如下图所示:
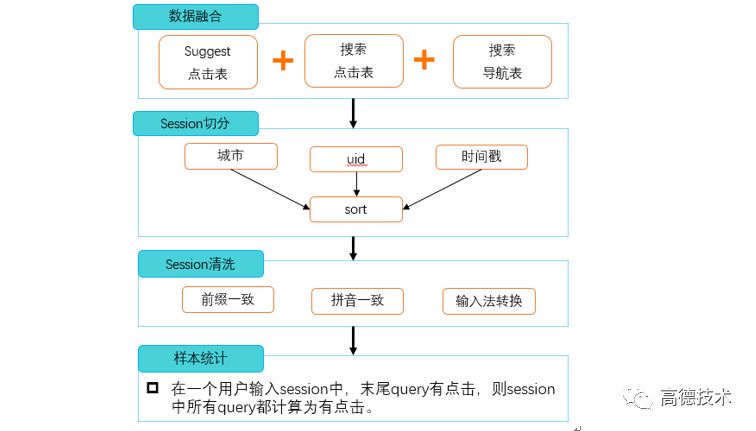
最终,抽取线上点击日志超过百万条的随机query,每条query召回前N条候选POI。利用上述样本构造方案,最终生成千万级别的有效样本作为gbrank的训练样本。
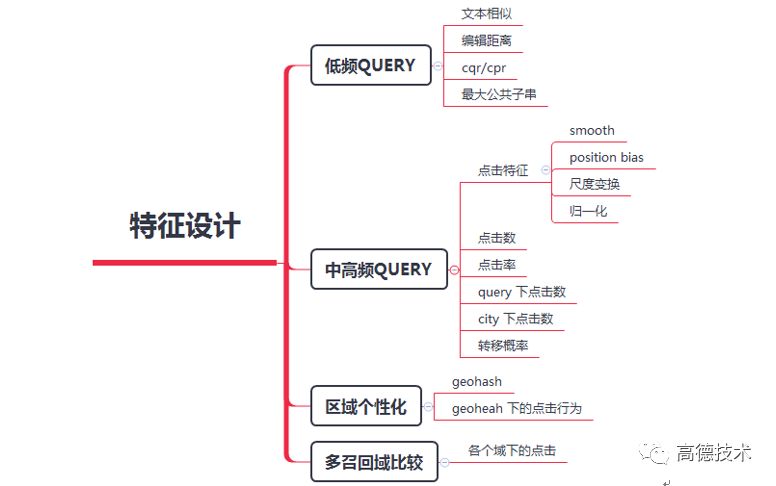
特征方面,主要考虑了4种建模需求,每种需求都有对应的特征设计方案:
有多个召回链路,包括:不同城市、拼音召回。因此,需要一种特征设计,解决不同召回链路间的可比性。
随着用户的不断输入,目标POI不是静态的,而是动态变化的。需要一种特征能够表示不同query下的动态需求。
低频长尾query,无点击等后验特征,需要补充先验特征。
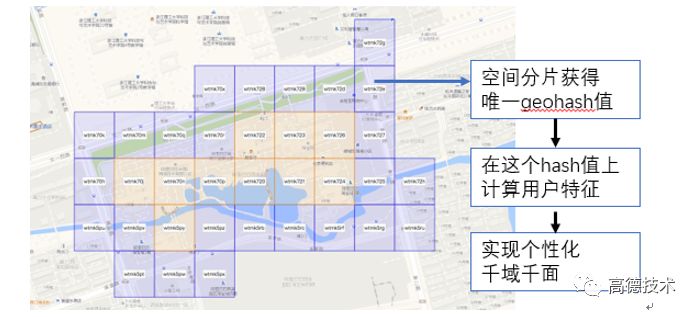
LBS服务,有很强的区域个性化需求。不同区域用户的需求有很大不同。为实现区域个性化,做到千域千面,首先利用geohash算法对地理空间进行分片,每个分片都得到一串唯一的标识符。从而可以在这个标识符(分片)上分别统计特征。
详细的特征设计,如下表所示:
完成特征设计后,为了更好发挥特征的作用,进行必要的特征工程,包括尺度缩放、特征平滑、去position bias、归一化等。这里不做过多解释。
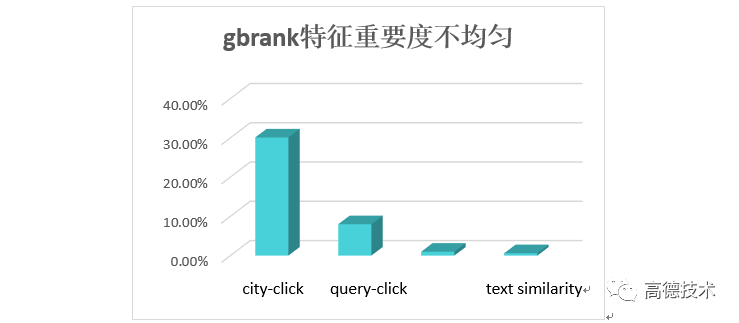
初版模型,下掉所有规则,在测试集上MRR 有5个点左右的提升,但模型学习也存在一些问题,gbrank特征学习的非常不均匀。树节点分裂时只选择了少数特征,其他特征没有发挥作用。
以上就是前面提到的,建模的第二个难题:模型学习的调优问题。具体来就是如何解决gbrank特征选择不均匀的问题。接下来,我们详细解释下。
先看下,模型的特征重要度。如下图所示:
经过分析,造成特征学习不均衡的原因主要有:
综上,由于各种原因,导致树模型学习过程中,特征选择时,不停选择同一个特征(city-click)作为树节点,使得其他特征未起到应有的作用。解决这个问题,方案有两种:
方法一:对稀疏特征的样本、低频query的样本进行过采样,从而增大分裂收益。优点是实现简单,但缺点也很明显:改变了样本的真实分布,并且过采样对所有特征生效,无法灵活的实现调整目标。我们选择了方法二来解决。
方法二:调loss function。按两个样本的特征差值,修改负梯度(残差),从而修改该特征的下一轮分裂收益。例如,对于query-click特征非缺失的样本,学习错误时会产生loss,调loss就是给这个loss增加惩罚项loss_diff。随着loss的增加,下一棵树的分裂收益随之增加,这时query-click特征被选作分裂节点的概率就增加了。
具体的计算公式如下式:
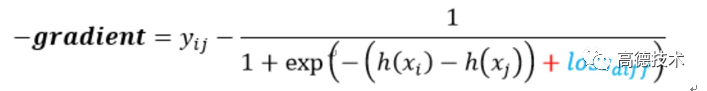
以上公式是交叉熵损失函数的负梯度,loss_diff 相当于对sigmod函数的一个平移。

差值越大,loss_diff越大,惩罚力度越大,相应的下一轮迭代该特征的分裂收益也就越大。
调loss后,重新训练模型,测试集MRR在初版模型的基础又提升了2个点。同时历史排序case的解决比例从40%提升到70%,效果明显。
Learning to Rank技术在高德搜索建议应用后,使系统摆脱了策略耦合、依靠补丁的规则排序方式,取得了明显的效果收益。gbrank模型上线后,效果基本覆盖了各频次query的排序需求。







