使用requests库和BeautifulSoup库
目标网站:妹子图
今天是对于单个图集的爬取,就选择一个进行爬取,我选择的链接为:http://www.mzitu.com/123114
首先网站的分析,该网站有一定的反爬虫策略,所以应对就是加入headers(目前是小白,目前不知道具体为毛这样做)
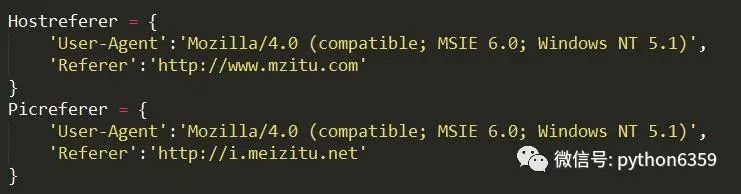
前一个头作为请求网站,后一个头作为破解盗链使用
用requests库的get方法,加上Hostreferer

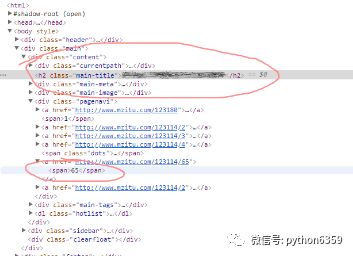
分析网页构成如图所示,图集名称包含在h2标签内,且该标签在整个HTML代码里有唯一的class="main-title"
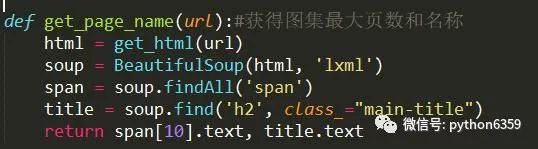
而最大页数只是被span标签包含,无法通过属性来提取。所以提取图集名称采取标签名+属性名一起提取,而最大页数就采取将span标签全部找出,最大页数在span标签中第11位
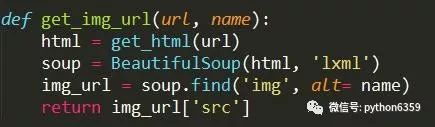
分析页面内容,含有图片链接的img标签中有一个alt属性的值是跟图集名称相同,可以用这个来直接找到这个标签,当然也可以先找到div标签中的class属性是main-inage,再找到img的src属性,这里我就采用第一种方法。

得到图片url链接之后要讲图片存到本地,在请求图片url的时候要加入Picreferer,否则网站会认为你是一个爬虫,会返还给你一个盗链图
该方法传入的参数有3个,第一个是图片url,第二个当前图片的页数,用作创建文件,第三个是图集名称,在存储之前先创建了一个名称是图集名称的文件夹,这样就能将图片存入指定文件夹

在main方法中先请求到图集的名称和最大页数,并且使用名称创建一个文件夹来存储图片。再从1到最大页数做一个for循环,
然后图片的每一页是 图集首页 + / + 当前页数,得到含有图片内容的url链接,后面就可以将得到图片存入本地。
作者:风过杀戮
源自:www.cnblogs.com/forever-snow/p/8506746.html
声明:文章著作权归作者所有,如有侵权,请联系小编删除










