本文约4700字,建议阅读13分钟
本文简要介绍了作者在初次进行机器学习的操作时所遇到到情况与得到的教训。机器学习之旅的开端
在这片博客中,我将介绍队友(Aron,Ashish,Gabriel)和我如何完成我们的第一个机器学习项目。写这篇博客的目的是为了记录——记录下我作为一名有抱负的数据科学家的旅程。同时,这篇博客也是为了写下逐步完善预测模型背后的思维和推理过程。由于我的目的是建立一个可以快速使用的通用工作流程,所以我将尽可能的简化推理过程。我的最终目标是当某一天再次回顾这个数据集时,可以应用更好的预测模型,看到自己原本可以做出哪些改进,并且能看到自己作为一个数据科学家的成长。数据集
该数据集取自kaggle.com。它包含了79个描述房屋特征的维度,而且描述了爱荷华州埃姆斯几乎所有的房屋。该数据集旨在为有志向的机器学习从业者提供一个玩具示例。在处理这个数据集时我们得到的主要教训是:简单的线性模型也可以十分强大,并且在适当的场景中,它们的表现可以轻松地胜过高度复杂的模型。在接下来的文章中,我将描述我们处理这个数据集所遵循的工作流程,并证实线性模型应该始终在你的工具箱中占有一席之地。数据预处理的工作流程
数据预处理和转换
我们遵循了得到的第一个建议:将目标变量(售价)转化为一个服从正态分布并去除了异常值的变量。前者很重要,因为它确保目标变量的残差将服从正态分布(线性推理模型的基本假设),而后者可以确保我们的模型结果不会因为异常的观测值,特别是那些有很大影响和杠杆效应的值,而产生偏斜(或成为错误的偏差)。下面将举例说明对数转换(log transformation,我们的手动box-cox转换):
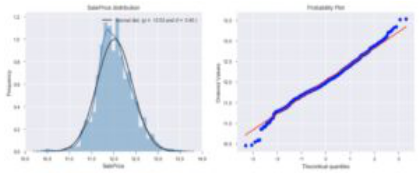
在上方的图片中,显示了高度倾斜且未经处理的数据。在下方的图片中,我们展示了经过对数转换后的数据。将两者进行比较,我们可以看到数据在分布上的巨大改进。
在这里我们没有对各个特征进行转换,来使其变成正态分布。虽然,机器学习模型可能会因使用了正态分布的特征而受益,但这将损害结果模型的可解释性。出于这个原因,我们选择不去应用它,而是继续使用去除异常值的方法。下面,我们展示了删除某个变量的异常值后的效果:
左边是未处理的数据,右边是处理过的数据。去除异常值的效果是明显的,因为我们可以看到拟合线发生了明显的偏移。
缺失值与插补
在第二步中,我们花了大量的时间去查找缺失值。而插补却是十分棘手的,因为它需要我们对每一个特征都有深刻的理解。不论是使用均值、中位数、众数、零、空,还是简单地删除观测值或特征本身,都取决于我们认为可以接受的某种预定准则。这种预定准则很多时候靠直觉。下面,我们对缺失值进行定性总结。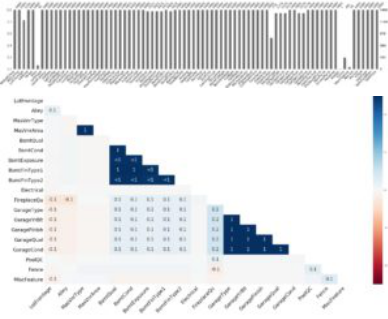
顶部显示的是每个特征的缺失值的数量,底部显示的是缺失之间的相关性。
这里我没有深入的探讨处理每个变量缺失值的具体过程(读者可以参考我们在Github上发布的代码来获得具体的解决办法),而是简单地回顾了一下总体思路。首先,在原则上,任何缺失值超过95%以上的变量都可以被安全地丢弃,但在做之前还是要谨慎一些,因为这些缺失不一定是真实的缺失。从变量缺失值的相关性中提取信息,我们也许可以推断出这些缺失值的含义。例如,与车库紧密相关的缺失值表明了一个房屋没有车库的可能性。另一个基本完全缺失的变量是泳池面积。因此,我们认为缺少泳池面积信息的房屋数据意味着这些房子没有泳池。
在这里,我们给出如何在严重缺失的情况下处理变量(一般来说,我们选择保守的方式,即尽可能保留我们可以保留的任何信息)。对于缺失率相对较低的变量(比如缺失值少于5%的观测数据),如果变量是连续的(或有序的),我们选择使用均值进行插补;如果变量是类别型的,我们则会使用众数。平均估算法背后的原理是,插补的数据不会改变拟合的斜率,因此不会对模型结果产生偏差。至于众数和中位数(分别在类别变量或数值变量中使用),除了认为这些观测值归属为最具代表性的组之外,没有更好的解释。虽然这种方式可能会有缺陷,但有时便捷性会比精确性更为重要,特别是当缺失值数量很少的时候(这些特征的缺失值数量在数十个的时候)。为了使缺失值插补的过程更加精确,我会选择基于k近邻或者其他机器学习模型进行插补。另一种被广泛接受的插补方法是用一个非常边缘的数,例如-999(如果所有的观测值都是正实数)。然而,这种插补方法不适用于拟合解析方程的推理模型。因此本例中没有使用-999。第一轮特征选择
我们经常会听到维度诅咒。高维度可能意味着会产生共线变量,而它则会导致拟合系数不准确以及高方差。高维度可能意味着稀疏的数据,也可能意味着特征数量过多从而导致过拟合。这两种情况都不好,因为它们会产生性能较差的模型。相关性研究:消除多重共线性
特征选择的第一次尝试是为了减少系统内部的多重共线性。方法是执行相关性研究,同时对特征进行合并或删除。下面是多重共线性处理前后的相关图:
左侧是原始数据的相关图。右侧是处理后数据的相关图,其中的特征要么被删除,要么被合并。
通过对比可以看到,这种相关性(用深蓝色表示)大大降低了。这是通过去除或组合特征实现的。帮助我们做出正确决定的指标是基于对特征的R平方持续评估: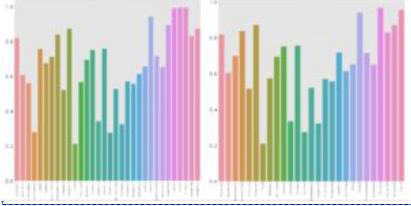
在左边的图中,与居住面积相关的变量(最后五分之一到最后三分之一)的R平方都大于0.8(大致等于VIF的5)。在右边的图中,适当组合特征后,与居住面积相关的R平方值降低了。
聚类子类别
类别型变量的子类别可以聚类在一起。下面我们来看一个例子:
在这个图中,我们可以看到,所有的不规则子类别(IR1到IR3)的均值都非常接近,但离规则的(Reg)很远。这是一个提示,在简化降低维度后,我们应该把所有的IR聚在一起。
在这个特殊的例子中,我们可以看到,如果我们将所有的不规则类别(IR1到IR3)分组到一个大的子类别中则可能对我们的模型产生有益的影响。之所以说是有益的,是因为在对变量进行哑变量处理之后,与未聚类子类别时相比,特征空间会相对较小。聚类的过程不是人工完成的,而是使用K-means聚类完成的(尽管它是一种非监督的方法),根据与目标变量相关的变量对子类别进行聚类(在这个数据集中,我们使用变量Gr living area)。特征工程注意事项:应当使用哪种算术运算?
特征工程可以通过交互来完成,而这种交互可以反映为任意两个或多个特征的某种算术运算。例如,乘法和加法可能在最终的模型结果中产生巨大的差异。我们总结出了一个很好的结论:每一个值必须始终服从变量的自然物理单位。例如,如果要合并车库数量和车库面积,应该通过乘法而不是加法来合并。在这种情况下,加法是没有物理意义的。事实上,对这两种操作的测试结果表明:对两个变量的乘法会导致VIF的显著下降,而加法则不会。
不同的社区拥有不同的销售价格。每一个都值得拥有属于它自己的模型。
通过观察社区图,我们可以看到每个社区的表现都是有区别的,并且每一个都遵循一个明确定义的行为。这些社区都有自己的模式。为了实现这一目标,我们创建了一个类似开关的交互参数,方法是将哑变量处理过的社区类别乘以Gr living area。这样,每个社区都可以有自己的一组系数——自己的方程,而不是简单的截距偏移 (类别型变量对广义线性模型的作用)。使用这个特征处理使我们的Kaggle排名下降了。数据流水线

数据集被分割成一个训练集和一个测试集,之后训练集被发送到五个模型中:三个线性模型(Lasso, 岭回归 弹性网络)和两个非线性模型(随机森林,梯度提升)。并对每个模型进行了广泛的网格搜索从而选出最佳超参数。在超参数最优的情况下,利用模型对测试集进行预测,并对测试结果进行比较。下面是初始特征工程的总结:
除了上面所显示的特征工程,我们还尝试了许多类型的特征工程和筛选(从数据集A开始直到数据集C,这些特征工程被依次实现)。虽然我们自己得到的MSE测试分数并不总是与Kaggle排名一致,但所有这些都产生了一个更糟糕的Kaggle排名。下面我们展示了使用数据集A到D的结果:
在图中我们可以看到,弹性网络模型相比于其他的模型有微小的优势。所有的线性模型都优于非线性的树模型。这很好的验证了我们一开始提到的内容:线性模型总有它的一席之地。在这个特定的数据集中,目标变量与其他特征主要体现了线性关系,这使得我们有充分的理由使用线性模型而不是非线性模型。综上所述,即使我们使用线性模型(较为简单的模型),我们的Kaggle和MSE分数肯定还将得到提高。我们之所以这么说的原因来自下面的图:

左边是测试和训练数据集MSE,右边是随机森林的数据集MSE。两者都显示出过拟合的迹象。
上图显示,测试和训练数据集MSE分数之间存在巨大的差异。对于树模型来说,这可能是有意义的,因为树模型往往会过拟合(当然,使用随机森林的目的正是为了避免这个问题);然而,惩罚线性模型 应该可以缓解这个问题……但事实并非如此。这意味着我们的确可以改进我们的特征筛选与处理。然而,我们尝试了大量的特征筛选操作,同时也考虑了如下图所示的基于特征重要性的排名,但是它们都给了我们负面的反馈。
这个图是Lasso(左)和随机森林(右)的特征重要性。要注意的是,这两个模型的特征重要性是不同的。随机森林模型比Lasso模型更强调连续变量的重要性,因为高基数会导致更大的误差或熵降。我们通过测试,比较了标签编码和one-hot编码,发现他们产生类似的结果(标签编码有轻微的优势),这就是标签编码比one-hot编码重要的原因。
鉴于特征特征的无用性,我们选择通过递归去除特征来蛮力改进我们的模型。这个想法如下图所示: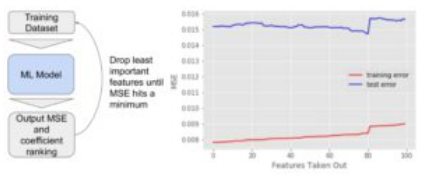
左边的示意图显示了我们递归地删除特征的过程。右侧显示了特征被逐渐删除时的MSE变化。突然的跳转很可能是由于一个重要的特征被删除了。
特征的最佳数量由测试误差突然跳跃的位置来表示。通过这种递归的方法,我们可以进一步提高我们的MSE分数: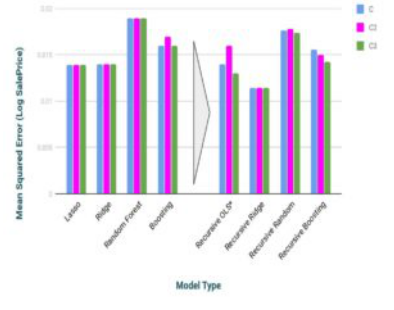
我们可以看到,使用机器来递归地删除特征是着实有效的。在递归地去除特征后,误差得分显著下降。
最后,我们选择通过集成所有不同的模型,来把所有的东西放在一起。我们是这样做的: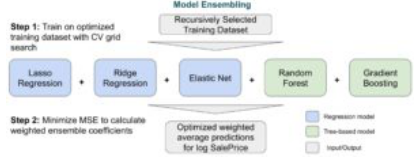
这张图展示了我们使用的集成技术,它很显然被称为堆叠。
集成技术只是不同模型预测值的线性组合。不同模型的权值是从最小化测试集错误分数的权值集中选取的。在将最终结果提交给Kaggle之后,我们的最终分数是0.1214。
尝试新事物和我的结论
作为我们的第一个机器学习项目,我们学到了很多。第一点,也是很重要的一点,我们亲眼看到了线性模型的力量。这是我们预料到的事实。第二点也是更深刻的教训是,我们看到了人类直觉的局限性。长时间的无用的特征工程对我们来说也是一个值得纪念的教训。在这些机器学习的问题中,我们应该始终在人类直觉和依赖机器之间取得平衡。我们花费了太多的时间热衷于研究数据集,尝试找出哪些数据在统计上是重要的或是不重要的,并且在删除特征时又过于犹豫。如果我们果断的处理这些操作,那么他们是很有益的。但问题是,这些EDA和统计测试的结论从来不是非黑即白的——他们很少产生有可操作性的反馈。我们应该做的是,在跟随机哑变量比较重要性时,更快速地研究线性和非线性模型给出的特征重要性。与此同时,我们应该花更多的时间来研究如何执行相关特征子集的PCA。尽管我们在人工特征处理方面做了很多努力,但最终我们仍然遭受了多重共线性的困扰。我们需要更明智地使用机器学习技术。因此,我们从中得到的教训是显而易见的。当然,我们下次会做的更好。原文标题:
My First Machine Learning Project
原文链接:
https://nycdatascience.com/blog/student-works/my-first-machine-learning-project-a-somewhat-generalized-workflow-with-after-thoughts/
编辑:于腾凯
校对:林亦霖
王紫岳,悉尼大学Data Science在读研究生,在数据科学界努力奋斗的求知者。喜欢有挑战性的工作与生活,喜欢与朋友们热切交谈,喜欢在独处的时候读书品茶。张弛有度,才能够以最饱满的热情迎接有点忙碌的生活。
【奏响2019大数据与人工智能最强音】
2019世界互联网大会互联网之光博览会之BDAI赋能100万亿实体经济,2天,4场,56位嘉宾分享,2大产业地图,7大权威榜单:
热点!《2019数据中台建设之道高峰论坛》
“数据中台八骏”视频回放链接
:https://play.yunxi.tv/livestream/d80b9e2e402145a0bdc1d9332fae02be
【详细议程、嘉宾介绍及视频回放二维码,请点击下图】

❶《2019DTiii版中国大数据产业地图(3352家)》;
❷《2019中国大数据创新企业TOP100》;
❸《2019中国大数据领军人物》;
❹《2019中国大数据创新企业亿元俱乐部》;
❺《2019中国大数据应用TOP CIO/CDO》;
❻《2019中国大数据应用最佳实践案例》;
❼《2019中国大数据新锐企业》;
❽《中国大数据行业应用Top Choice 2019》;
❾《中国大数据行业应用Top Choice 2019产业地图(185家)》
高清产业地图&PPT下载:
链接: https://pan.baidu.com/s/1WbJrCP7ZcmoTCRxwSVKDlQ 提取码: a41n
《2019DTiii版中国大数据产业地图(3352家)》
《中国大数据行业应用Top Choice 2019)产业地图(185家)》

点击图进入1360张 精彩高清图片和PPT精华内容!

PC版照片查看链接:https://v.alltuu.com/r/jqEvAn/
18个行业,106个中国大数据应用最佳实践案例:
(1)《赢在大数据:中国大数据发展蓝皮书》;
免费试读:https://item.jd.com/12058569.html
(2)《赢在大数据:金融/电信/媒体/医疗/旅游/数据市场行业大数据应用典型案例》;
免费试读:https://item.jd.com/12160046.html
(3)《赢在大数据:营销/房地产/汽车/交通/体育/环境行业大数据应用典型案例》;
免费试读:https://item.jd.com/12160064.html
(4)《赢在大数据:政府/工业/农业/安全/教育/人才行业大数据应用典型案例》。
免费试读:https://item.jd.com/12058567.html
推荐文章
微信ID:SDx-SoftwareDefinedx
❶软件定义世界, 数据驱动未来;
❷ 大数据思想的策源地、产业变革的指南针、创业者和VC的桥梁、政府和企业家的智库、从业者的加油站;
❸个人微信号:sdxtime,
邮箱:sdxtime@126.com;
=>> 长按右侧二维码关注。

 底部新增导航菜单,下载200多个精彩PPT,持续更新中!
底部新增导航菜单,下载200多个精彩PPT,持续更新中!









