最近几年,做的这些项目,大多与数据分析与算法应用相关。岗位虽然是算法工程师,但是与数据分析打得交道也很多,双管齐下,最后才能确保算法的落地。在几年前,我还想当然地认为做算法的就应该偏重算法研究与应用,可能数据分析相关的技术真的没那么重要,不过我很快意识到自己的错误,重新将数据分析放在一个重要的位置,去研究学习。
结合过往经历,说下自己对算法设计和数据分析工作的一些浅显体会。
对于算法落地而言,个人认为准确性和稳定性是最重要的。在校园时,相信老师都跟我们讲过算法的几个重要性质,比如算法的时间复杂度,空间复杂度,鲁棒性等等,都具备了这些性质的算法当然是一个好算法。
然而,实际情况是,实际场景往往比较复杂,比如,影响因素及之间的关系很复杂;数据匮乏不说,手上的数据还有一半是垃圾等等,这一系列难点,都加大了我们算法设计的难度,哪怕只是设计一个满足基本场景的算法。这使我明白,设计的算法要优先保证能得到一个正确的结果。
其次,作为工程项目,确保系统的稳定性,尽量或者上线后基本没有 bug 显得同样重要。否则,你连觉都睡不好,还提什么其他性能。所以为了稳妥起见,大部分算法设计都不会从零做起,大都会基于成熟稳定的开源框架,然后在上面扩展,开花结果。
已经说的很直白了,还没有工作的小伙伴,可以思考一下。光鲜的事物背后,未必有它真正看起来那样的光彩夺目。
人工智能的强大离不开数据,既然离不开数据,自然就少不了数据处理与分析的相关技术,那么公司就一定需要数据处理与分析的人员。
数据分析为啥如此重要呢?一句话,喂进去的是垃圾,出来的就是垃圾。机器学习、深度学习的算法设计的再牛叉,如果进去的是垃圾数据,深度学习学出来的模型也不会好到哪里去。
所以,数据科学相关的技术,工作中是离不开的,未来只会越来越重要。
说完我的一些体会后,我简单引出一个文章展开的思路。
作为数据分析的入门课程,首先说一下入门数据科学的完整学习路线;然后,介绍数据分析中花费时间较多的:数据清理 (data munging);
学习路线、主要任务介绍完后,接下来就要开始动手实践、实现这些任务了。Python 作为数据分析和人工智能的首选语言,介绍关于它的一些核心知识,让帮助入门者快速上手。
为了工作中加速数据分析的脚步,依次介绍基于 Python 的科学计算库 NumPy, Pandas, 要想快速上手这些库,理解它们的机制是必不可少的,比如 NumPy 的广播机制。数据分析的另一个重要任务就是数据可视化,接下来,介绍基于 Python 生态的可视化库:Matplotlib, 使用 100 行左右的代码,来打包常用的函数用法。
数据分析往往需要做一些回归分析,分类分析等,作为目前火热的机器学习、深度学习,我们通过一个经典的回归算法,深刻明白其原理,知道公式推导,手写实现它。
学习这些理论和工具的同时,你也需要开始实战了。为此,我们选用哈佛大学的数据分析课,它是开源的,并且授课所用数据全部来自实际场景,算是最大贴近你的实际工作日常了,可谓干货十足!
接下来,你可以去寻找数据分析、机器学习相关的工作了。作为全面的学习路线,我还非常用心地为小伙伴们,准备了 2 个数据分析、机器学习相关的真实面试经历。
在开始介绍学习路线之前,我想告诉大家,本篇 chat 展开提纲中,已经包括了数据分析知识的主要部分,因此,大家应该已经有一个大概轮廓了。
每个人学习一门新知识前,大都想去了解下这门知识的学习思路是怎样的,都有哪些知识是必须要学的。所以,我们也只去论述关于数据分析,那些必须要学习的知识,也就是学好数据分析的必备技能。
首先,入门数据分析需要必备一些统计学的基本知识,在这里我们简单列举几个入门级的重要概念。概率,平均值,中位数,众数,四分位数,期望,标准差,方差。在这些基本概念上,又衍生出的很多重要概念,比如协方差,相关系数等。
这一些列常用的统计指标,都在强大的数据分析包 Pandas 中实现了,非常方便,在下面的 Pandas 介绍章节,会详细列出。
我们看下概率的通俗理解。概率 P 是对随机事件发生的可能性的度量。例如,小明在期末考试前,统计了下自己在今年的数学考试成绩,结果显示得到 80 分以下的次数为 2 次,得 80 分~ 90 分的次数为 10 次,得到 90 分以上次数为 3 次,那么:
小明得到 80 分以下的概率为:
P( < 80 ) = 2/(2+10+3) = 13.3%
80~90分的概率为:
P( 80 ~ 90) = 10/(2+10+3) = 66.7%
90分以上的概率:
P( > 90) = 3/(2+10+3) = 20%
期望值 E,在一个离散性随机变量实验中,重复很多次实验,每次实验的结果乘以其出现的概率的总和。如上例中,小明在今年的期末考试,我们对他的期望值大约是多少呢?套用上面的公式,80 分以下的值取一个代表性的分数:70 分,80~90:85 分,90 分以上:95 分,
E = 70 * 0.133 + 85 * 0.667 + 95 * 0.2
计算出的结果为 85,即期末考试我们对小明的合理期望是 85 分左右。
方差 ,用来度量随机变量取值和其期望值之间的偏离程度,公式为:
表示小明的分数这个随机变量 表示样本平均值 表示样本的个数,即在此等于 15 个
已经知道小明的 15 次考试的分数,均值刚才我们也计算出来了为 85 分,带入到上面的公式中,便能得出偏离 85 分的程度大小。
如果方差很大,那么小明在期末考试的分数可能偏离 85 分的可能性就越大;如果方差很小,那么小明很可能期末考试分数在 85 分左右。
当然,你还得了解,事件,离散事件,连续性事件,了解数据的常见分布,比如泊松分布,正态分布等,归一化等知识。限于篇幅,在此,我就不一一展开了。我为大家推荐一本精简的这方面入门书籍,浙大盛骤等老师合编的《概率论与数理统计》这本书,大家可以有选择地学习书中的重要个概念。
如果说数学是纯理论,可能只需要动脑的学问地话,计算机和它最不同的一点就是,需要动手。记得 linux 大神托瓦兹,作为世界上最著名的程序员、计算机科学家,linux 内核和 git 的主要发明人。他就曾经说过,talk is poor, show me the code.
的确,计算机属于工科学问,动手编码的能力非常重要,现在越来越多的理工科博士,也开始注重编码能力了,而且有的编码能力也是超强,写出来的代码可读性、可扩展性都很好。这在过去,博士能做到这个的,大概还不是太多(这是个人观察得出,未经数据考证,结论可能有误 ),或许,当前,博士找工作面临压力也很大,物竞天择,适者生存,民营、私企不会养一个闲人。
数据分析和机器学习领域,同样需要能熟练使用至少一门变成语言,目前此领域,使用较多的就是 Python 和 R 语言。Python 又适合与机器学习领域,所以数据分析相关的从业人员,目前使用 Python 的也较多,当然 R 语言也不少。基于 Python 的生态环境也很不错,有很多数据科学包,比如文中提到的 NumPy、SciPy、Pandas 等等。
入行前,多多动手实践一些项目和名校的开源课程,可以驱动我们掌握它们,毕竟面对一些实际需求,这样做目标明确,自然会驱使你去掌握这些包的更多功能和 API 使用。
总结,这个数据分析的入门路线,主要分为三部分,现在相信小伙伴们已经目标已经很明确了。
下面,看下数据分析的重头戏,数据整理(data munging)。
数据整理,英文名称 data munging,是指在获取到的原数据基础上,理解这些业务数据,整理清洗它们,作为接下来算法建模的输入数据。在文章刚开始,我们就提到过,这部分工作的重要性,绝不亚于算法模型,时间占比可能大于算法选择和设计环节。
我们在拿到需要分析的数据后,千万不要急于立刻开始做回归、分类、聚类分析。
第一步应该是认真理解业务数据,可以试着理解去每个特征,观察每个特征,理解它们对结果的影响程度。
然后,慢慢研究多个特征组合后,它们对结果的影响。借助上个章节提到的,常用的统计学指标,比如四分位,绘制箱形图,可以帮助我们寻找样本的取值分布。
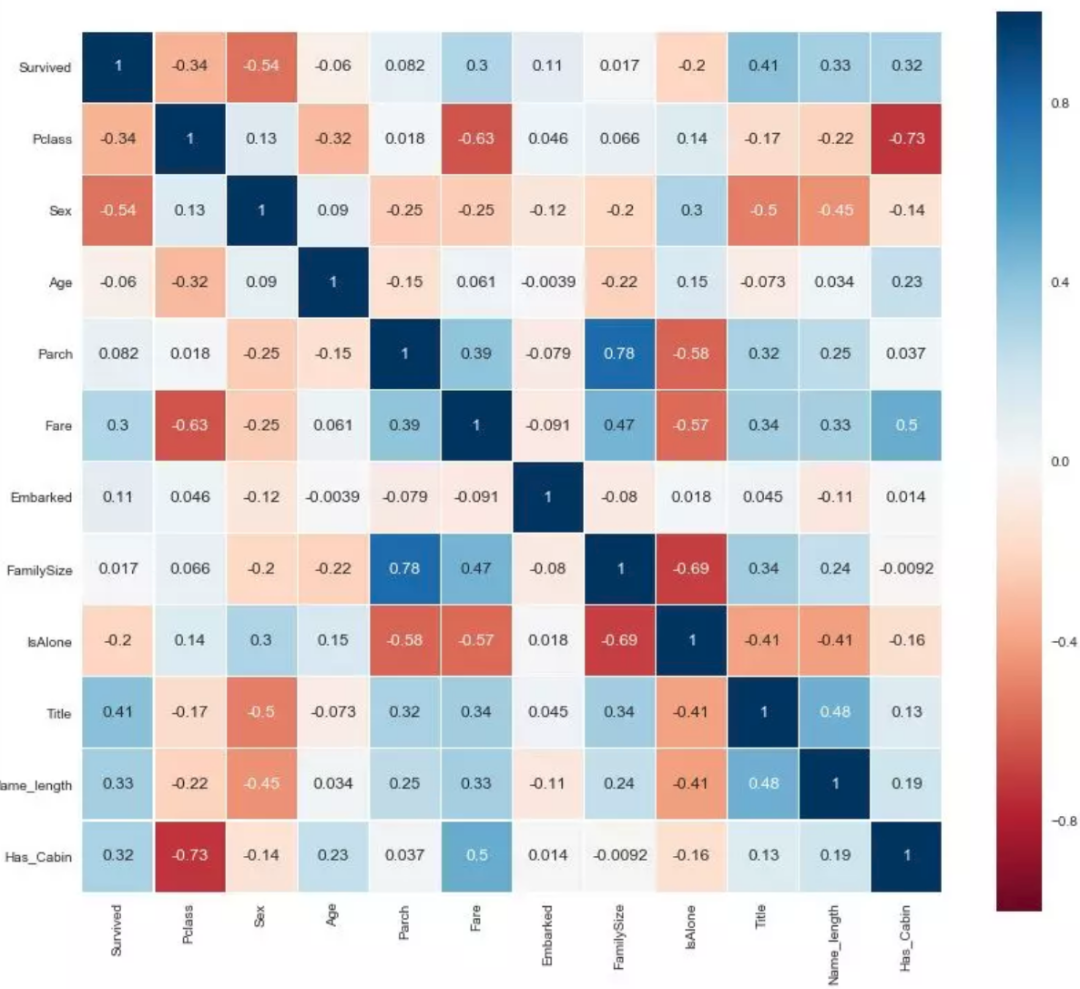
同时,可以借助另一个强大的可视化工具:seaborn ,绘制每个特征变量间的相关系数热图 heatmap,帮助我们更好的理解数据,如下图所示:
colormap = plt.cm.RdBu
plt.figure(figsize=(14,12))
sns.heatmap(train.astype(float).corr(),linewidths=0.1,vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)
 enter image description here
enter image description here









