本篇分享论文Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation,Mogao:让AI同时创作文字和图像的创新模型。

- 论文链接:https://arxiv.org/pdf/2505.05472
引言
人工智能(AI)近年来在文本生成和图像生成领域取得了显著成就。例如,语言模型可以生成流畅的文章,而图像生成模型可以根据文本描述创建逼真的图片。然而,将文本和图像无缝结合,生成交错的、连贯的多模态内容,仍然是一个技术难题。
几天前字节跳动发布了一篇论文,介绍了一种名为Mogao的创新模型,它通过统一框架实现了交错多模态生成,为AI在创意和内容生成领域的应用开辟了新可能性。
Mogao的名字起的特别好,中文应该是来自“莫高窟”的莫高,这座坐落于河西走廊西部尽头的艺术宝库。
Mogao模型概述
Mogao是一个全能基础模型,专为处理和生成多种模态数据(特别是文本和图像)而设计。与传统的单模态生成模型或基于多模态条件生成模型不同,Mogao能够生成交错的文本和图像序列。例如,它可以生成一段描述森林的文字,随后生成一张森林的插图,然后继续生成下一段文字,形成一个连贯的故事。这种交错生成能力是Mogao的核心创新。
Mogao采用了一种因果生成方法,即逐步生成输出,每一步都依赖于前一步的内容。这种方法类似于语言模型逐词生成文本,但Mogao将其扩展到图像领域,结合了自回归模型(用于文本生成)和扩散模型(用于高质量图像生成)的优势。
技术创新
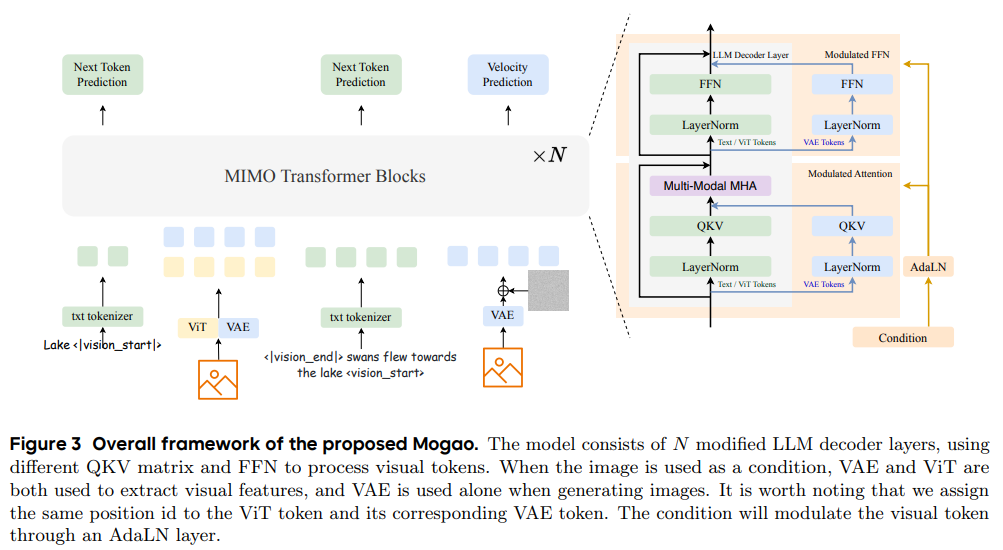
Mogao的成功得益于多项架构设计上的改进,包括:
- 深度融合设计(deep-fusion design):将文本和图像信息在模型的深层进行整合,确保两种模态的协同工作。
- 双视觉编码器(dual vision encoders):使用两个视觉编码器(变分自编码器和视觉变换器),分别处理图像的生成和理解任务。
- 交错旋转位置嵌入(IL-RoPE):一种新型的位置编码方式,适应交错的文本和图像序列。
- 多模态无分类器指导(multi-modal classifier-free guidance):改进了扩散模型的生成过程,使其在多模态场景下更有效。
这些技术细节虽然复杂,但它们共同确保了Mogao能够高效地处理和生成交错的多模态内容。
训练数据
该模型的训练数据包括纯文本、视觉理解、图像生成以及多模态交错数据四种类型。其中,纯文本和视觉理解类数据继承自DouBao的语言模型(LM)和视觉语言模型(VLM)数据集。为了提升图像的质量和多样性,模型采用了SeedDream中用于图像生成的相关数据。
在多模态交错数据方面,研究团队从公开可用的网站和视频中筛选并整理出训练材料。对于原生包含文本与图像的数据,训练时保留其原始的项目顺序。另外还使用了视频帧和相应字幕的数据,研究人员训练了一个视觉-语言模型,用以为视频中抽帧采样的每一帧生成对应的字幕说明,最终将图像帧和生成的字幕交织在一起,构成训练样本。
实验结果与性能
Mogao在多项基准测试中展现了卓越的性能,以下是其主要成果的详细分析。
多模态理解
Mogao-7B(拥有70亿参数的版本)在以下多模态理解基准测试中取得了最先进的表现: 与规模相当的Janus-Pro-7B的比较结果如下:Mogao在这些测试中不仅超越了同等规模的模型(如Janus-Pro-7B),而且在计算效率上也具有优势,其每token计算量相当于3.5亿参数模型。
与规模相当的Janus-Pro-7B的比较结果如下:Mogao在这些测试中不仅超越了同等规模的模型(如Janus-Pro-7B),而且在计算效率上也具有优势,其每token计算量相当于3.5亿参数模型。文本到图像生成
- GenEval:Mogao在单对象、双对象、计数、颜色等子任务中得分均高于0.80,整体表现优于SD3-Medium和Janus-Pro-7B。
- DPG-Bench:Mogao在全局、实体、属性、关系等指标上均表现出色,整体得分84.33。
- GenAI-Bench:在高级提示任务中,Mogao与DALL-E 3表现相当,尤其在计数和比较任务中得分较高。
人类评估结果
在人类评估中(基于Bench-240数据集),Mogao在文本-图像对齐和结构校正方面排名第一。专家评审员根据从1(极不满意)到5(极满意)的评分标准,确认Mogao生成的交错内容在质量和连贯性上优于Emu3-Gen和Janus-Pro。
消融研究
消融研究进一步验证了Mogao架构设计的有效性:
这些结果表明,IL-RoPE、双视觉编码器和深度融合设计显著提升了模型的生成和理解能力。
示例展示
Mogao的生成能力通过以下可视化示例得到了直观展示:
- 文本到图像生成:Mogao生成的图像在构图、色彩、现实与虚拟的交融以及情感表达方面表现出色,分辨率为512×512。

- 交错多模态生成:Mogao能够保持对象身份的一致性,并严格遵循指令生成交错的文本和图像序列。

- 零样本图像编辑:Mogao展示了添加、移除或修改图像元素的能力,体现了其灵活性和泛化能力。

潜在应用
Mogao的交错多模态生成能力为多种应用场景提供了可能性:
- 教育内容创作:生成带插图的教材或互动式学习材料,增强学生的学习体验。
- 创意写作与艺术:自动生成带插图的故事书、漫画或混合媒体艺术作品,助力作家和艺术家。
- 广告与娱乐:创建吸引人的多媒体广告或社交媒体内容,提升用户参与度。
- 图像编辑:通过零样本编辑功能,用户可以轻松修改图像,例如在照片中添加物体或更改背景。
例如,想象一个儿童故事应用,Mogao可以根据用户输入的故事主题,生成一段文字描述角色的冒险,随后生成一张插图,再继续推进故事。这种无缝的多模态内容生成将极大地丰富用户体验。
研究背景与团队
Mogao由字节跳动 Seed 团队开发,研究团队包括Chao Liao、Liyang Liu、Xun Wang、Zhengxiong Luo、Xinyu Zhang、Wenliang Zhao、Jie Wu、Liang Li、Zhi Tian和Weilin Huang等研究员。他们在论文中提到,Mogao的开发旨在推动统一多模态系统的发展,为未来的模型扩展奠定基础。
未来展望
Mogao的出现标志着多模态AI研究的一个重要里程碑。其交错生成和零样本编辑能力展示了基础模型在处理复杂任务时的潜力。然而,论文也提到了一些局限性,例如模型在处理极端复杂提示时的表现仍有提升空间。未来的研究可能集中在以下方向:
- 模型扩展:增加参数规模或优化训练策略,进一步提升性能。
- 多模态扩展:将模型能力扩展到音频、视频等其他模态。
- 实际部署:优化模型以在实时应用中高效运行,降低计算成本。
结论
Mogao通过创新的架构设计和高效的训练策略,成功实现了交错多模态生成,在多模态理解、文本到图像生成和零样本图像编辑等任务中展现了卓越性能。其潜在应用涵盖教育、创意、广告等多个领域,为AI在内容生成领域的未来发展提供了新的可能性。随着多模态AI技术的不断进步,Mogao可能成为这一领域的重要基石。
最新 AI 进展报道
请联系:amos@52cv.net









