小天导读:如何让机器识别一只猫?本文从人认识猫的基本方法入手,讲解如何训练机器获得模型的主要步骤,并进行简单的实践,分享了机器学习的一个基本原理——梯度下降实现线性回归。
想象一下一个从来没有见过猫的人(比如一个小婴儿),他的词汇里面甚至没有猫这个词。有一天他看到了一个毛茸茸的动物:
这时候他不知道这是什么东西,你告诉他这是 ”猫“。这时候可能小婴儿记住了,这个就是猫。

以上就是我们认识世界的基本方法,模式识别:人们通过大量的经验,得到结论,从而判断它就是猫。在这个过程中我们通过接触样本(各种猫)学习到了猫的特征(人们通过阅读进行学习,观察它会叫、两只耳朵、四条腿、一条尾巴、有胡须,得到结论),从而知道什么是猫。
我们如何知道 npm 包判断一个 npm 包是测试 npm 包呢?SELECT * FROM tianma.module_xxWHERE pt = TO_CHAR(DATEADD(GETDATE(), - 1, ‘dd’), ‘yyyymmdd’) AND name NOT LIKE ‘%test%’ AND name NOT LIKE ‘%demo%’ AND name NOT LIKE ‘%测试%’ AND keywords NOT LIKE ‘%test%’ AND keywords NOT LIKE
‘%测试%’ AND keywords NOT LIKE ‘%demo%’
很明显我们判断的方式是这个模块的名称和关键字中是否包含:test、demo、测试这三个字符。如果有那么我们就认为他是测试模块。我们把规则告诉了数据库,然后数据库就帮我们筛选了非测试模块。识别是否是猫或者识别一个模块是否是测试模块本质上是一样的,都是在找特征:
猫的特征:会叫、两只耳朵、四条腿、一条尾巴、有胡须
测试模块的特征:test、demo、测试
再进一步将特征程序化表述:
猫的特征 叫:true、耳朵:2、腿:4、尾巴:1、胡须:10
测试模块的特征:test:count>0、demo:count >0、测试:count > 0
有了这些特征无论是人还是机器都能正确的识别猫或者测试模块了。简单的理解机器学习就是通过特征和特征的权重来实现数据的分类。(此处为了便于理解,更准确说法请参考:AiLearning/1.机器学习基础.md at master · apachecn/AiLearning · GitHub)原因是当某种分类任务的特征数量巨大之后我们就很难用 if else 的方法去做简单的分类了。比如我们常见的商品推荐算法,要确定某个商品是否适合推荐给某人可能的特征数量会达到上百上千个。数据的准备在整个机器学习的任务中时间占比可能超过 75%,是最重要的一部分,也是最困难的一部分。主要是:采集基本的数据
清理异常值
挑选可能的特征:特征工程
数据打标
如何确定找到的 a、b 值是否合适,那就需要一个评估函数。评估函数描述训练得到的参数和实际的值之前的差距(损失值)。比如下图: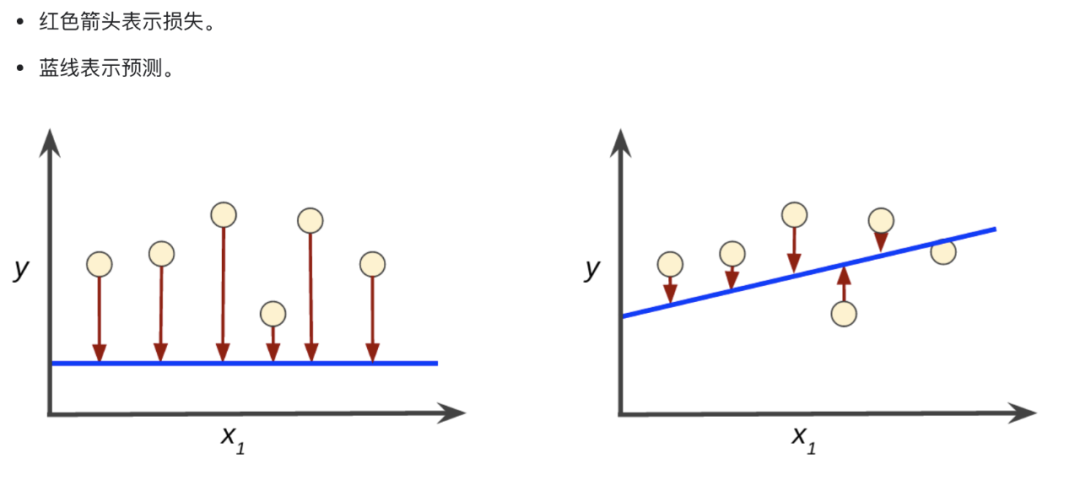
最常见的损失评估函数就是均方误差函数了。通过计算预测的值和真实值的差的平方和来判断预测值的优劣程度。const cost = ((y’1-y1)^2 + (y’2-y2)^2 + (y’3-y3)^2 + (y’4-y4)^2 + (y’5-y5)^2 + (y’6-y6)^2 ) / 6
以上述的线性函数为例,训练算法实际上就是在寻找合适的 a,b 值。如果我们在茫茫的数字海洋中随机寻找 a,b 的值那应该是永远找不到的了。这时候我们就需要用到梯度下降算法来寻找 a,b 值了。再明确一下目标,将上述的损失值计算公式替换为:y=ax+bconst cost = (((a*x1+b)-y1)^2 + ((a*x2+b)-y2)^2 + ((a*x3+b)-y3)^2 + ((a*x4+b)-y4)^2 + ((a*x5+b)-y5)^2 + ((a*x6+b)-y6)^2 )/ 6
目标是找到一组 a、b 的值使得 cost 最小。有了这个目标就好办多了。不知道你还记不记得初中的抛物线函数,也就是一元二次方程:y = ax^2+bx+c而我们上述的 cost 函数虽然看起来很长,但是正好也是一个二次函数。它的图大概是这样的:只要我们找到最低点的 a,b 值就完成我们的目标了。假设我们随机初始化一个 a 值为 1, 这时我们的点就在抛物线的左上方位置,距离最低点(cost 最小)的位置还距离很远呢。看图可知我们只要增加 a 的值就可以靠近最低点了。那看图机器可不会,这时候我们要祭出本篇文章中最复杂的数学知识了:导数。在这个点上的切线斜率值即为这个抛物线的导数,如上图最低点(斜率为 0 处)。通过这个导数可以计算出这个位置的切线(红色的斜线)斜率。如果这个斜线的斜率为负数就意味着 a 太小了,需要增加才能更靠近底部。反之如果斜率为正意味着过了最低点了,需要减少才能更靠近底部。const costDaoA = (((a*x1+b)-y1)*2*x1 + ((a*x2+b)-y2)*2*x1 + ((a*x3+b)-y3)*2*x1 + ((a*x4+b)-y4)*2*x1 + ((a*x5+b)-y5)*2*x1 + ((a*x6+b)-y6)*2*x1 )/ 6
const costDaoB = (((a*x1+b)-y1)*2 + ((a*x2+b)-y2)*2 + ((a*x3+b)-y3)*2 + ((a*x4+b)-y4)*2 + ((a*x5+b)-y5)*2 + ((a*x6+b)-y6)*2 )/ 6
也就是只要将 a,b 值带入 costDaoA 函数就可以得到一个斜率,这个斜率指导参数 a 该如何调整以便更靠近底部。同理 costDaoB 指导参数 b 改如何靠近底部。就这样循环 500 次,基本上就能非常靠近底部了,从而获得合适的 a,b 值。当你获得了 a,b 值之后,那么我们就获得了 y=ax+b 这样一个模型,这个模型就可以帮助我们做预测了。人们早就知晓 ,相比凉爽的天气,蟋蟀在较为炎热的天气里鸣叫更为频繁。我们记录了气温和每分钟叫声的一个表格,并且在 Excel 中绘制了下图(案例来自 google tf 的官方教程):那么我们就认为这些数据的分布是线性的,绘制的这条直线的过程就是线性回归。有了这条曲线我们就能准确的预测任何问题下鸣叫的次数了。https://jshare.com.cn/feeqi/CtGy0a/share?spm=ata.13261165.0.0.6d8c3ebfIOhvAq为了可视化采用了 highcharts 做数据可视化,同时为了省下 75% 的时间直接用了 highcharts 的默认数据点:https://www.highcharts.com.cn/demo/highcharts/scatter当训练完成后绘制了一条蓝色的线叠加在了图上,同时增加了每次训练的 a,b 值的损失率曲线。
function cost(a, b) {
let sum = data.reduce((pre, current) = >{
return pre + ((a + current[0] * b) - current[1]) * ((a + current[0] * b) - current[1]);
}, 0);
return sum / 2 / data.length;
}
function gradientA(a, b) {
let sum = data.reduce((pre, current) = >{
return pre + ((a + current[0] * b) - current[1]) * (a + current[0] * b);
}, 0);
return sum / data.length;
}
function gradientB(a, b) {
let sum = data.reduce((pre, current) = >{
return pre + ((a + current[0] * b) - current[1]);
}, 0);
return sum / data.length;
}
let batch = 200;
let alpha = 0.001;
let args = [0, 0]; function step() {
let costNumber = (cost(args[0], args[1]));
console.log(‘cost’, costNumber);
chartLoss.series[0].addPoint(costNumber, true, false, false);
args[0] -= alpha * gradientA(args[0], args[1]);
args[1] -= alpha * gradientB(args[0], args[1]);
if ((—batch > 0)) {
window.requestAnimationFrame(() = >{ step() });
} else {
drawLine(args[0], args[1]);
}
}
step();
当特征更多的时候,我们需要更多的计算、更长时间的训练来获得训练模型。上述描述都比较简单,但是相信机器学习对你已经不再神秘,那么可以参考更专业的入门文章。参考
[1] GitHub - apachecn/AiLearning: AiLearning: 机器学习 - MachineLearning - ML、深度学习 - DeepLearning - DL、自然语言处理 NLP
[2] https://developers.google.com/machine-learning/crash-course/descending-into-ml/video-lecture?hl=zh-cn
[3] 从 0 开始机器学习 - 手把手用 Python 实现梯度下降法!- 掘金
【往期精彩】
MEDIA AI阿里巴巴文娱算法挑战赛

Spark“数字人体”AI挑战赛——脊柱疾病智能诊断大赛

首届云原生编程挑战赛











