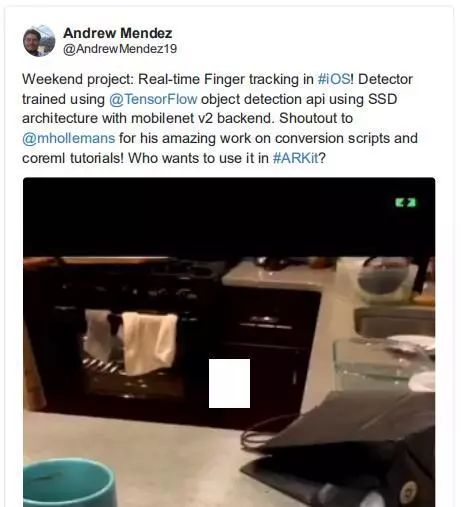
用 YOLO 实时检测手指
——Andrew Mendez
Andrew 在这个演示中很好地描述了引擎盖下的情况,展示了 iOS 上令人印象深刻的实时结果。正如 Andrew 所提到的那样,有很多可能加入到这个基线体验 AR,进行手指跟踪等等。
twitter:https://twitter.com/AndrewMendez19
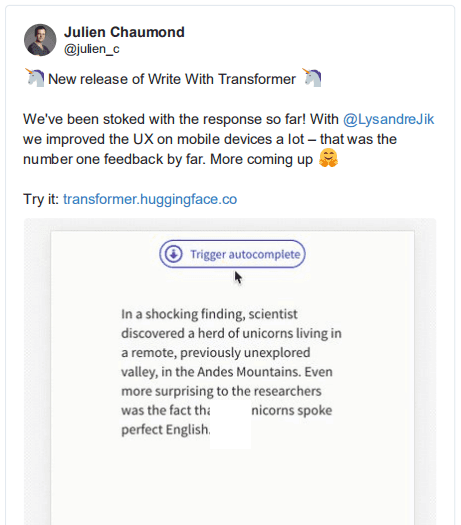
使用 GPT-2 在移动应用程序中生成文本
——Hugging Face
在 Hugging Face 上的人们已经在 transformer 和其他 nlp 架构上取得了令人难以置信的进展。不仅仅是服务器端,他们还致力于模型蒸馏,努力将这些功能强大的语言模型嵌入到设备中。这个演示特别关注文本的自动生成完成。
twitter:https://twitter.com/julien_c
试一下吧:
网址:https://transformer.huggingface.co/
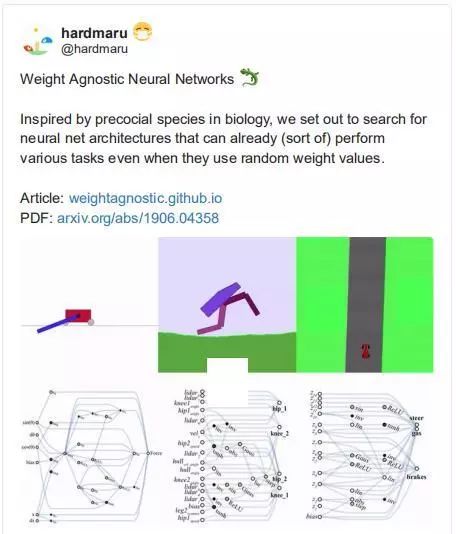
权重未知的神经网络
——hardmaru
与权重无关的神经网络的想法令人信服,它让我们质疑与底层架构相比,权重参数有多重要。摘要很好地揭示了这种动态:
并非所有的神经网络体系结构都是平等的,有些在某些任务上比其他的要好得多。但是,与神经网络的结构相比,神经网络的权值参数有多重要?在这项工作中,我们质疑在没有学习任何权重参数的情况下,单靠神经网络架构能在多大程度上对给定任务的解进行编码。
twitter:https://twitter.com/hardmaru
项目页面:
网址:https://weightagnostic.github.io/
论文:
网址:https://arxiv.org/abs/1906.04358
MediaPipe:一个结合了深度学习和传统 CV 管道的框架
——Google AI 发布,作者 Diakopoulos
MediaPipe 是 Google 将传统 CV 任务与深度学习模型相结合的相对较新的管道。这个新的框架真的为更沉浸式和互动性 AR 体验打开了大门。
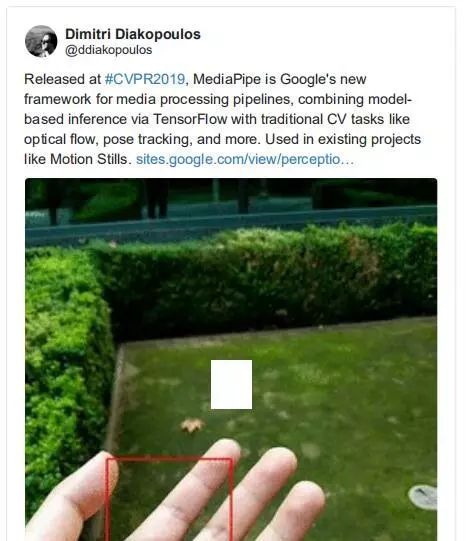
twitter:https://twitter.com/ddiakopoulos
github:
网址:https://github.com/google/mediapipe
博客和案例:
网址:https://ai.googleblog.com/2019/08/on-device-real-time-hand-tracking-with.html
全三维姿态估计:身体、手和脸
——CMU,HCI Research 发布
该项目代表了第一种使用单目视图输入捕获整个三维运动的方法。该技术生成一个三维可变形网格模型,然后用于重建全身姿态。从视觉的角度来看,这个等式的「total」部分对我们来说印象最深刻。以这种方式重建面部、身体和手的姿态的能力,让一个真正令人惊叹的演示成为可能。

twitter:https://twitter.com/HCI_Research
代码:
网址:https://github.com/CMU-Perceptual-Computing-Lab/MonocularTotalCapture
项目页面:
网址:http://domedb.perception.cs.cmu.edu/monototalcapture.html
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:AI开发者










