除了随机特征的集成外,还有人推测认为,由于神经网络的高度复杂性,每个单独的模型 𝐹𝑖 可能学习到一个函数 𝐹𝑖 (𝑥)=𝑦+ξ𝑖,ξ𝑖 是某种噪声,这种噪声取决于训练过程中使用的随机性。
经典的统计学认为,如果所有的ξ𝑖是大致独立的,那么求取他们的平均值能够大大减少噪音量。
因此,
“集成能够减少方差”真的是集成能提高提高性能的原因吗?
证据表明,在深度学习的背景下,这种减少方差来提升性能的假设是值得怀疑的:
1. 集成并不能无限制地提高测试的准确性。
集成超过100个单个模型通常,与集成10个单个模型基本没有差别。因此,100 ξ𝑖 的平均值与10 ξ𝑖 的平均值相比,方差不再减小,表明 ξ𝑖 可能是不独立的,而且有可能存在偏差,因此均值不为零。在ξ𝑖 不独立的情况下,很难讨论求得这些 ξ𝑖 的平均值能够减少多少偏差。
2. 即使理想情况下,我们认为ξ𝑖 是相互独立的,那么这就表明ξ𝑖 是有偏或异号的。
于是我们可以将 𝐹𝑖 写成:
𝐹𝑖(x)=𝑦+ξ+ξ𝑖
ξ 是一个固定误差,ξ𝑖 则指每个模型的独立误差。于是在集成之后,期望的网络输出将接近 y + ξ,这会有一个固定的偏差 ξ。
在这种情况下,为什么知识蒸馏会有效呢?那么,为什么这个带有偏差 ξ (也被称为隐藏知识)的输出会优于原来的训练呢?
3. 集成学习并不总是能够提高准确性
在图4中,我们可以看到神经网络的集成学习并不总是能够提高测试的准确性,至少在输入类似高斯分布的情况下是这样。
换句话说,在这些网络中,求平均值不会带来任何准确性的增益。
综上来看,我们需要更深入地理解深度学习中的集成,而不只是认为“集成能够减少方差”这么简单。
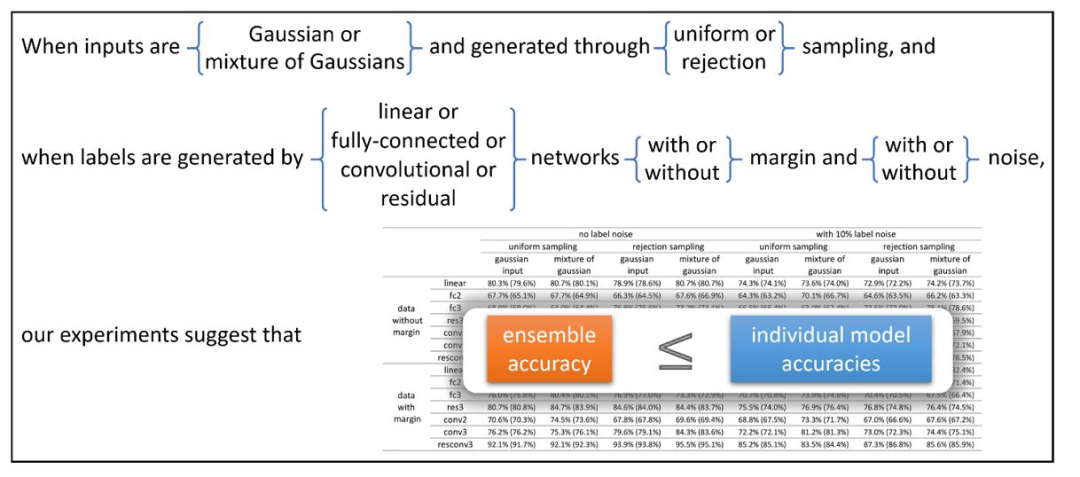
图4: 当输入类似高斯分布时,实验表明集成并不能提高测试的准确性。
图4 表明,在非结构化随机输入的情况下,集成并不凑效。
在我们最新的工作中,我们从数据中找到了集成之所以能够在深度学习中有效的原因所在。
通常,在一个数据集中(以视觉数据集为例),一个对象通常会有多个视角(muti-view)的数据。以「car」为例,一个汽车的数据集中,通常会有从各个角度拍摄的车辆的照片,通常我们仅需要通过车头灯、车轮或车窗等其中的一个特征,便可以对汽车进行分类了;即使在图片中有些特征因为拍摄角度的原因而缺失了,也没有太大的关系。例如从正前方拍摄的汽车,图像中便没有车轮,但这并不妨碍我们识别出「car」。
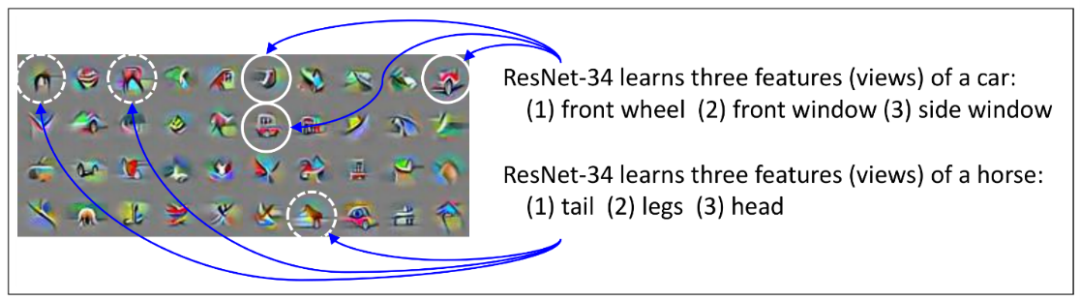
图5: 在CIFAR-10数据集上进行训练的 ResNet-34第23层的一些通道的可视化
这种现象在多数数据中都会存在,其中每类数据都具有多个视角的特征,这种结构被称为“多视图”(multi-view)。
在大多数数据中,几乎所有的视图特征都会显示出来;但在某些数据中,却可能缺少一些视图特征。
更广泛地说,这种“多视图”结构事实上,不仅在原始数据中存在,在中间层抽取的特征集合中也会存在。
在这种“多视图”结构下进行训练,网络会:
1)根据学习过程中的随机性,快速学习这些视图特征的一个子集;
2)会使用这些视图特征,记下剩余那些少量不能正确分类的数据。
第一点意味着,如果将不同网络进行集成,将能够把学习到的视图特征聚合起来,从而达到更高的测试精度。
第二点意味着,单个模型不能学习所有的视图特性,不是因为它们没有足够的容量,而是因为没有足够的训练数据;大多数数据已经被现有的视图特征正确分类,因此在训练阶段,它们基本上不提供梯度。
基于上述视角,我们可以再来分析知识蒸馏是如何工作的。
在现实生活的场景中,一些汽车图像可能看起来“更像一只猫”:例如,一些汽车图像的前灯可能看起来像猫眼。当这种情况发生时,集成模型可以提供有意义的隐藏知识,例如“汽车图像 X 有10% 像一只猫。”
这里是个关键点。在训练单个神经网络模型时,如果没有学习“前灯”视图,剩下的视图或许仍然有可能根据别的视图将图像 x 标记为汽车,但它却无法匹配隐藏知识“图像 X 有10% 像猫”。
而在知识蒸馏的过程中,蒸馏模型会学习每一个可能的视图特征,来匹配集成的性能。需要注意的是,深度学习中知识蒸馏的关键是,作为一个神经网络,单个模型在特征学习中能够学习到集成的所有特征。这与实验中观察到的情况是一致的。(见图6)
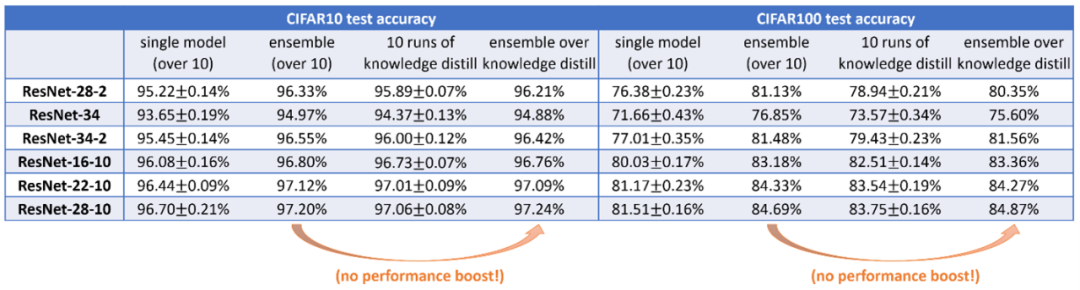 图6: 知识蒸馏已经从集成中学习了大部分视图特性,因此在知识蒸馏之后对模型进行集成学习不会带来更多的性能提升。
图6: 知识蒸馏已经从集成中学习了大部分视图特性,因此在知识蒸馏之后对模型进行集成学习不会带来更多的性能提升。
这个解释也可以用到知识自蒸馏中——训练一个模型来匹配另一个相同的架构的模型(但使用不同的随机种子)的输出,在某种程度上也能提高性能。
简单来理解,自蒸馏是知识蒸馏的一种特殊情况。
我们假设使用模型𝐹2 从一个随机的初始化开始,来匹配另外一个模型𝐹1 的输出。在这个过程中𝐹2 一方面会学习𝐹1 已经学习到特征子集,另一方面其能够学习到的特征子集也会受其随机初始化的影响。
这个过程,可以看做是:首先对两个单独的模型 𝐹1,𝐹2进行集成学习,然后蒸馏成 𝐹2。
最终的 𝐹2 可能不一定涵盖数据集中所有可学习的视图,但它至少有学习所有视图(通过两个单个模型的集成学习数据库来覆盖)的潜力。这就是自蒸馏模型测试时性能提升的来源!
参考:
https://www.microsoft.com/en-us/research/blog/three-mysteries-in-deep-learning-ensemble-knowledge-distillation-and-self-distillation/









