
编者按:2019 年底、2020 年初,许多机器学习界活跃的教授、研究员们投身参与了一场的突如其来的讨论:到底什么是深度学习?
在过去十年汹涌而来的深度学习浪潮中,大家对深度学习在应用中体现出的各种特点已经非常熟悉了,但毕竟深度学习的理论仍未建立完善。更重要的是,大家已经意识到了深度学习的种种限制,那么想要破除限制、实现更高级的智慧时,就免不了需要思考,是「继续改进深度学习就可以达到目标」,还是「我们需要在深度学习之外另起炉灶」,这里也就引出了那个看似简单,但大家尚未达成共识的问题「深度学习是什么?」
不少学者最近都参与了这个讨论,AI 科技评论带大家回顾一下各方观点。
Keras 作者 François Chollet 这样说
Keras作者、谷歌大脑高级研究员 François Chollet 最先给出了自己的观点:
什么是深度学习?在 2019 年这个时间点,大家经常用到的那种深度学习定义大概是这样的:「它由一连串可微分的参数化的层组成,而且是用反向传播算法端到端地训练的」。不过这个说法在我看来太过狭隘了,它最多是「我们现在做的深度学习」的描述,而不是对深度学习本身的定义。
比如说,如果你有一个卷积网络模型,然后你用 ADMM 训练它的权重,它就不是深度学习了吗?一个自己学习特征的 HMAX 模型就不是深度学习了吗?甚至于,用贪婪算法逐层训练的深度神经网络就不是深度学习了吗?要我说的话,它们都是深度学习。
深度学习应该指的是一种表征学习方法,其中的模型是由一连串的模块组成的(一般都会堆成一个多层的或者金字塔形的模型,这也就是「深度」的由来),而其中的每一个模块分别拿出来训练之后都可以作为独立的特征提取器。我在我自己的书里也就是这么定义的。

通过这样的定义,我们也就能明确深度学习不是下面这样的模型:
- 不学习表征的模型,比如 SIFT 之类的人工特征工程,符号 AI,等等
深度学习的定义里不需要指定固定的某种学习机制(比如反向传播),也不需要指定固定的使用方式(比如监督学习还是强化学习),而且也不是一定要做联合的端到端学习(和贪婪学习相反)。这才是深度学习「是什么」的本质属性、根本结构。这之外的描述仅仅是「我们是如何做深度学习的」。
清晰的定义也就划分出了明确的边界,有的东西是深度学习,有的东西不是。2019 年随处可见的这种深度神经网络自然是深度学习,而用演化策略 ES、ADMM、虚拟梯度之类的反向传播替代方案训练的深度神经网络当然也是深度学习。
基因编程就不是深度学习,快速排序不是深度学习,SVM 也不是。单独一个全连接层不是深度学习,但很多个全连接层堆在一起就是;K-means 算法不是深度学习,但把许多个 K-means 特征提取器堆叠起来就是。甚至我自己在 2011 到 2012 年间,收集视频数据的位置的成对的共同信息矩阵,然后把矩阵分解堆叠在上面,也是深度学习。
一般的人类软件工程师用语言写出的程序不是深度学习,给这些程序加上参数、能自动学习几个常量,也仍然不是深度学习。一定要用成串连起来的特征提取器做表征学习,这才是深度学习。它的本质在于通过深度层次化的特征来描述输入数据,而这些特征都是从数据里学习到的。
根据定义也能看出来,深度学习是一种逐步完善的、一点点优化的从数据中提取表征的方法。以深度学习现在的形式来看,它至少是 C1 连续的(甚至到无限阶都是连续的)。这一条可能不那么关键,但「逐步优化」的这一条也是深度学习的固有属性。
所以深度学习和以往的符号运算 AI、常规编程都完全不同,它的基础结构就是离散的、以数据流为核心的,而且通常也不需要任何中间层的数据表征。
想用深度学习做符号运算也不是不可能,但需要引入很多额外的步骤。可话又说回来,深度学习模型也就只能囊括所有程序中的很小很小的一部分而已,没必要做什么都要用深度学习。
还可以再拓展一个问题:大脑是「深度学习」吗?我认可的只有这一种答案:大脑是一个复杂得难以想象的东西,它把许许多多结构不同的东西包括在内,而我们对大脑的了解还太少;大脑是不是深度学习,我们还给不出确定的答案。我有一个直觉是,大脑总体来说不是深度学习,不过其中的某一些子模块可以用深度学习来描述,或者是部分符合深度学习的,比如视觉皮层就有深度层次化的特征表征,即便这些表征不都是学习得到的;
视觉皮层也是深度学习的研究中重要的灵感来源。
我可以再补充一句,如果用树形结构来比喻的话,我们对现代的深度学习的理解和使用,主要还停留在早些时候发展的「现代机器学习」的这一枝上,和神经科学之间没多大关系。神经科学带来的影响主要在于高层次的新观念启发,而不是直接的模仿借鉴。
Yann LeCun 这样说
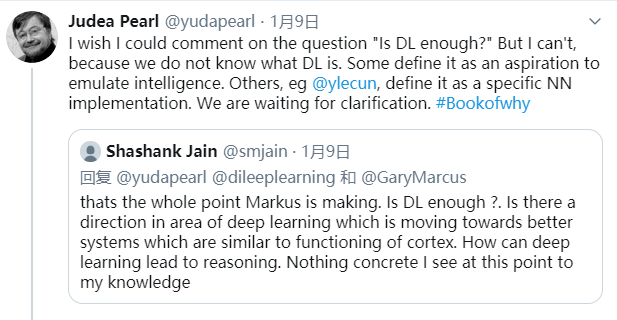
在另一条故事线上,深度学习三驾马车之一的 Yoshua Bengio 和「一直以来的深度学习黑粉」 Gary Marcus 的年度拌嘴留下了一个经典问题:「深度学习是否已经足够了?」("Is DL enough?")这也再次引出了「深度学习到底是什么」的讨论。2011 年图灵奖得主、贝叶斯网络之父 Judea Pearl 就表示「因为深度学习没有清晰的定义,所以我没办法回答深度学习是不是已经足够了」。
有一种据说来自 Yann LeCun 的定义是这样的:深度学习是一种方法论,是把多个参数化的模块组合成图(可以是动态图),构成模型,然后用基于梯度的方法优化它。LeCun 本人表示,如果这么定义深度学习的话,那深度学习还远远不足以解决目前已经遇到的问题,因为这个定义下的模型架构、优化目标、优化方法都有了具体的限制。
讨论中也有人提出,如果直接给出深度学习的定义有争议,不如我们列一列都有什么东西不是深度学习?LeCun 给出的答案是:逻辑回归、核方法、朴素贝叶斯、树&森林、K-means、K-NN 都不是深度学习,因为它们都不学习数据表征;此外,通过 0 阶方法(非梯度)优化的高度不可微分模型也不是深度学习,即便它们可以学习数据表征。
一两天的讨论之后,学者之间没能立刻形成广泛一致的共识。Judea Pearl 觉得有点失望,他自己做了这样一个总结:
虽然我没能看到什么好的定义,但是在「深度学习是什么」的讨论里我的感受是,做深度学习的人们似乎都非常相信深度学习还有无限大的潜力,他们沉醉在这些程序、技巧、术语里无法自拔。我想起了我高中时候学代数学到第二周、第三周时候的样子,我们也相信这些方法有无限的问题解决能力。但老师告诉我们,如果两个方程里有三个未知数,那你就解不出这个方程;听到这句话的时候我们不免会有一些失望,也感受到了自己的无知,但同时,这也让我们避免在无解的方程上浪费太多时间。只不过,朋友们,现在大家已经都不是高中生了。
LeCun 在下面和他继续讨论了起来:
所以你这是不接受我的定义了?我的定义是,深度学习是一种方法论,是把多个参数化的模块组合成图(可以是动态图),构成模型,设置一个目标函数,然后用某种基于梯度的方法优化它。如果要够「深」,那么这个图就需要在从输入到输出的流程上有许多个非线性阶段;这种深度也能让模型学到内部的表征。我的这个定义也没有指定具体的学习范式(有监督、无监督、强化学习),甚至连结构、目标也都不是定死的。
Judea Pearl 没有继续参与这个讨论,不过,对比 François Chollet 和 Yann LeCun 给出的答案,不难看出他们的大部分意见是一致的,只不过 LeCun 认为基于梯度的优化方法也是深度学习的一部分,而 Chollet 认为不用基于梯度的方法也可以 —— Chollet 定义下的深度学习就要更宽一些。
那么回到前面那个问题,即便认可 Chollet 的更宽一些的深度学习的定义,那么深度学习就够了吗?按照他的态度来说,也不够;我们有那么多种各式各样的方法,不需要死守深度学习不放。即便只是今天的已经能用深度学习的问题,也不是时时刻刻都需要用一个基于深度学习的解决方案。
从深度学习视角看旧模型
不过站在今天的深度学习的视角来看,一些经典方法看起来也变得有趣了。深度学习研究员、Fast.ai 创始人 Jeremy Howard 也参与了深度学习边界的讨论,他说逻辑回归现在看起来就像深度学习,它是一个一层深度的、参数化的函数模块,可以在数据样本上用基于梯度的方法训练。甚至,以他自己的感受来说,把 SVM 看作用 Hinge Loss 损失函数和 L1 正则化的神经网络要好学、好教得多。
LeCun 也表示赞同:「一个 SVM 就是一个两层的神经网络,其中,第一层的每一个神经元都会通过核函数把输入和某个训练样本做对比(所以其实第一层是一种无监督学习的平凡形式:记忆),然后第二层会计算这些输出的(经过训练后的)线性组合。」
很多参与讨论的网友都表示被这一条见解震惊了,其中有个人就说「有一次工作面试的时候他们让我实现 SVM 然后用梯度下降训练它,我心想卧槽这不就是个 Hinge Loss 的神经网络吗。本来这也不算多大的事,但是突然意识到以后觉得真的很神奇。」
也有网友接着追问:「可以不只有两层吧?你可以用很多层学习一个核函数,然后用最后一层计算核方法的预测规则。只要你施加一些规则,保证这个核是 Mercer 核,网络中起到核的作用的层的数量就可以不受限制」。LeCun 回答:「核函数可以任意复杂。但如果核函数是学习得到的,那这就已经是深度学习了…… 其实这就是我们训练 Siamese 网络,也就是度量学习(metric learning)的时候做的事情。这就像是训练一个相似度的核。最后只要你愿意的话,也可以在上面再增加一个线性层。」
祝福深度学习的新十年
文章结尾我想引用李飞飞高徒、特斯拉 AI 负责人 Andrej Karpathy 的一条推特作为结尾。
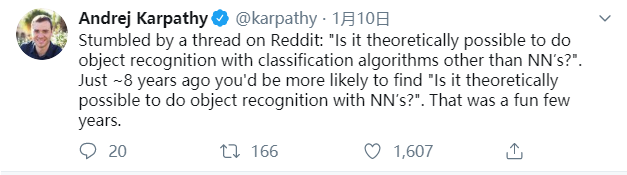
今天已经有网友会在 Reddit 上提问「想要用神经网络之外的方法做分类任务,理论上有可能吗?」但其实也就大概八年前你更容易看到的问题是「想要用神经网络方法做分目标识别,理论上有可能吗?」这几年的变化可真有意思。
我们乐于看到深度学习继续发展,理论更加完善、应用更加丰富、资源利用更加高效,但同时也希望更多研究人员和开发者可以意识到,深度学习并不是那个唯一的、最终的解决方案。我们期待在 2020 年、在这个新十年里看到更高级的、补充深度学习的不足的新方法。
AI 科技评论报道。

 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页









