
下载流式文件,requests库中请求的stream设为True就可以啦
先找一个视频地址试验一下:
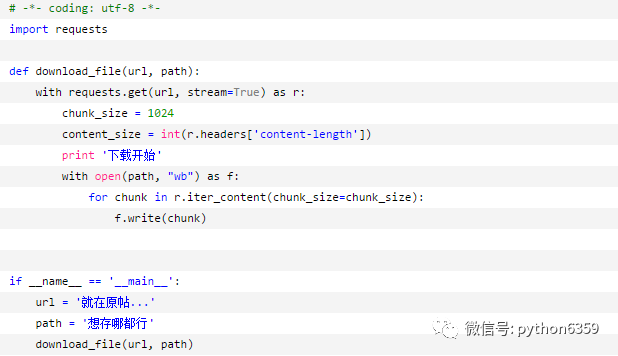
遭遇当头一棒:
AttributeError: __exit__
这文档也会骗人的么!
看样子是没有实现上下文需要的__exit__方法。既然只是为了保证要让r最后close以释放连接池,那就使用contextlib的closing特性好了:
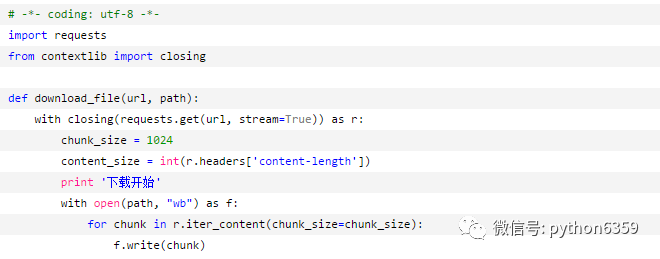
程序正常运行了,不过我盯着这文件,怎么大小不见变啊,到底是完成了多少了呢?还是要让下好的内容及时存进硬盘,还能省点内存是不是:
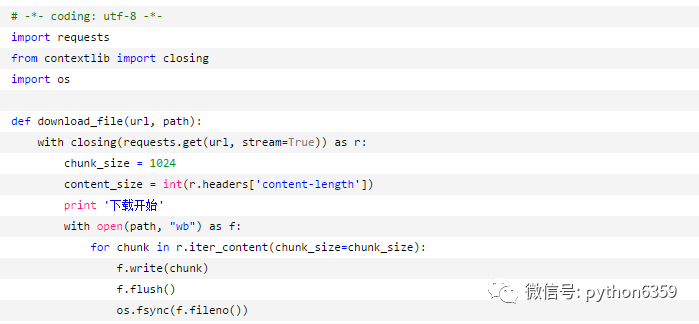
文件以肉眼可见的速度在增大,真心疼我的硬盘,还是最后一次写入硬盘吧,程序中记个数就好了:
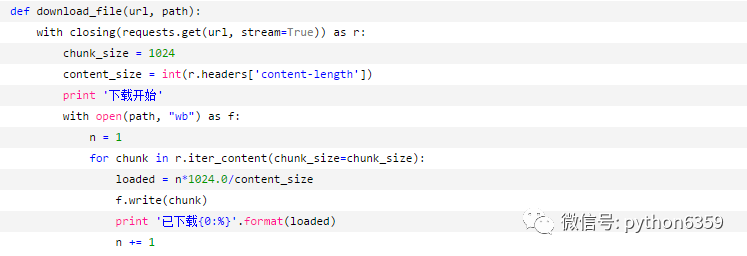
结果就很直观了:

心怀远大理想的我怎么会只满足于这一个呢,写个类一起使用吧:
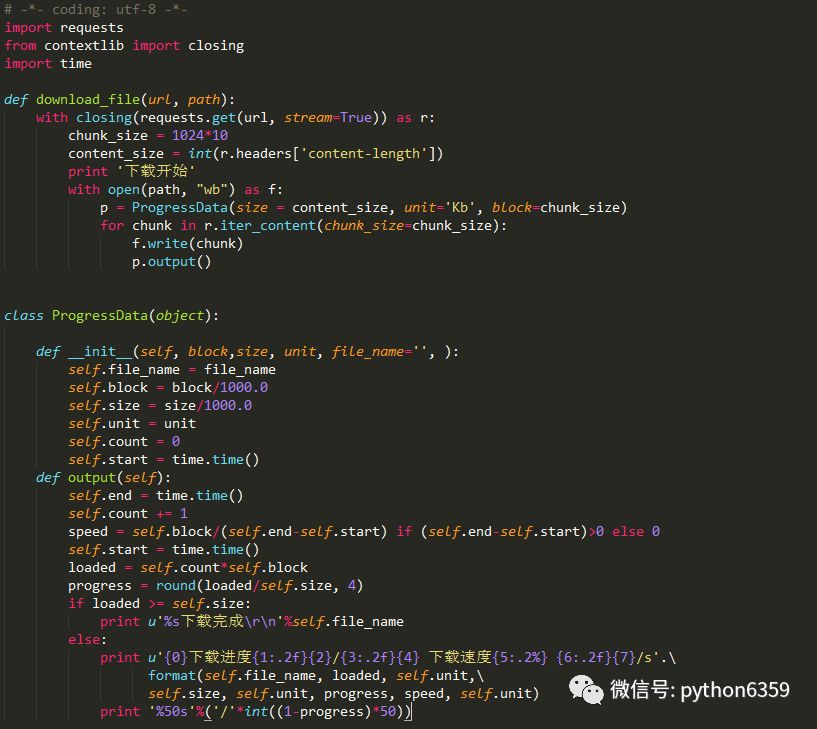
运行:

看上去舒服多了。
下面要做的就是多线程同时下载了,主线程生产url放入队列,下载线程获取url:
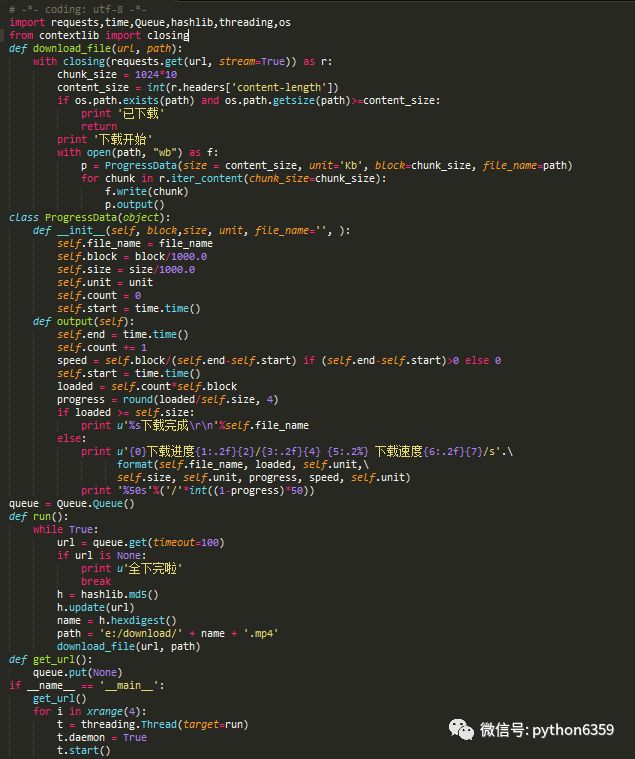
加了重复下载的判断,至于怎么源源不断的生产url,诸位摸索吧,保重身体!
作者:再见紫罗兰
源自:https://www.cnblogs.com/linxiyue/p/8244724.html
声明:文章著作权归作者所有,如有侵权,请联系小编删除










