点击上方“Datawhale”,选择“星标”公众号
第一时间获取价值内容

编辑:红色石头
报道:AI有道
https://www.zhihu.com/question/347847220
有哪些像 GAN 这种形式简单却功能强大的 idea?
1. 异常检查算法Isolation Forest(孤立森林)
作者:桔了个仔
https://www.zhihu.com/question/347847220/answer/836019446
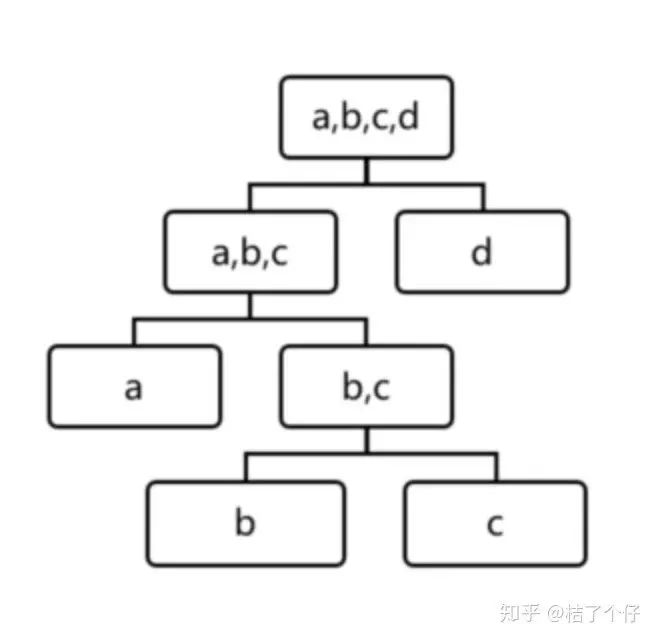
原理超简单,但检测效果可以说是state of the art. 对一个空间进行二分,早划分「孤立」出来的就是很可能异常的。「孤立」指的是这一边只有这一个数据点。因为是二分,我们可以构建一颗二叉树。例如下图的一棵树,第一次二分,左边有数据的a,b,c,右边只有d,那么d大概率就是异常点。为啥?想想你画一条线,把一把米分成了两边,左边只有一粒,那左边那粒很可能是离其他米粒很远。
为了更直观,有更多一步了解,请看下图,直觉上我们就知道 [公式] 是普通点, [公式] 是异常点。那么用Isolation tree怎么解释呢?
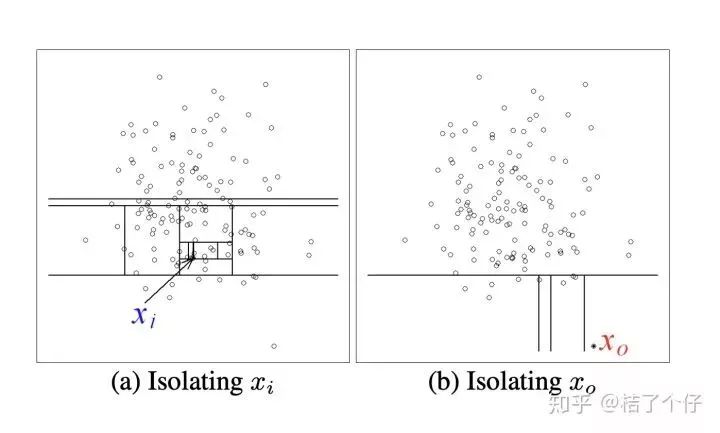
如果要把xi孤立出来,需要很11次划线,而x0需要的次数要少很多。所以x0比xi更可能是异常点。一棵树不够可信?没事,记得随机森林random forest不?没错,这里也引进一堆树。如果多数的树都在前几次分割时分出同一个点,那么这个点是异常点的概率就非常高了。
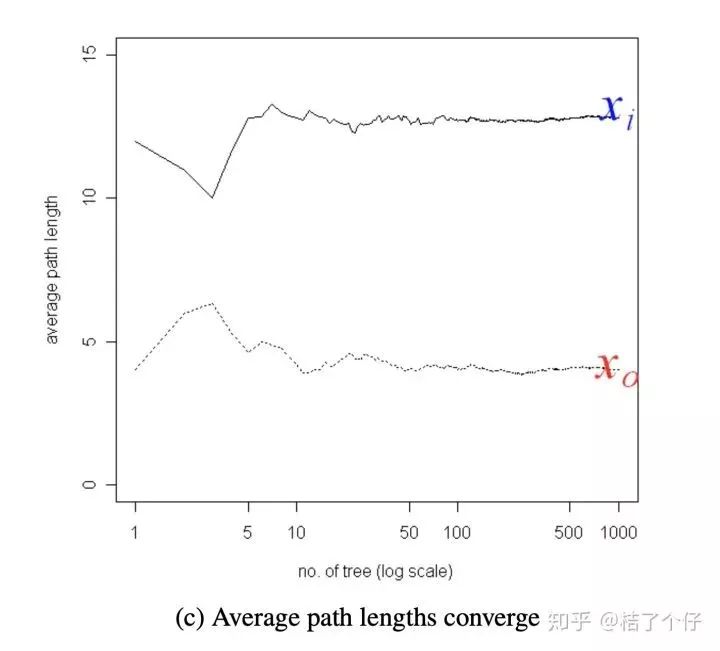
可以看到,树的数量(横轴)超过10时,平均分割次数(纵轴)就收敛了。从这个图我们可以看出,某个点x0 被「孤立」前,平均分割次数低于5,那么x0就是异常点。
原理是不是超级简单呢。如果想了解更多数学上的原理,可以参考下面的参考文献。
参考文献:
https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf
2. word2vec
作者:苘郁蓁
https://www.zhihu.com/question/347847220/answer/881216785
2013年Mikolov的神作word2vec,目前两篇paper的引用量已经达到15669和12670了!这个工作属于nlp预训练和graph embedding的里程碑,而且思想还贼好理解。
word2vec的思想可以简单的归结为一句话:利用海量的文本序列,根据上下文单词预测目标单词共现的概率,让一个构造的网络向概率最大化优化,得到的参数矩阵就是单词的向量。
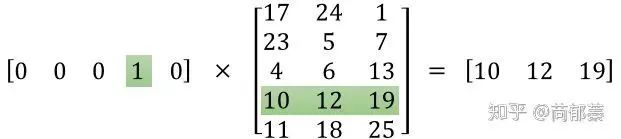
具体来说,对于Skip-Gram模型,就是给定句子中一个特定的词(input word),随机选它附近的一个词,网络的目标是预测选到这个附近词的概率。而对于CBOW模型则相反。而对于一个单词,先作one-hot,乘以参数矩阵,就得到了单词的向量表示,一图胜千言:
更加细致的negative sampling和hierarchical softmax都是针对训练问题的优化,但这一思想的本质就是很简单优雅。
举个简单的例子:词表大小为9的一段文本序列one-hot,乘以一个参数矩阵(蓝色部分),做均值pooling,乘以一个参数矩阵然后经过softmax层得到对应目标单词的概率向量(最后的红色部分),向量维度为词表大小,再根据ground truth反向传播优化参数矩阵,最后得到的就是类似图1的参数矩阵,列为词表大小9,行为词向量的维度4(注意:参数矩阵方向跟图1反过来了)。
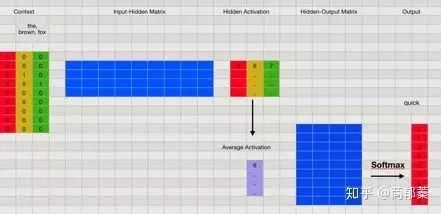
word2vec在nlp领域的应用就不用说了,目前已经成为所有nlp模型的标配步骤。
更令我吃惊的是它在其他领域的遍地开花。这里整理一下最近几年在其他领域的embedding工作合集,全部是顶会!全部都有落地!就是这么简单粗暴而优雅!

3. 成分分析(Principal components analysis,PCA)
作者:Evan
https://www.zhihu.com/question/347847220/answer/871450361

4. Residual learning
作者:我爱吃三文鱼
https://www.zhihu.com/question/347847220/answer/854604632
Kaiming大神的Residual learning:
形式:y = f(x) + x
影响了后续的3万份研究工作。
5. SVM
作者:Cuute
https://www.zhihu.com/question/347847220/answer/874707947
我不知道svm的形式算不算简单,但是从图上来讲很直观。
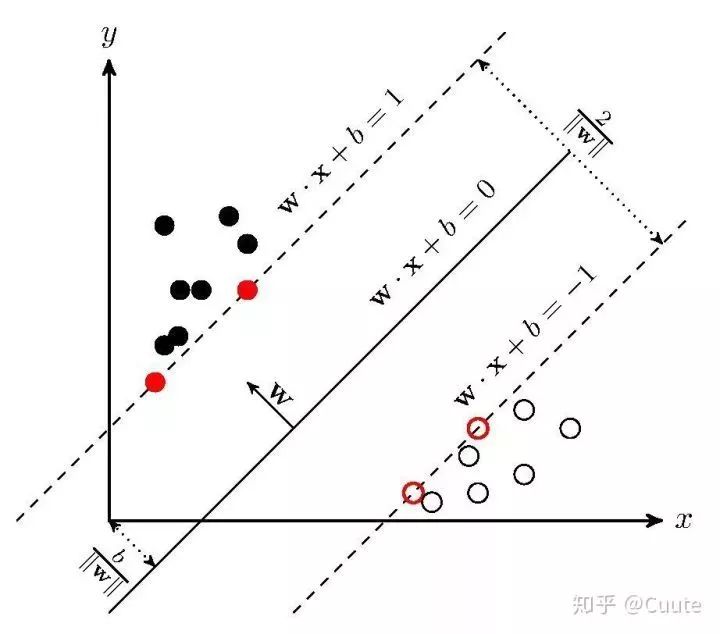
这个小东西是上个世纪六七十年代就已经提出来的一个想法。通过不同类别分界的某些点来画出一个分割面,进而实现了分类。很像夹逼定理。
svm的精巧在于这个想法,是一个很自然的方法,不用数学光看图就能看出来的一个方法。并且能很自然的去发散。
比如说,图中的两个类别的边界极其明显,是一个线性的边界。但是一定会存在这样的两类点,不能在当前的平面上使用一个线性的分类来解决。那么如果这些点只是三维向二维平面的投影呢?
如果这两类点是有高度差的,那么是不是有可能还会找到一个分界面在三维空间进行分类?
三维找不到,那会不会是四维……
于是,我们引出了核方法。
最后,你觉得机器学习中有哪些形式简单却又很巧妙的 idea?欢迎留言评论~
Dtawhale高校群和在职群已成立
扫描下方二维码,添加负责人微信,可申请加入AI学习交流群(一定要备注:入群+学校/公司+方向,例如:入群+浙大+机器学习)

▲长按加群









