本文来源:石杉的架构笔记(ID:shishan100)
MySQ索引的原理和数据结构能介绍一下吗?
b+树和b-树有什么区别?
MySQL聚簇索引和非聚簇索引的区别是什么?
他们分别是如何存储的?
使用MySQL索引都有哪些原则?
MySQL复合索引如何使用?
数据库是30k以内的工程师面试必问的问题,而且如果问数据库,一定是问mysql,N年前可能java工程师出去面试,oracle这块的技能是杀手锏,现在已经没人说,会oracle是加分项了,现在都是熟悉大数据hadoop、hbase等技术是加分项。其实就是让你聊聊mysql的索引底层是什么数据结构实现的,弄不好现场还会让你画一画索引的数据结构,然后会问问你mysql索引的常见使用原则,弄不好还会拿个SQL来问你,就这SQL建个索引一般咋建?至于索引是啥?这个问题太基础了,大家都知道,mysql的索引说白了就是用一个数据结构组织某一列的数据,然后如果你要根据那一列的数据查询的时候,就可以不用全表扫描,只要根据那个特定的数据结构去找到那一列的值,然后找到对应的行的物理地址即可。那么回答面试官的一个问题,mysql的索引是怎么实现的?
答案是,不是二叉树,也不是一颗乱七八糟的树,而是一颗b+树。这个很多人都会这么回答,然后面试官一定会追问,那么你能聊聊b+树吗?
但是说b+树之前,咱们还是先来聊聊b-树是啥,从数据结构的角度来看,b-树要满足下面的条件:(1)d为大于1的一个正整数,称为B-Tree的度。(3)每个非叶子节点由n-1个key和n个指针组成,其中d<=n<=2d。(4)每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null 。(9)每个指针要么为null,要么指向另外一个节点。(10)如果某个指针在节点node最左边且不为null,则其指向节点的所有key小于v(key1),其中v(key1)为node的第一个key的值。(11)如果某个指针在节点node最右边且不为null,则其指向节点的所有key大于v(keym),其中v(keym)为node的最后一个key的值。(12)如果某个指针在节点node的左右相邻key分别是keyi和keyi+1且不为null,则其指向节点的所有key小于v(keyi+1)且大于v(keyi)。 上面那段规则,我也是从网上找的,说实话,没几个java程序员能耐心去看明白或者是背下来,大概知道是个树就好了。就拿个网上的图给大家示范一下吧:我们现在对id建个索引:15、56、77、20、49select * from table where id = 49select * from table where id = 15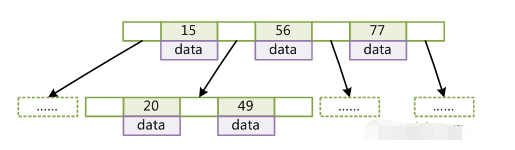
反正大概就长上面那个样子,查找的时候,就是从根节点开始二分查找。大概就知道这个是事儿就好了,深讲里面的数学问题和算法问题,时间根本不够,面试官也没指望你去讲里面的数学和算法问题,因为我估计他自己也不一定能记住。好了,b-树就说到这里,直接看下一个,b+树。b+树是b-树的变种,啥叫变种?就是说一些原则上不太一样了,稍微有点变化,同样的一套数据,放b-树和b+树看着排列不太一样的。而mysql里面一般就是b+树来实现索引,所以b+树很重要。每个节点的指针上限为2d而不是2d+1。
内节点不存储data,只存储key;
叶子节点不存储指针。
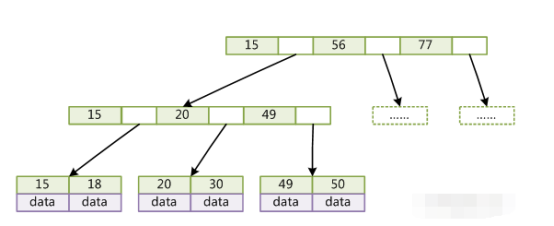
select * from table where id = 15select * from table where id>=18 and id<=49 但是一般数据库的索引都对b+树进行了优化,加了顺序访问的指针,如网上弄的一个图,这样在查找范围的时候,就很方便,比如查找18~49之间的数据: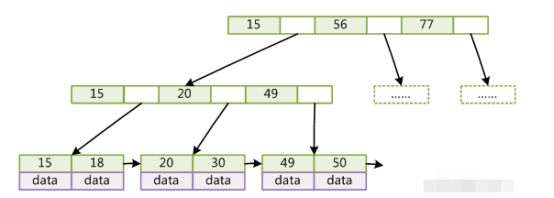
其实到这里,你就差不多了,你自己仔细看看上面两个图,b-树和b+树都现场画一下,然后给说说区别,和通过b+树查找的原理即可。接着来聊点稍微高级点的,因为上面说的只不过都是最基础和通用的b-树和b+树罢了,但是mysql里不同的存储引擎对索引的实现是不同的。先来看看myisam存储引擎的索引实现。就拿上面那个图,咱们来现场手画一下这个myisam存储的索引实现,在myisam存储引擎的索引中,每个叶子节点的data存放的是数据行的物理地址,比如0x07之类的东西,然后我们可以画一个数据表出来,一行一行的,每行对应一个物理地址。
id=15,data:0x07,0a89,数据行的物理地址
select * from table where id = 15 -> 0x07物理地址 -> 15,张三,22myisam最大的特点是数据文件和索引文件是分开的,大家看到了么,先是索引文件里搜索,然后到数据文件里定位一个行的。好了,再来看看innodb存储引擎的索引实现,跟myisam最大的区别在于说,innodb的数据文件本身就是个索引文件,就是主键key,然后叶子节点的data就是那个数据的所在行。我们还是用上面那个索引起来现场手画一下这个索引好了,给大家来感受一下。
innodb存储引擎,要求必须有主键,会根据主键建立一个默认索引,叫做聚簇索引,innodb的数据文件本身同时也是个索引文件,索引存储结构大致如下:15,data:
0x07,完整的一行数据,(15,张三,22)22,data:完整的一行数据,(22,李四,30)就是因为这个原因,innodb表是要求必须有主键的,但是myisam表不要求必须有主键。另外一个是,innodb存储引擎下,如果对某个非主键的字段创建个索引,那么最后那个叶子节点的值就是主键的值,因为可以用主键的值到聚簇索引里根据主键值再次查找到数据,即所谓的回表,例如:select * from table where name = ‘张三’先到name的索引里去找,找到张三对应的叶子节点,叶子节点的data就是那一行的主键,id=15,然后再根据id=15,到数据文件里面的聚簇索引(根据主键组织的索引)根据id=15去定位出来id=15这一行的完整的数据所以这里就明白了一个道理,为啥innodb下不要用UUID生成的超长字符串作为主键?因为这么玩儿会导致所有的索引的data都是那个主键值,最终导致索引会变得过大,浪费很多磁盘空间。还有一个道理,一般innodb表里,建议统一用auto_increment自增值作为主键值,因为这样可以保持聚簇索引直接加记录就可以,如果用那种不是单调递增的主键值,可能会导致b+树分裂后重新组织,会浪费时间。一般来说跳槽时候,索引这块必问,b+树索引的结构,一般是怎么存放的,出个题,针对这个SQL,索引应该怎么来建立select * from table where a=1 and b=2 and c=3,你知道不知道,你要怎么建立索引,才可以确保这个SQL使用索引来查询好了,各位同学,聊到这里,你应该知道具体的myisam和innodb索引的区别了,同时也知道什么是聚簇索引了,现场手画画,应该都ok了。然后我们再来说几个最最基本的使用索引的基本规则。其实最基本的,作为一个java码农,你得知道最左前缀匹配原则,这个东西是跟联合索引(复合索引)相关联的,就是说,你很多时候不是对一个一个的字段分别搞一个一个的索引,而是针对几个索引建立一个联合索引的。给大家举个例子,你如果要对一个商品表按照店铺、商品、创建时间三个维度来查询,那么就可以创建一个联合索引:shop_id、product_id、gmt_create一般来说,你有一个表(product):shop_id、product_id、gmt_create,你的SQL语句要根据这3个字段来查询,所以你一般来说不是就建立3个索引,一般来说会针对平时要查询的几个字段,建立一个联合索引后面在java系统里写的SQL,都必须符合最左前缀匹配原则,确保你所有的sql都可以使用上这个联合索引,通过索引来查询 create index (shop_id,product_id,gmt_create)这个就是说,你的一个sql里,正好where条件里就用了这3个字段,那么就一定可以用到这个联合索引的:
select * from product where shop_id=1 and product_id=1 and gmt_create=’2018-01-01 10:00:00’这个就是说,如果你的sql里,正好就用到了联合索引最左边的一个或者几个列表,那么也可以用上这个索引,在索引里查找的时候就用最左边的几个列就行了:select * from product where shop_id=1 and product_id=1,这个是没问题的,可以用上这个索引的这个是说,如果你的sql里,就用了联合索引的第一个列和第三个列,那么会按照第一个列值在索引里找,找完以后对结果集扫描一遍根据第三个列来过滤,第三个列是不走索引去搜索的,就是有一个额外的过滤的工作,但是还能用到索引,所以也还好,例如:select * from product where shop_id=1 and gmt_create=’2018-01-01 10:00:00’就是先根据shop_id=1在索引里找,找到比如100行记录,然后对这100行记录再次扫描一遍,过滤出来gmt_create=’2018-01-01 10:00:00’的行这个我们在线上系统经常遇到这种情况,就是根据联合索引的前一两个列按索引查,然后后面跟一堆复杂的条件,还有函数啥的,但是只要对索引查找结果过滤就好了,根据线上实践,单表几百万数据量的时候,性能也还不错的,简单SQL也就几ms,复杂SQL也就几百ms。可以接受的。那就不行了,那就在搞笑了,一定不会用索引,所以这个错误千万别犯select * from product where product_id=1,这个肯定不行这个就是说,如果你不是等值的,比如=,>=,<=的操作,而是like操作,那么必须要是like ‘XX%’这种才可以用上索引,比如说select * from product where shop_id=1 and product_id=1 and gmt_create like ‘2018%’如果你是范围查询,比如>=,<=,between操作,你只能是符合最左前缀的规则才可以范围,范围之后的列就不用索引了select * from product where shop_id>=1 and product_id=1如果你对某个列用了函数,比如substring之类的东西,那么那一列不用索引select * from product where shop_id=1 and 函数(product_id) = 2索引是有缺点的,比如常见的就是会增加磁盘消耗,因为要占用磁盘文件,同时高并发的时候频繁插入和修改索引,会导致性能损耗的。
我们给的建议,尽量创建少的索引,比如说一个表一两个索引,两三个索引,十来个,20个索引,高并发场景下还可以。
字段,status,100行,status就2个值,0和1你觉得你建立索引还有意义吗?几乎跟全表扫描都差不多了select * from table where status=1,相当于是把100行里的50行都扫一遍你有个id字段,每个id都不太一样,建立个索引,这个时候其实用索引效果就很好,你比如为了定位到某个id的行,其实通过索引二分查找,可以大大减少要扫描的数据量,性能是非常好的在创建索引的时候,要注意一个选择性的问题,select count(discount(col)) / count(*),就可以看看选择性,就是这个列的唯一值在总行数的占比,如果过低,就代表这个字段的值其实都差不多,或者很多行的这个值都类似的,那创建索引几乎没什么意义,你搜一个值定位到一大坨行,还得重新扫描。就是要一个字段的值几乎都不太一样,此时用索引的效果才是最好的还有一种特殊的索引叫做前缀索引,就是说,某个字段是字符串,很长,如果你要建立索引,最好就对这个字符串的前缀来创建,比如前10个字符这样子,要用前多少位的字符串创建前缀索引,就对不同长度的前缀看看选择性就好了,一般前缀长度越长选择性的值越高。好了,各位同学,索引这块能聊到这个程度,或者掌握到这个程度,其实普通的互联网系统中,80%的活儿都可以干了,因为在互联网系统中,一般就是尽量降低SQL的复杂度,让SQL非常简单就可以了,然后搭配上非常简单的一个主键索引(聚簇索引)+ 少数几个联合索引,就可以覆盖一个表的所有SQL查询需求了。更加复杂的业务逻辑,让java代码里来实现就ok了。大家要明白,SQL达到95%都是单表增删改查,如果你有一些join等逻辑,就放在java代码里来做。SQL越简单,后续迁移分库分表、读写分离的时候,成本越低,几乎都不用怎么改造SQL。我这里给大家说下,互联网公司而言,用MySQL当最牛的在线即时的存储,存数据,简单的取出来;不要用MySQL来计算,不要写join、子查询、函数放MySQL里来计算,高并发场景下;计算放java内存里,通过写java代码来做;可以合理利用mysql的事务支持作者:中华石杉,十余年BAT架构经验倾囊相授。个人微信公众号:石杉的架构笔记(ID:shishan100)









