大家好~今天跟大家分享的案例是关于“分类”的深度学习案例,从之前的案例中我们知道深度学习在图片分类上效果十分强大。比如说,深度学习一个经典的分类问题是“猫狗大战”,即让AI看一张图片,然后它将告诉你这张图片里是究竟是猫还是狗。

由Kaggle举办的风靡一时的猫狗分类竞赛..
经过参赛选手们的不懈努力,在所有目前已公开的模型中,我们点开了一个获赞数较高的模型,它能够在训练集和测试集上同时取得接近90%的准确率。
横轴是训练次数,纵轴是准确率,粗的点是训练集结果,细的线是验证集结果..
既然AI能够在关于猫狗的二分类问题中取得这么好的效果,那我们试试加大力度,看一看AI能不能解决一些难度更高的图像分类问题呢~
在西方艺术发展历史上,艺术风格经历了多次变革,我们随机选取了四个时期,即中世纪、文艺复兴、后文艺复兴和现代艺术时期,然后把这些图片收集起来,分类别存在电脑里,作为数据准备。
下边给大家展示的四幅图,就分别是这四个时期的作品之一,有看官能认出来每一张图片分别属于哪一个时期吗?(相信大部分朋友应该和我一样傻傻分不清~~)
所以有人能告诉我图3是啥吗..
我们通过公开网站找到各个时期的画作,作为演示案例,随机选取了每个时期的一部分画作进行分析,包括中世纪(80张)、文艺复兴(80张)、后文艺复兴(80张)、现代艺术(90张)。按照深度学习的数据划分方式,我们把这些照片储存在训练集文件夹(/data/train)和测试集文件夹(/data/validation),每个时期的画作又各自储存在各自的文件夹中。
图像数据生成器:在读入每一张图片的同时,对图像进行像素增减、旋转、平移或放缩等操作,达到识别度更高的效果,也就是所谓的“数据增强”。
从深度学习库keras中导入ImageDataGenerator这个类,然后对图像的变换进行声明,在创建这个类的时通过传入参数达到想要的效果,以下是每一个参数的含义。
除了传入参数以外,IMSIZE是我们传入图片的大小,train_generator是训练集数据生成器,validation_generator是测试集数据生成器。
在使用ImageDataGenerator时,调用flow_from_directory函数,它告诉程序target_size(图像大小)是299×299,batch_size(每次训练图片的数量)是50,class_mode是'categorical',声明这是一个多分类问题。在测试集生成器中也传入了相应的参数,具体的参数取值可以在代码中找到哦~以下是详细代码:
from keras.preprocessing.image import ImageDataGenerator
IMSIZE=299
train_generator = ImageDataGenerator(
rescale=1./255,
shear_range=0.5,
rotation_range=30,
zoom_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True).flow_from_directory(
'../case2-picture style/data/train',
target_size=(IMSIZE, IMSIZE),
batch_size=50,
class_mode='categorical')
validation_generator = ImageDataGenerator(rescale=1./255).flow_from_directory(
'../case2-picture style/data/validation',
target_size=(IMSIZE,IMSIZE),
batch_size=20,
class_mode='categorical')
当我们使用数据生成器的时候,需要配合next()函数来查看每次读入数据的具体情况。因为自变量(图片)和因变量(类别)都需要用到numpy包里的数据格式来储存,所以我们会导入这个包。代码和结果如下:
import numpy as np
X,Y=next(validation_generator)
print(X.shape)
print(Y.shape)
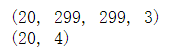
我们看到,自变量X,也就是每一次读入的图片集,有20张,长是299,宽是299,是三通道的彩色图片。对于因变量Y,也是有20个对应的值,4分别代表4个不同的绘画时期类别。
接下来让我们看看这些绘画作品具体长啥样吧!使用matplotlib可视化包进行绘制。plt.figure()创建了一张画布,fig,ax = plt.subplots(2,5)指明了每一张图片的位置,要用2行5列的方式摆放;fig.set_figheight(10)和fig.set_figwidth(20)对图像的长宽做了声明,即展示宽度为10,展示长度为20,ax=ax.flatten()把ax这个2行5列的矩阵拉直成一个长度为10的向量,方便我们直接使用后面的for循环放置图片~
from matplotlib import pyplot as plt
plt.figure()
fig,ax = plt.subplots(2,5)
fig.set_figheight(10)
fig.set_figwidth(20)
ax=ax.flatten()
for i in range(10):
ax[i].imshow(X[i,:,:,:])

都是艺术啊!..
众所周知,当我们做分类问题时,第一个想到的应该是逻辑回归模型,下面是使用keras搭建逻辑回归模型的代码,Input([IMSIZE,IMSIZE,3])声明了传入图像的三个维度,即长、宽、通道数;BatchNormalization()是深度学习神经网络中一个广泛应用的层,它使得这一层神经网络的输入变换到相同的分布上去,在大部分实验中被证实十分有效;Flatten()层是把299×299的图像拉直成为一个长向量,这是因为逻辑回归的参数只能是一个维度的(参考线性回归的β1到βn),Dense(4,activation='softmax')是全连接层,是把4个神经元的值作为输入,连接到一个神经元上,作为输出,连接的方式是什么呢?这里说了,是使用激活函数activation='softmax',softmax是输出四个值中最大的那个,在这里代表了每张画属于四个类别的概率,当然是要概率最大的那个!最后,我们用Model(input_layer,output_layer)把所有的层连接起来,赋值给model1,然后用model1.summary()查看每一层的情况~逻辑回归的代码如下:
from keras.layers import Flatten,Input,BatchNormalization,Dense
from keras import Model
input_layer=Input([IMSIZE,IMSIZE,3])
x=input_layer
x=BatchNormalization()(x)
x=Flatten()(x)
x=Dense(4,activation='softmax')(x)
output_layer=x
model1=Model(input_layer,output_layer)
model1.summary()
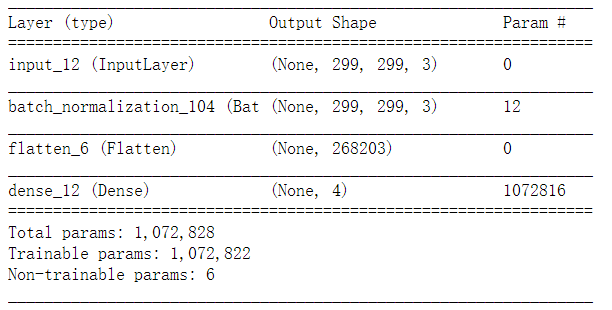
接下来是训练过程,使用model1.compile()传入参数,定义损失函数loss= 'categorical_crossentropy',为“交叉熵”损失函数,这是分类问题最常用的损失函数。优化器optimizer是学习率为0.01的Adam算法,这也是比较常用的配置。metrics=['accuracy']指在训练过程中监督“准确率”这个指标。最后用model1.fit_generator()进行训练,传入之前准备好的训练集和验证集数据,训练轮数epochs取值为50。
from keras.optimizers import Adam
model1.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.01),metrics=['accuracy'])
model1.fit_generator(train_generator,epochs=50,validation_data=validation_generator)

逻辑回归的训练结果如上,测试集上的准确率差不多可以达到35%左右,如果盲猜的话,准确率大概是25%(就像平时做四选一单选题?..)。如果以这个准确率作为基准,那么逻辑回归的结果还算是可以的。接下来,我们利用两个在图像识别领域赫赫有名的神经网络来训练这个数据集,一个是AlexNet,另一个是InceptionV3。
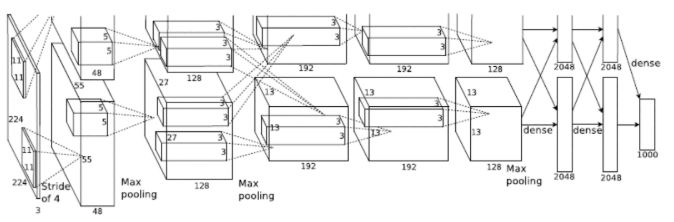
看着就很吓人的AlexNet网络层..
现在我们来做细致地拆分,讲讲AlexNet的网络结构!
…
…
(不会有人真的想听吧?)
(有兴趣的同学请期待狗熊会新作《深度学习入门》,文风风趣又不失专业性,内容严谨,覆盖面广,很值得收藏和阅读!)
简单来讲,AlexNet在神经网络领域的主要创新(贡献)在于,成功验证了激活函数ReLU的效果好于当时普遍使用的Sigmoid,另外还有以下几点(节选自《深度学习入门》)
1. 训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合,一般在全连接层使用。
2. 在CNN中使用重叠的最大池化(步长小于卷积核)。
3. 提出LRN(Local Response Normalization,即局部响应归一化)层,逐渐被BN(Batch Nomalization)所代替。
4. 使用CUDA加速神经网络的训练,利用了GPU强大的计算能力。受限于当时计算能力,Alexnet使用两块GPU进行训练。
5. 数据增强,随机地从256×256的图片中截取224×224大小的区域(以及水平翻转的镜像)。
我们在这里只简单看看ReLU和Sigmoid的区别:
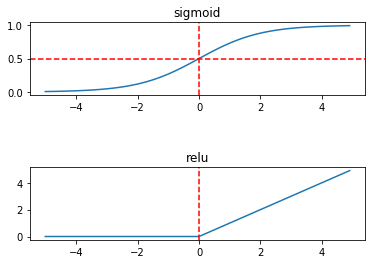
Sigmoid存在“梯度消失”的现象,即一阶导趋于0,而relu在正半轴上并不会..
下面是AlexNet模型的代码,相比于逻辑回归,多出来的几个函数主要是Conv2D和MaxPooling,以下面这段代码为例
Conv2D(96,[11,11],strides = [4,4], activation = 'relu')(x)
其中,96代表卷积核的个数,[11,11]是卷积核的大小,strides是步长,激活函数为relu。对于池化层参数解释类似,在此不进行赘述。
MaxPooling2D([3,3], strides = [2,2])
AlexNet完整的生成代码如下:
from keras.layers import Activation,Conv2D, BatchNormalization, Dense
from keras.layers import Dropout, Flatten, Input, MaxPooling2D, ZeroPadding2D
from keras import Model
IMSIZE = 227
input_layer = Input([IMSIZE,IMSIZE,3])
x = input_layer
x = BatchNormalization()(x)
x = Conv2D(96,[11,11],strides = [4,4], activation = 'relu')(x)
x = MaxPooling2D([3,3], strides = [2,2])(x)
x = Conv2D(256,[5,5],padding = "same", activation = 'relu')(x)
x = MaxPooling2D([3,3], strides = [2,2])(x)
x = Conv2D(384,[3,3],padding = "same", activation = 'relu')(x)
x = Conv2D(384,[3,3],padding = "same", activation = 'relu')(x)
x = Conv2D(256,[3,3],padding = "same", activation = 'relu')(x)
x = MaxPooling2D([3,3], strides = [2,2])(x)
x = Flatten()(x)
x = Dense(4096,activation = 'relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096,activation = 'relu')(x)
x = Dropout(0.5)(x)
x = Dense(4,activation = 'softmax')(x)
output_layer=x
model=Model(input_layer,output_layer)
model.summary()
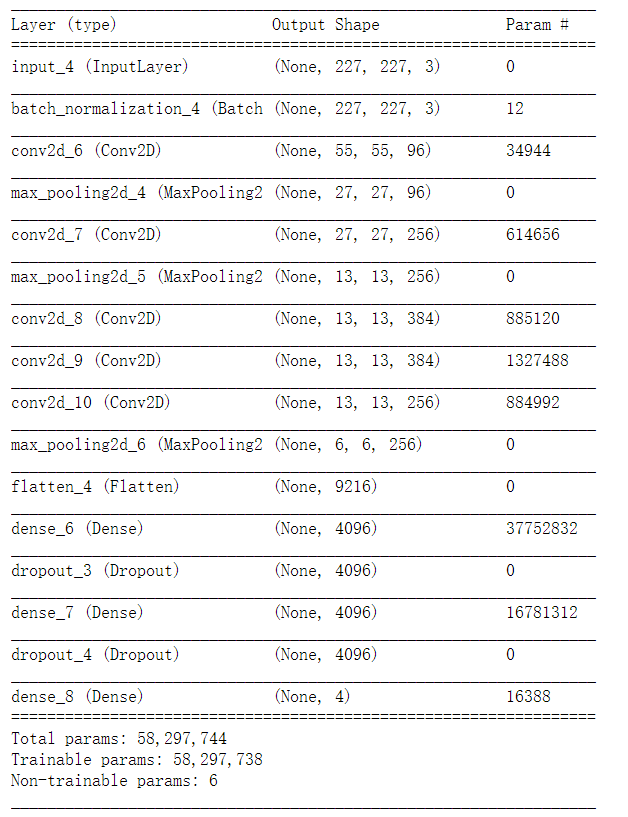
接下来我们用AlexNet模型训练我们的绘画作品分类,结果如下:
from keras.optimizers import Adam
model.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.001),metrics=['accuracy'])
model.fit_generator(train_generator,epochs=50,validation_data=validation_generator)

AlexNet在测试集上的准确率可以达到57.5%,是一个不错的提升!接下来让我们再看看InceptionV3模型的效果。
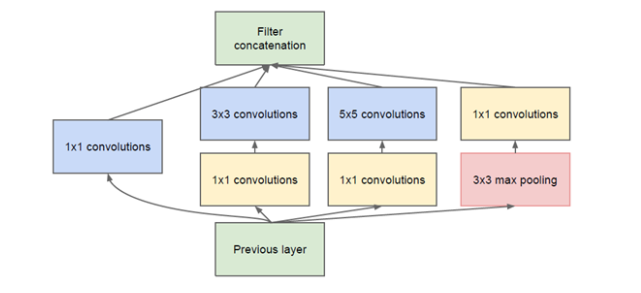
这是Inception网络的一个模块,可以看作层的集合..
Inception系列网络的创新在于同时使用多个不同尺寸的卷积核,同时大量使用1×1的卷积核,它带来的好处之一是需要训练的参数减少了,想更深入了解Inception系列网络结构的朋友可以找来相关的材料进行阅读,这里我们就不详细展开了。
由于InceptionV3的网络结构十分庞大,在计算资源有限的前提下,训练起来相当困难,所以我们选择“站在牛人的肩膀上”,通过迁移学习的方法用InceptionV3模型实现这里的绘画分类任务。
迁移学习:简单来讲,“迁移学习”是把别人训练好的模型参数结果直接拿过来,应用到我们当前的任务中,这个过程就叫“迁移”。由于迁移学习要用到别人训练出的模型结构和参数估计,因此我们需要一个文件,这个文件不仅包含了模型结构,还包含了这个模型当时训练出来的所有参数,这些参数很可能来自一个巨大的数据集,例如ImageNet,幸运的是这些文件就在keras上。接下来我们看一下如何迁移学习InceptionV3模型。
首先,从keras.applications.inception_v3导入叫做InceptionV3的程序包。第一行base_model = InceptionV3是基础模型,其中InceptionV3是keras的关键字,它表示这是一个提前训练好的InceptionV3 model。里面有两个参数,第一个weights='imagenet',表示模型的权重是从imagenet上训练出来的,第二个参数是include_top=False,表示没有迁移学习整个InceptionV3模型,它的顶层的输出神经元节点被砍掉。
接下来定义输入x=base_model.output,从这个位置开始,它的底部是base_model,也就是Inception V3模型,从X开始就是我们的模型需要定义的。首先,对X的每一个通道分别做一个GlobalAveragePooling。经过这个操作之后,X变成一个向量,然后直接做一个以两神经元为输出节点的全连接层,把它赋给一个变量叫做predictions。至此我们有了输入和输出,输入是base_model.input,输出是 predictions。
最后,我们将别人训练好的权重也迁移学习过来,此时只需要用命令layer. Trainable=false即可,也就是我们不要再训练模型,这意味着当年在ImageNet上所训练出来的权重已经被全部都被继承下来了,最后可以用model.summary()查看模型结构(网络层过于庞大,无法展示)。
from keras.applications.inception_v3 import InceptionV3
from keras.layers import GlobalAveragePooling2D, Dense, Activation
from keras import Model
base_model = InceptionV3(weights = ‘imagenet’,include_top=False)
base_model.load_weights('../work/pretrain/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5')
x = base_model.output
x = GlobalAveragePooling2D()(x)
predictions = Dense(4,activation='softmax')(x)
model=Model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers:
layer.trainable = False
model.summary()
迁移学习的结果如下,在这个四分类问题中,InceptionV3的分类准确率达到了73.75%!看到这里,小编不由得发出感慨
from keras.optimizers import Adam
model.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.001),metrics=['accuracy'])
model.fit_generator(train_generator,epochs=50,validation_data=validation_generator)


这个案例到这里就告一段落了~看了这篇案例,读者有什么想说的吗,欢迎在评论区留言~
✦ 案例来源:本案例改编自中国人民大学统计学院2016级本科生统计软件课程小组作业
✦ 小组成员:黄实磊,刘平安,杨春白雪,杨利娟,林祉伊,鲁瑶
✦ 案例的后期制作:漆岱峰










