
在传统的软件开发中,一个 bug 通常会导致程序崩溃。这对用户来说是很烦人的,因此解决这些问题对开发人员来说很重要——当程序失败时,开发人员可以检查错误以了解原因。
在机器学习模型中,开发人员有时会遇到错误,但经常会在没有明确原因的情况下导致程序崩溃。虽然这些问题可以手动调试,但机器学习模型通常由于输出预测不佳而失败。更糟糕的是,当模型失败时,通常没有信号显示模型失败的原因或时间。而使情况更为复杂的是,这可能是由于一些因素造成的,包括糟糕的训练数据、高损失误差或缺乏收敛速度。

在这篇博客文章中,我们将讨论如何调试这些无声故障,以便它们不会影响我们机器学习算法的性能。以下是我们将要介绍的内容的简要概述:
如何发现输入数据中的缺陷。
如何使模型从较少的数据中学到更多。
如何为训练准备数据,避免常见陷阱。
如何寻找最优模型超参数。
如何安排学习速率以减少过拟合。
如何用权重和偏差监测训练进度。
值得注意的是,作为一名数据科学/机器学习实践者,你需要认识到机器学习项目失败的原因有很多。大多数与工程师和数据科学家的技能无关(仅仅因为它不起作用并不意味着你有缺陷)。我们的收获是,如果我们能够尽早发现常见的陷阱或漏洞,我们可以节省时间和金钱。在金融、政府和医疗等高风险应用领域,这将是至关重要的。
在想知道我们的数据是否能够胜任训练一个好模型的任务,可以考虑两个方面:
为了弄清楚我们的模型是否包含预测信息,我们可以扪心自问:给定这些数据,人类能做出预测吗?
如果一个人不能理解一幅图像或一段文字,那么我们的模型也不会预测出有意义的结果。如果没有足够的预测信息,给我们的模型增加更多的输入并不会使它变得更好;相反,模型会过拟合,变得不太准确。

一旦我们的数据有足够的预测信息,我们就需要弄清楚我们是否有足够的数据来训练一个模型来提取信号。有几个经验法则可以遵循:
对于分类,我们每类至少应有 30 个独立样本。
对于任何特征,特别是结构化数据问题,我们至少应该有 10 个样本。
数据集的大小与模型中参数的数量成正比。这些规则可能需要根据你的特定应用程序进行调整。
如果你能利用迁移学习,那么你可以大大减少所需样本的数量。
在许多情况下,我们只是没有足够的数据。在这种情况下,最好的选择之一是扩充数据。再进一步,我们可以用自动编码器和生成对抗网络等生成模型生成自己的数据。
同样,我们可以找到外部公共数据,这些数据可以在互联网上找到。即使数据最初不是为我们的目的而收集的,我们也可以潜在地重新标记它或将其用于迁移学习。我们可以在一个大数据集上为不同的任务训练一个模型,然后使用该模型作为任务的基础。同样,我们可以找到一个别人为不同任务训练过的模型,并将其重新用于我们的任务。
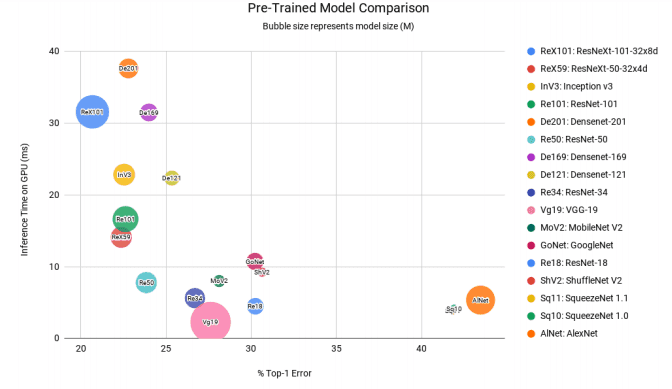
重要的是,要记住,在大多数情况下,数据的质量胜过数据的数量。拥有一个小的、高质量的数据集并训练一个简单的模型是在训练过程早期发现数据中问题的最佳实践。许多数据科学家犯的一个错误是,他们花时间和金钱获取一个大数据集,但后来发现他们的项目有错误的数据类型。
标准化:确保所有数据的平均值为 0,标准偏差为 1。这是减少特征的最常见方式。如果你怀疑数据中包含异常值,那么它甚至更有用。
最小 — 最大重缩放:通过减去最小值,然后除以值的范围,将所有数据的值缩放到 0 和 1 之间。
平均值规范化:确保数据的值介于(-1)和 1 之间,平均值为 0。我们减去平均值,除以数据的范围。

然而,我们在准备特征时,只测量测试集上的度量因子、平均值和标准差是很重要的。如果我们在整个数据集上测量这些因素,由于信息暴露,算法在测试集上的性能可能会比在实际生产中更好。
手动调整神经网络模型的超参数可能非常繁琐。这是因为当涉及到超参数调整时,没有科学的规则可供使用。这就是为什么许多数据科学家已经转向自动超参数搜索,使用某种基于非梯度的优化算法。
为了了解如何在权重和偏差的情况下找到模型的最优超参数,让我们看看 mask r-cnn 计算机视觉模型的这个例子(https://www.wandb.com/articles/mask-r-cnn-hyperparameter-experiments-with-weights-and-biases)。
为了实现语义分割任务的 mask r-cnn,connor 和 trent 调整了控制模型运行方式的不同超参数(https://github.com/connorhough/Mask_RCNN/blob/master/mrcnn/config.py):学习速率、梯度剪辑归一化、权重衰减、比例、各种损失函数的权重……他们想知道图像的语义分割是如何进行的。由于模型使用不同的超参数进行训练,因此他们集成了一个 imagecallback()类(https://github.com/connorhough/Mask_RCNN/blob/master/samples/coco/coco.py)来同步到 wandb。此外,他们还写了一个脚本(https://github.com/connorhough/Mask_RCNN/blob/master/samples/coco/inspect_weights.ipynb),用于运行参数扫描,这些扫描可以适应不同的超参数或同一超参数的不同值。
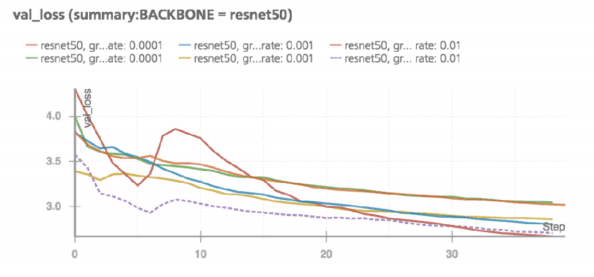
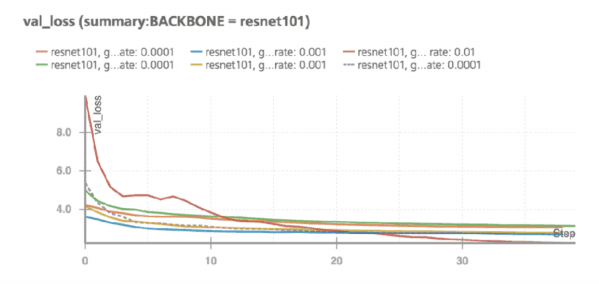
他们的结果可以在 Wandb Run 页面上找到(https://app.wandb.ai/trentwatson1/mask-rcnn/runs)。高梯度裁剪集和高学习速率可以提高模型精度,在迭代次数增加的情况下,验证损失分数会迅速下降。
其中最重要的超参数之一是学习速率,这是很难优化的。学习速率小导致训练速度慢,学习速率大导致模型过度拟合。在寻找学习速率方面,标准的超参数搜索技术不是最佳选择。对于学习速率,最好执行一个行搜索并可视化不同学习速率的损失,因为这将使你了解损失函数的行为方式。在进行直线搜索时,最好以指数方式提高学习率。你更可能关心学习速率较小的区域。
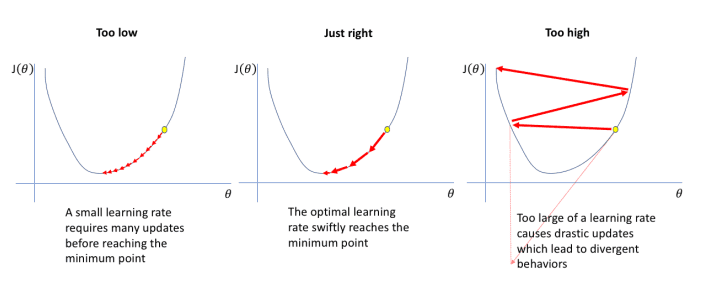
一开始,我们的模型可能离最优解很远,因此,我们希望尽可能快地移动。然而,当我们接近最小损失时,我们希望移动得更慢以避免超调。因此,我们应该定义一个学习速率表,以便在训练期间根据指定的规则更新速率。
调试模型的一个重要部分是,在投入大量时间训练模型之前,先搞清楚什么时候会出问题。wandb 提供了一种无缝的方式来可视化和跟踪机器学习实验。你可以搜索/比较/可视化训练运行,分析运行时的系统使用指标,复制历史结果,等等。安装完 wandb 之后,我们要做的就是在我们的训练脚本中包含这段代码:
import wandbargs = …wandb.init(config=args, project=”my-project”)wandb.config[“more”] = “custom”def training_loop():while True:epoch, loss, val_loss = …wandb.log({“epoch”: epoch, “loss”: loss, “val_loss”: val_loss})
或者,我们可以将 Tensorboard 集成在一行中(https://docs.wandb.com/integrations/tensorboard):
wandb.init(sync_tensorboard=True)
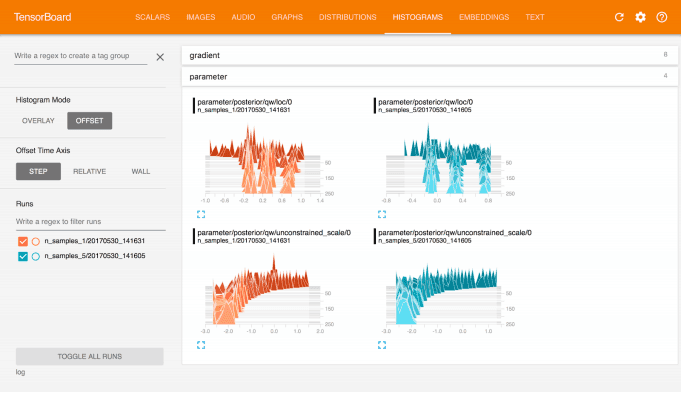
TensorBoard 是 TensorFlow 扩展,它允许我们在浏览器中轻松监视模型。为了提供一个接口,我们可以从中观察模型的进程,tensorboard 还提供了一些对调试有用的选项。例如,我们可以在训练过程中观察模型的权重和梯度的分布。如果我们真的想深入研究这个模型,tensorboard 提供了一个可视化的调试器。在这个调试器中,我们可以逐步执行 tensorflow 模型并检查其中的每个值。如果我们正在研究复杂的模型,比如变分自动编码器,并且试图理解复杂事物为什么会崩溃,这一点尤其有用。
我们现在有大量的工具可以帮助我们运行实际的机器学习项目。确保模型在部署之前能够正常工作是至关重要的,如果不这样做,我们会损失很多钱。希望这篇博客文章能为你提供实用的技术,使模型具有通用性,易于调试。
via:https://mc.ai/six-ways-to-debug-a-machine-learning-model/








