数据分割
在构建预测模型的开始可以使用数据分割构建训练集和测试集,也可以在训练集中用于执行交叉验证或自举(bootstrapping),以评估模型。例:spam数据集
将数据分为训练集和测试集:
library(caret)library(kernlab)data(spam)inTrain p = 0.75, list = FALSE) #75%的数据作为训练集training testing dim(training)[1] 3451 58
k重交叉验证:
set.seed(32323)folds sapply(folds, length) #查看每个子数据集的样本数量Fold01 Fold02 Fold03 Fold04 Fold05 Fold06 Fold07 Fold08 Fold09 Fold10 4140 4142 4141 4140 4141 4141 4142 4141 4141 4140
folds[[1]][1:10] #查看第一个子数据集的前10个元素[1] 1 2 4 5 6 7 8 9 10 11
k=10表示将数据分为10份,list = TRUE表示函数将返回一个列表,returnTrain = TRUE声明返回训练集。
set.seed(32323)folds sapply(folds, length)Fold01 Fold02 Fold03 Fold04 Fold05 Fold06 Fold07 Fold08 Fold09 Fold10 461 459 460 461 460 460 459 460 460 461
folds[[1]][1:10]
[1] 3 19 33 38 44 51 66 67 72 83
返回测试集,样本数量比训练集少。
重抽样:
set.seed(32323)folds sapply(folds, length)Resample01 Resample02 Resample03 Resample04 Resample05 Resample06 Resample07 Resample08 4601 4601 4601 4601 4601 4601 4601 4601 Resample09 Resample10 4601 4601
folds[[1]][1:10][1] 1 1 2 2 3 3 4 5 5 7
自举法进行10次有放回的重抽样,以列表形式返回。
分割时间片段:
set.seed(32323)tme folds names(folds)[1] "train" "test"
folds$train[[1]][1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20folds$test[[1]][1] 21 22 23 24 25 26 27 28 29 30
initialWindow选项设置每个训练集样本中连续值的初始数量,horizon选项设置每个测试集样本中的连续值数量。
训练
例:spam数据集
将数据分为训练集和测试集并拟合模型:
library(caret)library(kernlab)data(spam)inTrain p = 0.75, list = FALSE) training testing modelFit
查看选项:
args(train.default)function(x, y, method = "rf", preProcess = NULL, ..., weights = NULL, metric = ifelse(is.factor(y), "Accuracy", "RMSE"), maximize = ifelse(metric == "RMSE", FALSE, TRUE),
trControl = trainControl(), tuneGrid = NULL, tuneLength = 3)NULL
・method 选项设置算法;
・metric选项设置算法评价 连续变量结果:均方根误差RMSE;R^2^(从回归模型获得) 分类变量结果:准确性;Kappa系数(用于一致性检验,也可以用于衡量分类精度)
args(trainControl)function (method = "boot", number = ifelse(grepl("cv", method), 10, 25), repeats = ifelse(grepl("[d_]cv$", method), 1, NA), p = 0.75, search = "grid", initialWindow = NULL, horizon = 1, fixedWindow = TRUE, skip = 0, verboseIter = FALSE, returnData = TRUE, returnResamp = "final", savePredictions = FALSE, classProbs = FALSE, summaryFunction = defaultSummary, selectionFunction = "best", preProcOptions = list(thresh = 0.95, ICAcomp = 3, k = 5, freqCut = 95/5, uniqueCut = 10, cutoff = 0.9), sampling = NULL, index = NULL, indexOut = NULL, indexFinal = NULL, timingSamps = 0, predictionBounds = rep(FALSE, 2), seeds = NA, adaptive = list(min = 5, alpha = 0.05, method = "gls", complete = TRUE), trim = FALSE, allowParallel = TRUE) NULL
trainControl控制训练方法:
・method选项设置重抽样方法 boot:bootstrapping自举法 boot632:调整的自举法 cv:交叉验证 repeatedcv:重复交叉验证 LOOCV:留一交叉验证
・number选项设置交叉验证或自举重抽样的次数
・repeats选项设置重复交叉验证的重复次数
・seed选项设置随机数种子 可以设置全局随机数种子 可以为每次重抽样设置随机数种子
set.seed(1235)modekFit2 modekFit2Generalized Linear Model
3451 samples 57 predictor 2 classes: 'nonspam', 'spam'
No pre-processingResampling: Bootstrapped (25 reps) Summary of sample sizes: 3451, 3451, 3451, 3451, 3451, 3451, ... Resampling results:
Accuracy Kappa 0.9156324 0.8229977
绘制预测变量
例:ISLR包的Wage数据集
查看数据特征:
library(ISLR)library(ggplot2)library(caret)data(Wage)summary(Wage) year age maritl race Min. :2003 Min. :18.00 1. Never Married: 648 1. White:2480 1st Qu.:2004 1st Qu.:33.75 2. Married :2074 2. Black: 293 Median :2006 Median :42.00 3. Widowed : 19 3. Asian: 190 Mean :2006 Mean :42.41 4. Divorced : 204 4. Other: 37 3rd Qu.:2008 3rd Qu.:51.00 5. Separated : 55 Max. :2009 Max. :80.00 education region 1. < HS Grad :268 2. Middle Atlantic :3000 2. HS Grad :971 1. New England : 0 3. Some College :650 3. East North Central: 0 4. College Grad :685 4. West North Central: 0 5. Advanced Degree:426 5. South Atlantic : 0 6. East South Central: 0 (Other) : 0
jobclass health health_ins 1. Industrial :1544 1. <=Good : 858 1. Yes:2083 2. Information:1456 2. >=Very Good:2142 2. No : 917 logwage wage Min. :3.000 Min. : 20.09 1st Qu.:4.447 1st Qu.: 85.38 Median :4.653 Median :104.92 Mean :4.654 Mean :111.70 3rd Qu.:4.857 3rd Qu.:128.68 Max. :5.763 Max. :318.34可以看到数据全部来自于中大西洋区。
将数据分为训练集和测试集:
inTrain training
testing dim(training)[1] 2102 11dim(testing)[1] 898 11
使用caret包绘制训练集数据:
featurePlot(x = training[, c("age", "education", "jobclass")], y = training$wage, plot = "pairs")
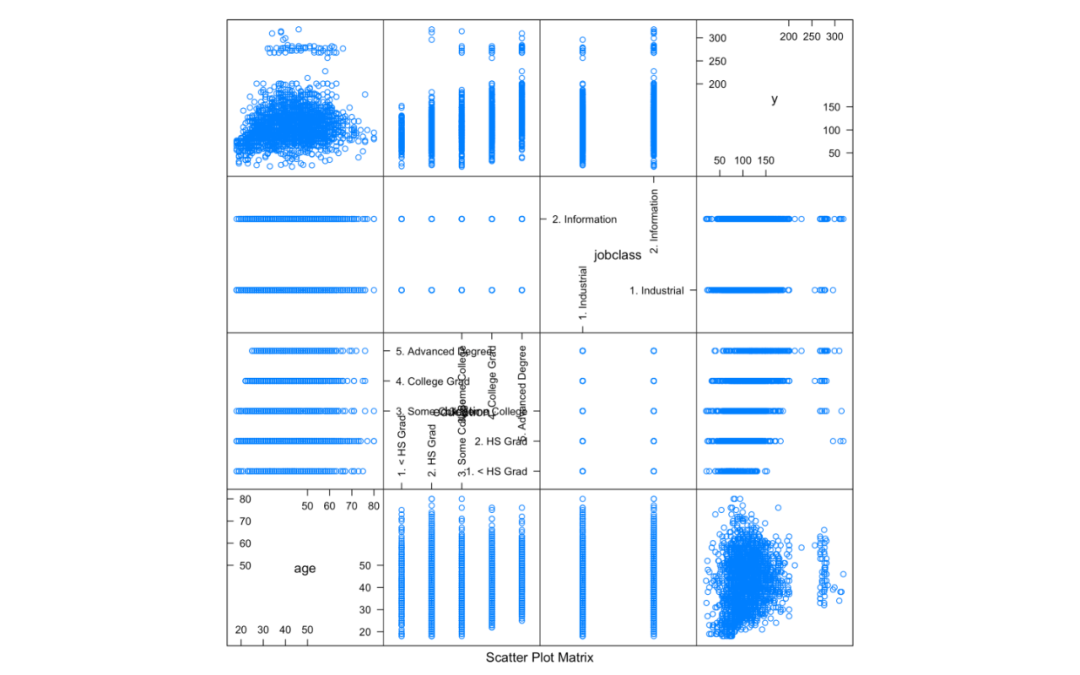
图1.caret包绘制训练集数据 可以看到不同年龄、学历和工作行业与工资的关系的散点图矩阵。
使用ggplot2包绘制数据
qplot(age, wage, data = training)
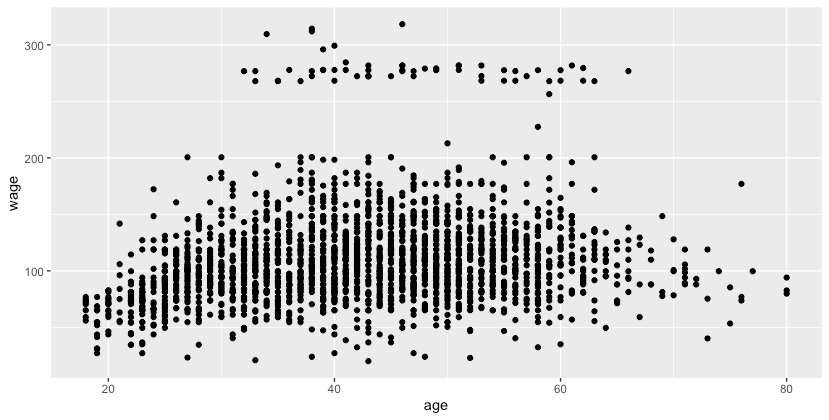
图2.ggplot2包绘制训练集年龄与工资的关系散点图
qplot(age, wage, color = jobclass, data = training)
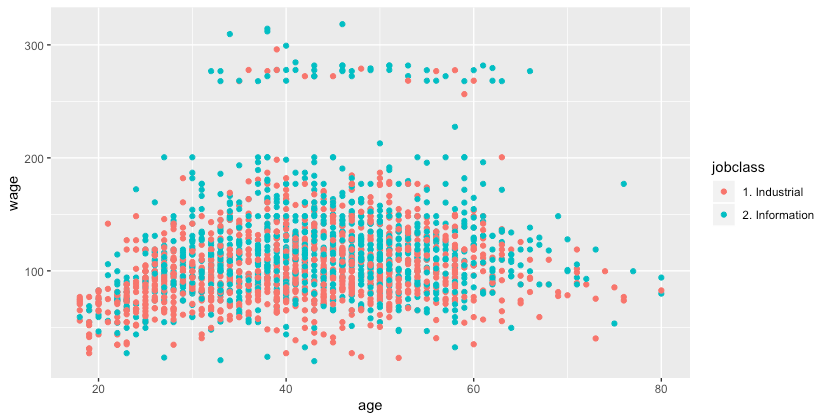
图3.ggplot2包绘制不同年龄、工作行业与工资的关系 可以看到加入不同工作行业变量后更好的解释了数据的分布情况,图中上端工资较高的部分大多数从事的是与信息业相关的工作。
qq qq + geom_smooth(method = 'lm', formula = y ~ x)
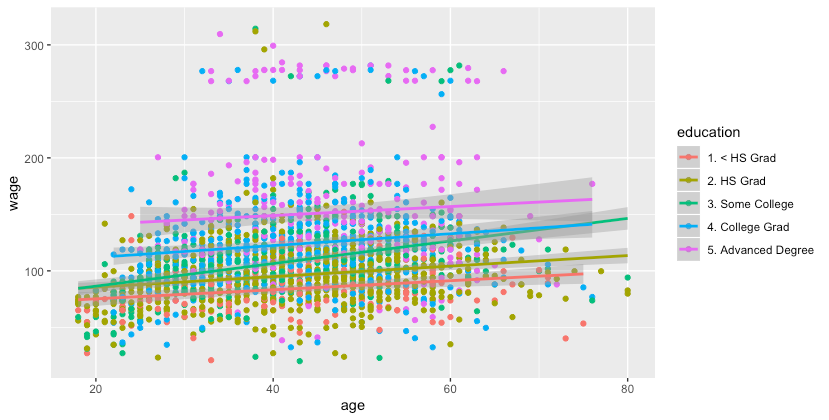
图4.添加线性回归线 按不同的学历绘制年龄与工资的线性回归线。将工资变量分解为不同的类别,有时可以明显观察到不同类别具有不同的关系。
使用Hmisc包分割数据集:
library(Hmisc)cutWage table(cutWage)cutWage[ 20.1, 91.7) [ 91.7,118.9) [118.9,318.3] 702 722 678
将工资变量按分位数分为3个因子水平。
p1 geom = c("boxplot"))p1
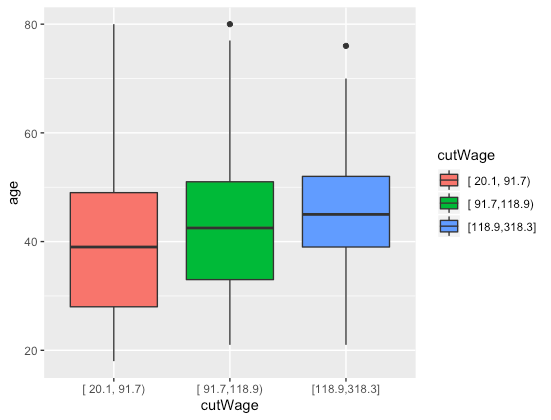
图5.不同工资水平的年龄分布
p2 geom = c("boxplot", "jitter"))library(gridExtra)grid.arrange(p1, p2, ncol = 2)
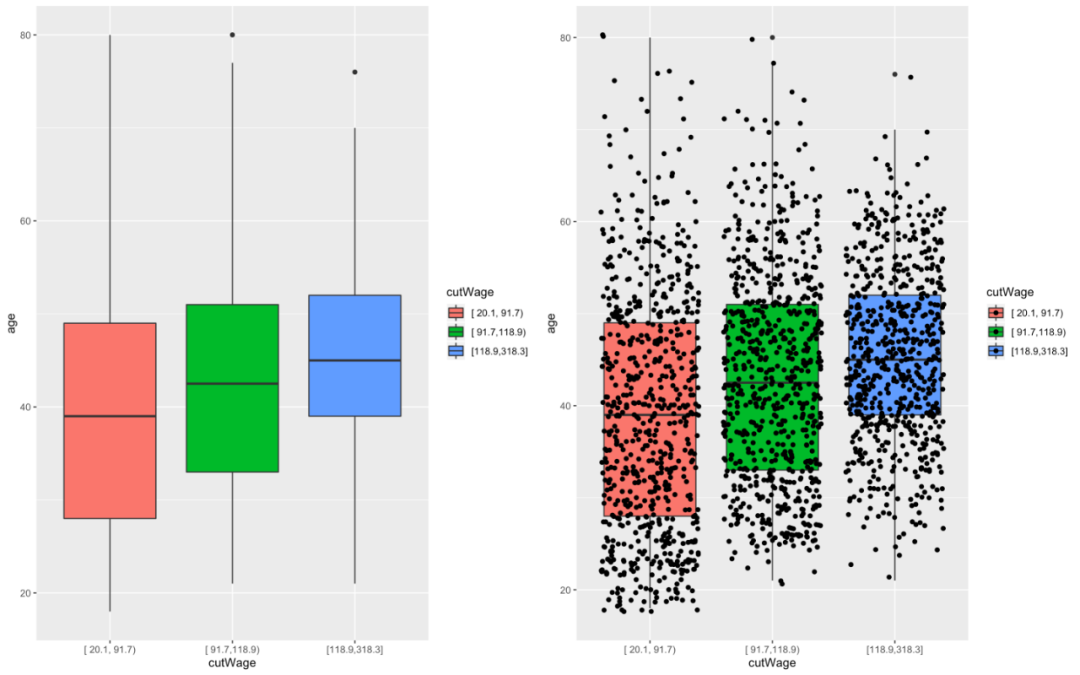
图6.在箱形图上添加原始数据
t1 t1 cutWage 1. Industrial 2. Information [ 20.1, 91.7) 459 243 [ 91.7,118.9) 387 335 [118.9,318.3] 276 402 prop.table(t1, 1) cutWage 1. Industrial 2. Information [ 20.1, 91.7) 0.6538462 0.3461538 [ 91.7,118.9) 0.5360111 0.4639889 [118.9,318.3] 0.4070796 0.5929204
可以将不同因子水平的数据按不同工作行业分类比较,可以得到每组的比例。
qplot(wage, color = education, data = training, geom = "density")
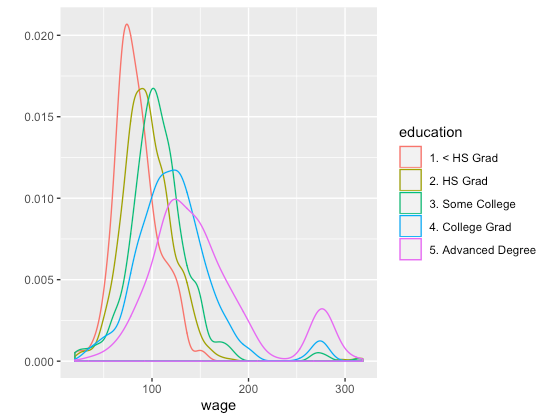
图7.不同学历的工资分布密度图 可以看到低学历的大部分工资水平较低,高学历的大部分工资水平较高,对于大学及以上的学历都有一小部分人能得到很高的工资。
注意:
・只在训练集中绘图,测试集不用于探索模型。
・通过画出被预测变量和特定的预测变量之间的关系图来选择预测变量。
・离群点或异常的组可能暗示缺少某些变量,所有预测变量都无法解释这些异常。
数据预处理
例:spam数据集,一个邮件数据集,共有4601个观测值,58个变量
查看原始数据分布:**
library(caret)library(kernlab)data(spam)inTrain
p = 0.75, list = FALSE) training testing hist(training$capitalAve, main = "", xlab = "ave. capital run length")
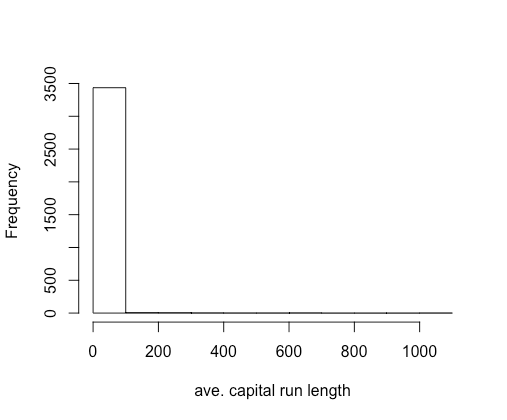
图8.变量capitalAve的分布 可以看到变量值大部分都非常小,仅有少数取值非常大。变量分布非常偏斜,需要对变量进行预处理。
mean(training$capitalAve)[1] 5.207716sd(training$capitalAve)[1] 30.09083
变量的平均值约为5.2,但标准差非常大。对变量进行预处理,使机器学习算法不受变量的偏斜和高度变异性的影响。
标准化数据:
trainCapAve trainCapAveS mean(trainCapAveS)[1] 5.682636e-19sd(trainCapAveS)[1] 1
标准化变量使变量均值为0,标准差为1,降低变异性。
testCapAve testCapAveS mean(testCapAveS)[1] -0.002154109sd(testCapAveS)[1] 1.203646
将预测算法应用于测试集时必须使用在训练集中估计的参数,即必须使用训练集的均值和训练集的标准差来标准化测试集。根据训练集中估计的参数进行了标准化,因此标准偏差不等于1,但是希望它们会接近1。
使用preProcess()函数进行标准化预处理:
preObj trainCapAveS mean(trainCapAveS)[1] 5.682636e-19sd(trainCapAveS)[1] 1
caret包中的preProcess()函数可以对数据进行标准化预处理,除外第58个变量,即关注的结果变量。
testCapAveS mean(testCapAveS)[1] -0.002154109sd(testCapAveS)[1] 1.203646
可以用相同的预处理方法preObj对测试集进行标准化预处理。
拟合模型:
set.seed(32343)modelFit preProcess = c("center", "scale"), method = "glm")modelFitGeneralized Linear Model
3451 samples 57 predictor 2 classes: 'nonspam', 'spam'
Pre-processing: centered (57), scaled (57) Resampling: Bootstrapped (25 reps) Summary of sample sizes: 3451, 3451, 3451, 3451, 3451, 3451, ... Resampling results:
Accuracy Kappa 0.91793 0.8272674
对57个变量进行标准化,可以使预测变量不再具有非常大的偏差或变异性。
使用preProcess()函数进行Box-Cox变换:
preObj trainCapAveS par(mfrow = c(1, 2))hist(trainCapAveS)qqnorm(trainCapAveS)
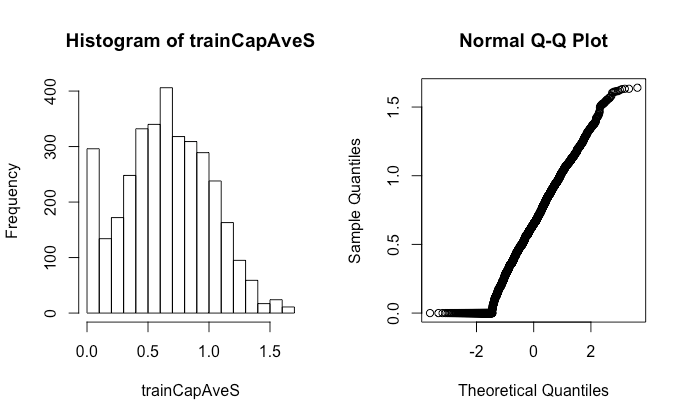
图9.对变量进行Box-Cox变换
对57个变量进行Box-Cox变换,画出训练集中capitalAve变量转换后的分布图以及正态Q-Q图。变换之后的分布较处理之前更像正态分布的钟形曲线,在0值处有大量分布,在正态Q-Q图显示的正态分布理论分位数与样本分位数关系中也可以体现,左下角的数据不在理想的45º斜线上。Box-Cox变换不处理重复值,数据恰好有一堆为0的值。
使用preProcess()函数处理缺失值:
大多数情况下,预测算法无法处理缺失值。
set.seed(13343)
#将原数据中的部分值设置为缺失值training$capAve selectNA training$capAve[selectNA]
#KNN算法填补缺失值install.packages('RANN')
library(RANN)preObj capAve
#标准化原数据capAveTruth capAveTruth
使用K近邻(K Nearest Neighbors, KNN)算法找到缺失值最近的k个相邻的值,通过取这K个值的函数值(一般会选取均值、中位数、众数等)来填补缺失值。
quantile(capAve - capAveTruth) #填补缺失值之后与原数据值差异的分位数 0% 25% 50% 75% 100% -11.840492704 -0.013557568 -0.006870429 0.007224872 6.258135049quantile((capAve - capAveTruth)[selectNA]) #设置为缺失值的数据填补缺失值后与原数据值差异的分位数 0% 25% 50% 75% 100% -11.840492704 -0.019010013 -0.004676972 0.020455761 4.199823372quantile((capAve - capAveTruth)[!selectNA]) #非缺失值的数据与原数据值差异的分位数 0% 25% 50% 75% 100% -0.019010013 -0.013354927 -0.006908130 0.006576893 6.258135049
可以看到处理缺失值后的数据与原数据之间的接近程度,大部分差异值接近为0,填补缺失值可以较好的接近原始数据。仅查看设置为缺失值的数据,一部分值变异性更高;查看非缺失值的数据,变异性更小。
注意:
・训练集和测试集必须以相同方式进行预处理。
・应用于测试集时必须使用在训练集中估计的参数,测试集的转换可能使不完美的。










