
德国交通标志识别基准数据集可能是自动驾驶汽车图片分类技术里最受欢迎的数据集。自动驾驶车辆需要对交通标志进行检测和分类,来学习路段的交通规则。也许,这个数据集太小且不完整,还不能实际应用到现实中。但它仍是计算机视觉算法上一个很好的基准数据集。
>>>>数据集
该数据集由两部分组成:训练集和测试集。训练集包含39209张交通标志图片,有停车标志、自行车交叉路口标志和限速30公里/小时标志等43个分类。

德国交通标志识别数据集图像样本
该数据集的数据分布很不均衡。例如,有1800张“限速”(50公里/小时)样本,但只有168张“左转危险”样本。
测试集有12630张图片。2011年国际神经网络联合会议(IJCNN)举办的比赛使用这些图片来评估算法的优劣。
您可以从官方网站下载这个数据集。
>>>>方法
我尝试使用在ImageNet数据集上预先训练的ResNet34卷积神经网络进行迁移学习。
我在fast.ai最新版本的“编程人员的深度学习”课程中学到解决计算机视觉问题的常规方法。去年我在旧金山大学参加了这门课程的离线版本。课程用到fastai,一个建立在PyTorch之上的深度学习库。它提供了易于使用的模块来训练深度学习模型。我大部分时间都在优化超参和增强图像上。
>>>>代码
我在GitHub上发布了我的代码。你可以在那里下载Jupyter文件,它包含从下载数据集到根据未标记的测试集生成提交文件的所有步骤。训练卷积神经网络模型的代码主要来源于 fast.ai的相关课程。
>>>>准备
准备环境。先安装fastai库及其依赖库。
然后下载数据集并解压。将训练集(39209张图片)拆分为训练集和验证集,并将文件移到相应文件夹。这里我用了80%的样本进行训练,20%的样本用于验证。
拆分训练集的时候要注意。该数据集中每个物理交通标志包含30组图片,根据文件名很容易区分。而如果你随机拆分数据集,那么从验证集到训练集会有信息丢失的问题。
我一开始就犯了这个错误。我随机地分割数据集,在训练集上得到了令人激动的准确率,超过了99.6%。使我惊讶的是测试集的准确率只有87%)。测试集和验证集准确度之间的巨大差异意味着验证集设计得很糟糕,或者说验证集过拟合了。
正确的作法是把每组图片都完整地放到训练集或验证集中,确保它不会被一分为二。要了解更多关于创建高质量验证集的知识,请阅读Rachel Thomas的这篇文章。
>>>>探索性分析
探索数据集。检查每类交通标志的分布,查看每类的图片样本。
图片的分辨率不尽相同。观察图片分辨率的直方图,能让你了解卷积神经网络的输入分辨率应该是什么样的。
>>>>训练
加载在ImageNet数据集上预先训练的ResNet34模型。删除最后一层,在顶层添加一层新的softmax层。

通常我的训练方法是:从一个小的输入模型(我从32x32分辨率的图片开始)和一个短的训练过程(共计7个时期(epoch))来优化训练速度。同时你需要快速迭代。理想的情况下,一次试验不应该超过几分钟。
同时,优化批大小(batch size)。在GPU允许的情况下,尽量使批大小最大化。批大小越大,训练时间越短。但在测试时我发现太大的批大小(例如1024或更大)会导致验证集的准确率下降。我猜是模型早就过拟合了。最终我把批大小定为256。
当你找到一组合适的超参之后,就可以使用更大分辨率的图片和更长的时期进行训练了。最终我使用96x96分辨率的图片和19次时期进行训练。
>>>>图像增强
图像增强是一种可以优化模型的技术。你可以添加大量的人工样本到训练集中。这些样本由原始图像做细微的调整得到,例如:旋转角度、调整亮度、放大等等。

(增强图像的样本)
我使用了以下转换组合:旋转20度,亮度调整80%,放大20%。亮度增强很重要。
在项目初期,我发现那些很暗的图片预测率很低。有效的亮度增强能提升3%以上的准确率。亮度可以直接通过调整 RGB三个通道的值来改变。具体实现参考RandomLighting。
其他我尝试过但不建议使用的增强方法:直方图均衡化以提高对比度,随机模糊,填充。
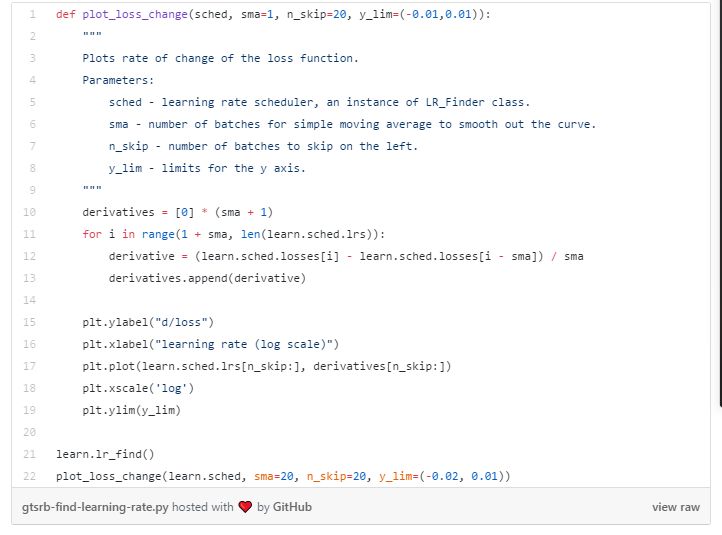
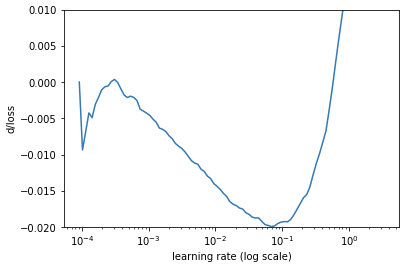
>>>>学习率
使用这里描述的简单算法搜索用于训练的初始学习率。
>>>>微调最后一层
冻结所有层,除了最后一层。 用固定的学习率训练模型一次时期(epoch)。 我将学习率设为0.01。 这样处理的目的是获得最后一层的合理权重。 如果我们不这样做,后续训练未冻结模型时会导致较低层混乱,因为梯度会更大。 这两种方法我都试过,第一种方法的准确率可以高出1%。 我也使用了权重衰减来进行小改进。

模型的微调
解冻所有层并训练三次时期,然后使用随机梯度下降与热重启(stochastic gradient descent with warm restarts)训练若干次时期。


我尝试过差异化微调(discriminative fine-tuning),对模型的不同部分使用不同的学习率。这种情况下,我们希望训练模型的第一层要少于最后一层。第一层比其他层更有意义,在ImageNet数据集上进行训练时,这些层学习到的模式对我们的任务很有帮助,我们也不想丢失这些知识。
另一方面,最后一层是任务特定的,我们希望在任务中重新训练它。不幸的是,它无法提升指标。如果你对所有的层都使用较大的学习率,模型训练的效果会更好。我想这是因为交通路牌与狗、猫和飞机非常不同,因此较低层的信息不像其他计算机视觉应用那样有用。
在验证集上最好的模型的准确率是99.0302%。
>>>>出错分析
除了像混淆矩阵这样的常用工具外,你还可以通过检查几个极端情况来分析错误:最不正确的预测,最正确的预测,最不确定的预测。
要找到每个类的最不正确的预测,你必须在验证集上推理,并找到正确率最低的类别。
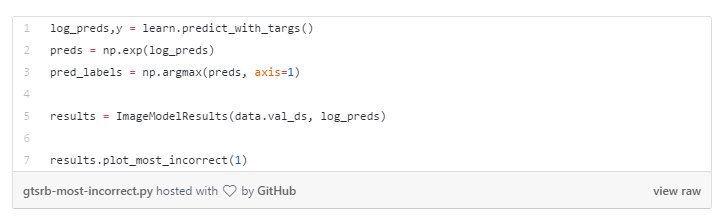

(最不正确预测的图片)
这些图片不是太模糊就是太亮。
同理,你可以找到正确率最高的样本和正确率接近 1/类型数量 的样本(最不确定样本)。
分析的结果可以帮助你调整图像增强的参数,并且可能调整模型的部分超参。
>>>>在全量训练集上训练
之前我们将训练集中80%数据用来训练,20%数据用做验证,从而找到合适的超参。现在我们已不需要验证集了,可以将这20%的图片放到训练集中来提高模型准确率。所以我用同样的参数重新运行所有的步骤,区别是这次我用全部的32909张训练图片做训练。
>>>>在测试集上测试
测试集(12630张图片)用来测试最终模型的性能。之所以在前面没有使用测试集是为了防止过拟合。现在我们可以在测试集上评估模型了。准确率是99.2953%,很好!不过我们还可以提高吗?
>>>>验证时数据增强(TTA)
验证时数据增强(TTA)通常能够提高一定的准确率。诀窍在于根据输入图像创建一些增强版本,分别运行后取平均值。这背后的逻辑是模型可能会错误地区分一些图像,但是如果修改图片可以帮助模型更好地分类。这就像人们如果想要对物体分类,可以通过不同的角度、调整光线、近距离观察等方式,直到他们找到识别物体的最佳视角。

事实上,验证时数据增强帮助我将准确率从99.2953%提高到99.6120%。错误率下降了45%(从0.7047%到0.388%)。
它有多棒?
我们的模型在测试集上的准确率是99.6120%。让我们和一些大佬们比一下:
最先进的是Mrinal Haloi的“基于启动模块(Inception)的卷积神经网络”(Inception-based CNN)99.81%,它的错误率比我好两倍。
IJCNN2001年排行榜:
ÁlvaroArcos-García等作者:3个空间变换器的卷积神经网络(CNN with 3 spatial transformers),准确率是99.71%。
Dan Cireşan等作者:卷积神经网络委员会(Committee of CNNs),准确率是99.46%。
Baris Gecer:基于色斑的COSFIRE过滤器用于物体识别(Color-blob-based COSFIRE filters for object recognition),准确率是98.97%。
如果我参加了那次竞赛,可以拿到第二名。总之这几天的成果不错。
>>>>作者:Pavel Surmenok
现居于美国旧金山,资深机器学习工程师,作为Just Answer公司机器学习团队的经理,擅长将深度学习和自然语言理解的应用到行业和扩展工作中。
>>>>译者:stan、proffl
stan:爱数圈对外交流团队成员,深圳某知名外企在职,天马行空的数据小白,爱八卦,爱户外,更爱和有趣的人一起做有意义的事^.^咦,这说的不就是数据圈么~科科
proffl:爱数圈对外交流团队成员,现就职于农商行,对编程有极大的热情,对技术充满渴望。没有什么兴趣爱好,以前挺爱玩游戏的,现在也不玩了。
欢迎加入终身学习数据分析圈子,一次缴费,永久免费学
加入方式:
1、加我微信:seedata
转账598,先拉微信群,再邀请进小密圈
犹豫的、不懂的、咨询的不要加,加了也是僵尸,时间宝贵,你我都珍惜
2:扫码加入












