二级债基、偏债混基的转债仓位一直并不容易算。几个摆在眼前的障碍:1、解释力度几乎不可避免地随仓位而下降;2、转债与股票持仓有一定共线性,想从净值波动中将股票和转债完全分离有一定难度;3、不同的重仓券有完全不同的效果。但障碍不是完全不可逾越的,我们可以通过一些细节处理,来尽量降低它们的影响。我们在日常测算中考虑的:
1、仓位越低越难以测算的问题,基本只能靠样本来解决,因此我们平时不考虑(转债仓位 + 股票仓位*2)过去4个季度从未超过20%的产品——此外习惯上我们还剔除规模过小或者几乎为单一持有人的产品,这些产品很可能更多地受到基金持有人行为的影响;
2、共线性问题:一要靠数学上的约束,比如股票仓位不高于20%是所有二级债基的限制,我们要靠一个比较大的罚值来实现约束。第二要靠具体的算法,来贴近基金产品的习惯;
3、重仓券问题不仅存在于转债,股票也是一样。所幸的是我们有季报及年报的重仓股数据,因此我们可以不用股票指数或者转债指数来测算,而是利用重仓券计算——这里就有更多细节,比如转债只披露前5大和进入转股期的,见后文详细解释。以及,只用重仓券,也是有一定风险的做法;
4、至于纯债券市场和持仓的影响,经过此前的一些测算,我们发现直接忽略不计是最简单而实用的选择。
下面我们来分解计算方式。先来看一个整体的流程框架,然后逐个击破:
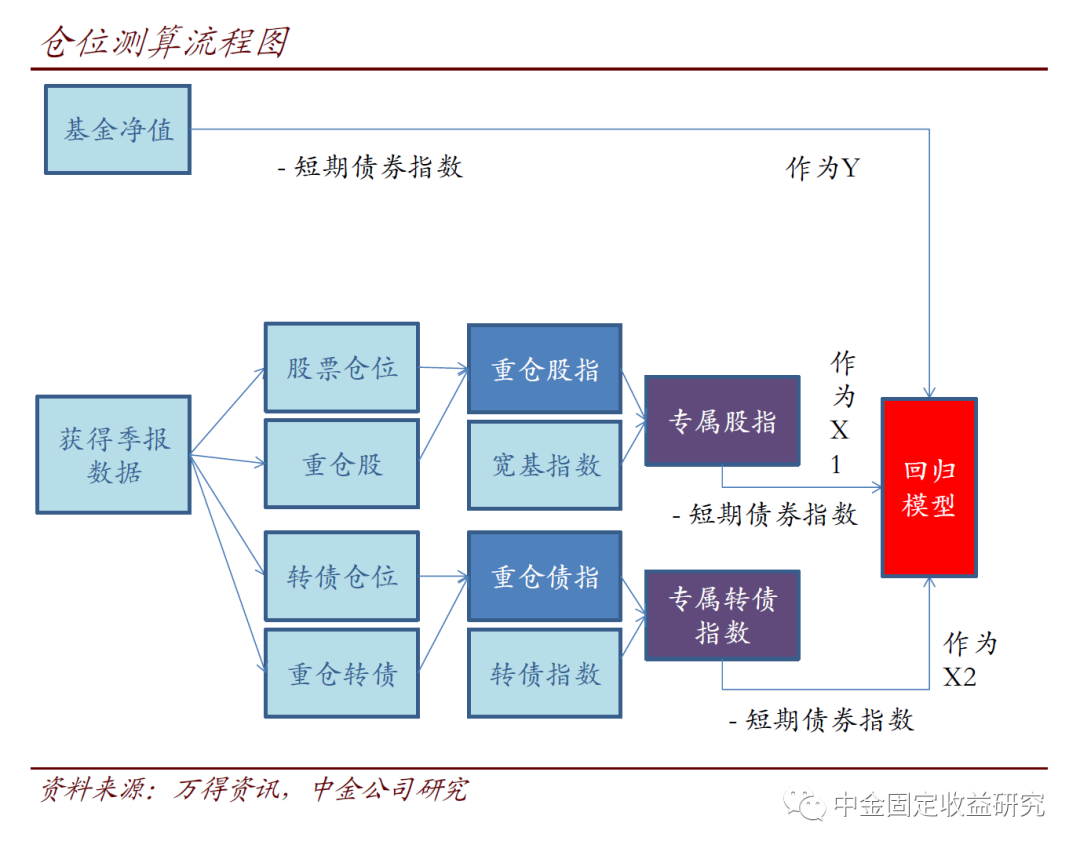
1、最容易处理的是基金净值。只需要注意提取的是复权净值即可,我们用下面的函数来处理。这里没有太多需要注意的细节,不过当前万得的Python接口已经允许用“usedf”关键字来直接输出DataFrame,这里我们考虑兼容,仍采取此前的方式。

2、下面要提取季报基础信息和重仓券。同样,基础季报信息的提取也很容易。值得注意的是,下面我们实际仅用到最后两个参数(股票仓位、转债仓位),其他参数只是作为参考。

不过,重仓券信息提取时,需要注意的内容稍多。
一方面,重仓股的提取有简便方式,而重仓转债需要逐个提取。其次,我们不能直接提取只含转债的重仓债券数据(有的基金可能重仓持有利率债等),需要提取后再判断是否为转债或EB。下面两个函数可以分别得到重仓股(前十)和重仓转债,其索引(index)为重仓券代码,属性“prt”为其占净值比。

3、有了重仓券,就可以计算“重仓券指数”。由于频繁要用到股价涨跌幅,我们单独写了这个函数。其他没有太多值得注意的,不过为照顾“没有重仓券”的情况,我们给了例外的处理方式——直接返回0(这是为了拼接的程序容易判断)。

4、“重仓券指数”并不万能,我们需要一个针对待计算基金的“专属指数”。何谓“专属指数”?——对股票来说,这个指数由两部分拼接,一部分是重仓券指数,权重为这些券的权重之和除以总股票仓位(要用到第一步里面的股票仓位数据)。另一部分则需要用宽基指数来补位。这里有一个细节:宽基指数的选择,我们用与重仓股指数相关系数最高的那一个宽基指数,所以这里需要增加一步,来判断哪个是我们要用的宽基指数(下图第二个函数)。当然,我们还是准备了替补方案:如果没有线索,就用万得全A指数。

专属转债指数要简单得多,按照上述原则,用重仓转债指数和中证转债指数拼接即可。此外,这里另有一个函数getShortBondIndex为提取短债基金指数,在模型中充当“无风险利率”来用。

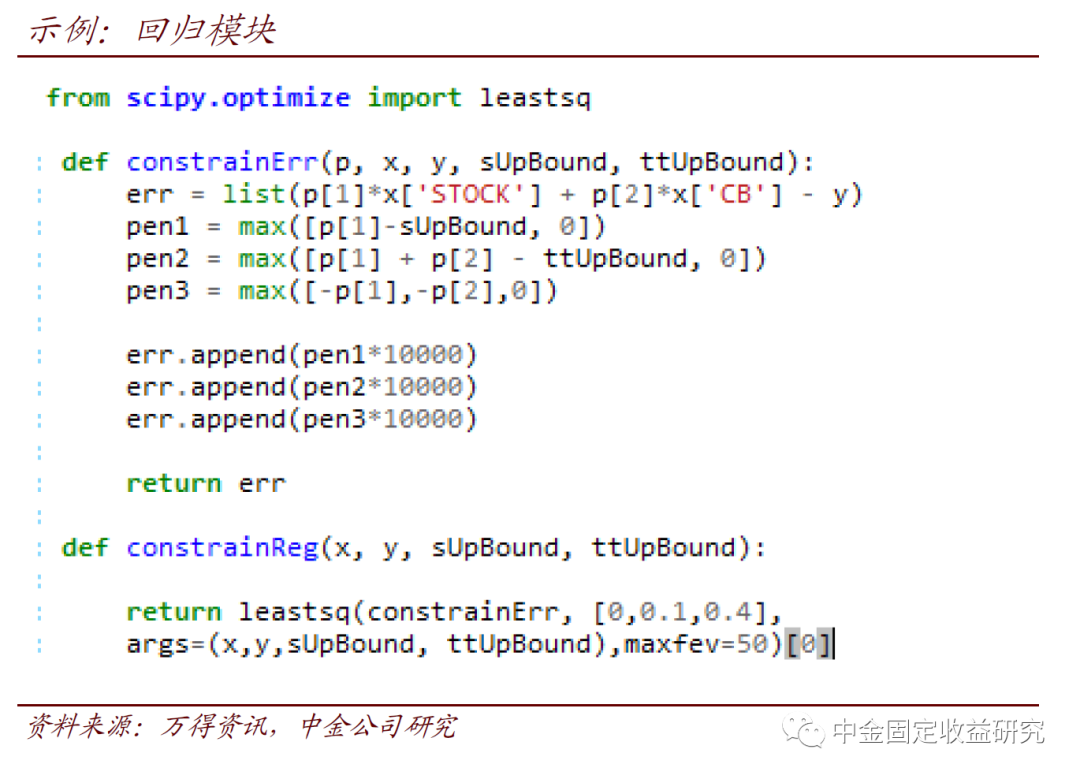
5、在最终执行计算前,先部署一下回归模型。虽然实现上难度很低,这一步是数学上的核心。这里要用到scipy的最小化模块,于是先行引用。constrainErr相当于根据前述边界条件设定最小化目标,constrainReg则负责移动constrainErr中的p使拟合效果最好。另有一些关于迭代、起点设置的细节,容易理解,详见下图。
6、上述准备工作完成,最终的函数myRegression进行拼接即可。值得注意的是,第一、二步中取基金净值、基金季报数据的函数均默认批量提取(一次多个基金),但myRegression为针对单个基金的函数。因此,基金净值、基金季报数据在这里是作为两个参数直接传入函数的(dfFundInfo和dfNavPct)。由于准备工作比较充分,这里的结构反而简单,返回值即是转债仓位与股票仓位的时间序列:










