【经济金融及Python应用讲义】
数据管理——获取数据源
1、导入外部数据
导入数据主要用到Pandas里面的read_x()方法,其中x表示导入文件的格式
1、导入Excel格式数据
#首先生成数据
#stata导出数据
. sysuse auto.dta
(1978 Automobile Data)
. export excel C:\Users\admin\Desktop\auto.xls, firstrow(variables)
file C:\Users\admin\Desktop\auto.xls saved
导入Excel格式数据
#导入数据
import numpy as np
import pandas as pd
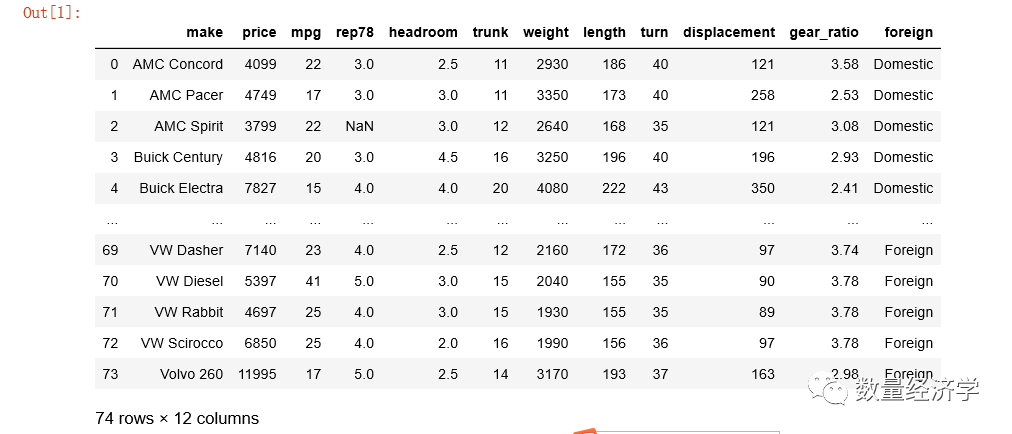
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls' )
df
#等价于
df=pd.read_excel('C:/Users/admin/Desktop/auto.xls' )
或者
df=pd.read_excel('C:\Users\\admin\\Desktop\\auto.xls' )
指定导入哪个sheet
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls',sheet_name="sheet1" )
df
第一个参数是路径,既可以使用绝对路径又可以使用相对路径,如果文件名含有汉字,注意指定设置一下属性encoding = 'utf-8',另设置sheet_name指定具体的Sheet名字,也可传入sheet的顺序,从0开始。
如果没有指定sheetname的名字,导入数据默认为第一个sheet的文件,除了指定sheetname的名字之外,还可以传入sheet的顺序,默认从0开始
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls',sheet_name=0 )
df
指定行索引
行索引使用的是从0开始的默认索引,通过index_col设置
df=
pd.read_excel(r'C:\Users\admin\Desktop\auto.xls',sheet_name=0,index_col=0 )
df
指定列索引
本地文件导入DataFrame时候,默认使用数据表的第一行作为列索引,可以通过header参数来设置列索引,header的参数默认值是0,即用第一行作为列索引,也可以是其他行,只需要传入具体行的数字即可,也可以使用默认的从0开始的数字作为列索引
使用第一行作为列索引
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls',
sheet_name=0,header=0 )
df
第二行作为列索引
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls',sheet_name=0,header=1 )
df
默认从0开始的数字作为列索引
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls',sheet_name=0,header=none )
df
导入指定列
有的时候本地文件的列数太多,而我们不需要那么多列时,我们可以通过设定usecols参数来指定要导入的列
导入第一列
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls',usecols=0 )
df
可以给参数具体的某个值表示要导入第几列,同样是从零开始,也可以以列表的形式传入多个值,表示要传入哪些列
列表形式导入
df=pd.read_excel(r
'C:\Users\admin\Desktop\auto.xls',usecols=[0:5] )
df

2、利用head预览数据
当数据表中的包括数据行数比较多的时候,我们又想查看数据是什么样的数据时,这可以把数据表中前几行数据显示出来进行查看。
在python中,当一个文件导入时,可以用head()方法来控制要显示的那几行,只需要在head()后面的括号中输入要展现的行数即可,默认是展示前5行。
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls' )
#默认展现前5行
df.head()
#展现前3行
df.head(3)

3、shape查看数据表大小
熟悉数据的第一点是看一下数据表的大小及数据表中有多少行,有多少列。
在python中获取数据表的行列是shape方法。shape方法会以元组的形式返回行列数
df=pd
.read_excel(r'C:\Users\admin\Desktop\auto.xls' )
df.shape
注意python中shape方法获取行数和列数不会把行索引和列索引计算在内,而Excel中是把行索引和列索引计算在内的。
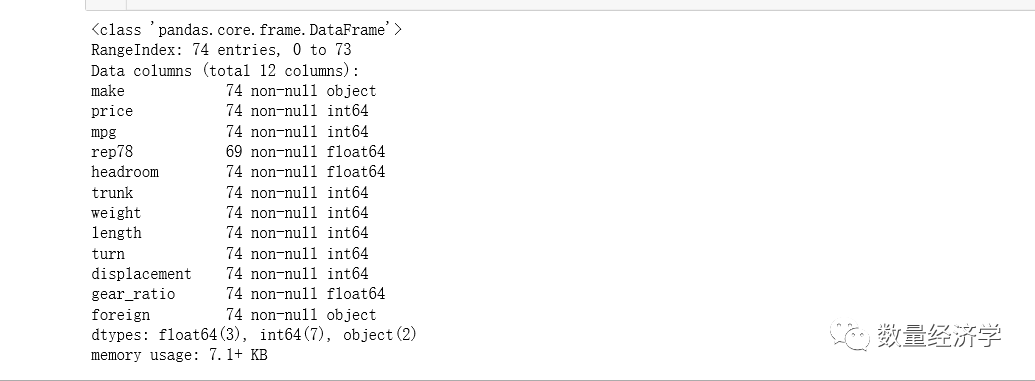
4、info方法获取数据类型
熟悉数据的一个思路就是看一下数据类型,不同的数据类型分析思路,是不一样的,比如数值类型的数据可以求均值,但是字符串数据的类型就没法求均值。
在Excel中,如果想看某一类数据具体是某什么类型,只需要把这一列选中,然后在菜单栏中的数字那一栏就可以看到这一列的数据类型
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls' )
df.info
5、describe方法获取数据描述分析
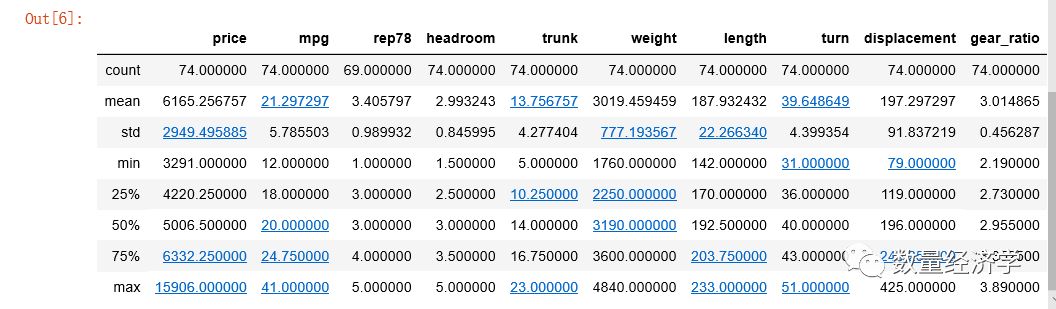
探索性分析获取分布情况及均值是多少?最值是多少,方差等是多少?
在python中只需要使用describe方法就可以获取所有数据的探索性分析
df=pd.read_excel(r'C:\Users\admin\Desktop\auto.xls' )
df.describe