 来源 | AI前线
来源 | AI前线
作者 | Ben Dickson
译者 | Sambodhi
策划 | 刘燕
随着机器学习的迅速普及,科技界必须制定一份保证人工智能系统免遭对抗攻击的路线图。否则,对抗机器学习将会是一场灾难。如果你一直在关注有关人工智能的新闻,你可能已经听说过或看到过经修改的熊猫、海龟和停车标志的图像,这些图像在人们眼中看似平凡,但却能引起人工智能系统的异常行为。
这些被称为 “对抗样本”或“对抗攻击”图像及其 音频 和文本 对应物,在机器学习领域引起了越来越多的兴趣和关注。
然而,尽管针对 对抗机器学习 的研究不断增加,但数据表明,在解决现实世界应用中的对抗攻击方面进展甚微。
随着机器学习的迅速普及,科技界必须制定一份保证人工智能系统免遭对抗攻击的路线图。否则的话,对抗机器学习将会是一场灾难。
 人工智能研究人员发现,通过在停车标志上贴上黑白小贴纸,就能使它们对计算机视觉算法不可见(来源:arxiv.org)。
人工智能研究人员发现,通过在停车标志上贴上黑白小贴纸,就能使它们对计算机视觉算法不可见(来源:arxiv.org)。
每种软件都有其独特的安全漏洞,并随着软件发展的新趋势而产生新的威胁。比如, SQL 注入攻击开始流行,因为带数据库后台的 Web 应用开始取代静态网站。由于大量采用浏览器端脚本语言,导致了跨站脚本攻击。
缓冲区溢出攻击利用 C 等编程语言处理内存分配的方式,覆盖关键变量,在目标计算机上执行恶意代码。反序列化攻击利用了诸如 Java 和 Python 等编程语言在应用程序和进程之间传输信息的方式的缺陷。
近来,我们看到了利用 JavaScript 语言的特殊特性,导致 NodeJS 服务器不稳定行为的 原型污染攻击 的爆发。
对抗攻击在这方面与其他网络威胁并无不同。随着机器学习成为 许多应用的重要组成部分,黑客们正在寻找植入人工智能模型并触发恶意行为的方法。
但是,区别于对抗攻击的是其性质和可能的应对措施。对于大部分安全漏洞而言,这一界限是非常清晰的。一旦发现 Bug,安全分析人员就可以准确地记录它发生的条件,并找到导致漏洞的源代码部分。
应对措施也是直截了当的。例如,SQL 注入漏洞是未对用户输入进行净化的结果。如果不对源复制到目标的字节数设置截止,那么复制字符串数组时就会出现缓冲区溢出错误。
对抗攻击通常利用机器学习模型学习参数的特殊性。攻击者通过对目标模型的输入进行细致的改变来探测目标模型,直到它产生所需的行为为止。
例如,通过对图像的像素值进行逐步改变,攻击者可以使 卷积神经网络 将其预测由“海龟”改为“步枪”。这样的对抗干扰通常是人眼无法察觉的一层噪声。
(注意:在某些情况下,例如 数据中毒,对抗攻击是通过机器学习管道的其他组件中的漏洞而成为可能的,例如通过被篡改的训练数据集来实现。)
 神经网络认为是步枪的照片。人类视觉系统决不会犯这样的错误。(来源:LabSix)
神经网络认为是步枪的照片。人类视觉系统决不会犯这样的错误。(来源:LabSix)
机器学习的统计特性使得很难发现和修补对抗攻击。在某些条件下有效的对抗攻击可能会在其他条件下失效,例如角度或光线条件的改变。另外,你也无法指出是哪一行代码造成了漏洞,因为它分布在构成模型的成千上万个参数中。
举例来说,一种流行的方法是对抗训练,研究人员研究一个模型以产生对抗样本,然后根据这些样本及其正确的标签重新训练模型。
对抗训练会重新调整模型的所有参数,使其对训练过的样本类型具有健壮性。但是如果足够严格的话,攻击者可以找到其他噪声模式来创建对抗样本。
显而易见的事实是,我们仍然在学习如何应对对抗机器学习的问题。安全研究人员习惯于浏览代码来寻找漏洞。现在,他们必须学会在由数百万个数字参数组成的机器学习中找到安全漏洞。
近年来,有关对抗攻击的论文数量激增。为了跟踪这一趋势,我在 arXiv 预印本服务器上搜索了一些论文,其摘要部分提到“对抗攻击”或“对抗样本”。2014 年,有关对抗机器学习的论文数量为零。到 2020 年,大约有 1100 篇关于对抗样本和对抗攻击的论文被提交到 arXiv。从 2014 年到 2020 年,arXiv.org 有关对抗机器学习的论文从一年零篇猛增到一年 1100 篇。对抗攻击和防御方法也成为 NeurIPS 和 ICLR 等著名人工智能会议的重要亮点。甚至连 DEF CON、Black Hat 和 Usenix 等网络安全会议,也已经开始举办关于对抗攻击的研讨会和演讲。在这些会议上发表的研究表明,在检测对抗漏洞和开发防御方法方面已经取得了巨大的进展,这些方法可以使机器学习模型更加健壮。例如,研究人员已经找到了利用 随机切换机制 和 神经科学的见解 来保护机器学习模型免受对抗攻击的新方法。但值得注意的是,人工智能和安全会议侧重于前沿研究。而且在人工智能会议上提出的工作和组织每天所做的实际工作之间还有相当大的差距。令人担忧的是,尽管人们对对抗攻击威胁的兴趣越来越大,警告也越来越响亮,但在现实世界应用中,追踪对抗漏洞的活动很少。
我参考了几个跟踪 Bug、漏洞和 Bug 赏金的来源。举例来说,在 NIST 国家漏洞数据库(NIST National Vulnerability Database)中的 145000 多条记录中,没有关于对抗攻击或对抗样本的条目。搜索“机器学习”会返回五个结果。
其中大多数是包含机器学习组件的系统中的跨站脚本(XSS)和 XML 外部实体(XXE)漏洞。有一个漏洞允许攻击者创建机器学习模型的模仿抄袭的版本并获得洞察力,这可能是对抗攻击的窗口。但目前还没有关于对抗漏洞的直接报告。
搜索“深度学习”显示,2017 年 11 月提交了一个 关键缺陷。但这并非对抗漏洞,而是深度学习系统中另一个组件的缺陷。
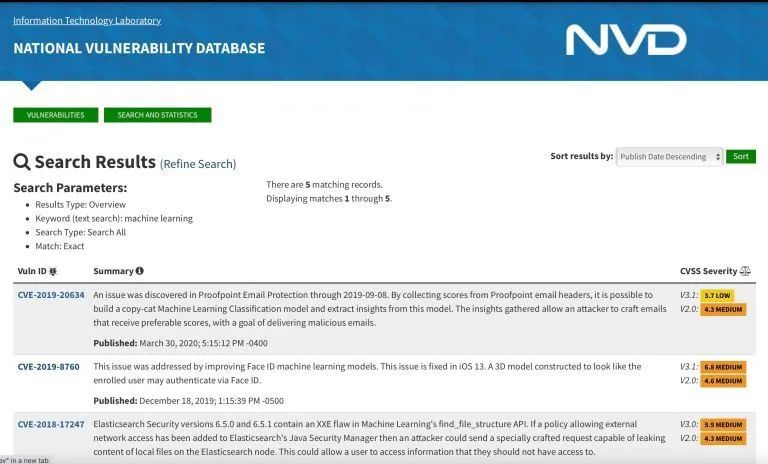
国家漏洞数据库中关于对抗攻击的信息很少。
我还查看了 GitHub 的 Advisory 数据库,该数据库跟踪 GitHub 上托管的项目的安全性和 Bug 修复情况。搜索“对抗攻击”、“对抗样本”、“机器学习”和“深度学习”都没有结果。
搜索“TensorFlow”可以得到 41 条记录,但大多数都是 TensorFlow 代码库的 Bug 报告。而 TensorFlow 模型的参数中并没有任何关于对抗攻击或隐藏漏洞的内容。
由于 GitHub 已经托管了许多深度学习模型和预训练的神经网络,这一点很值得注意。
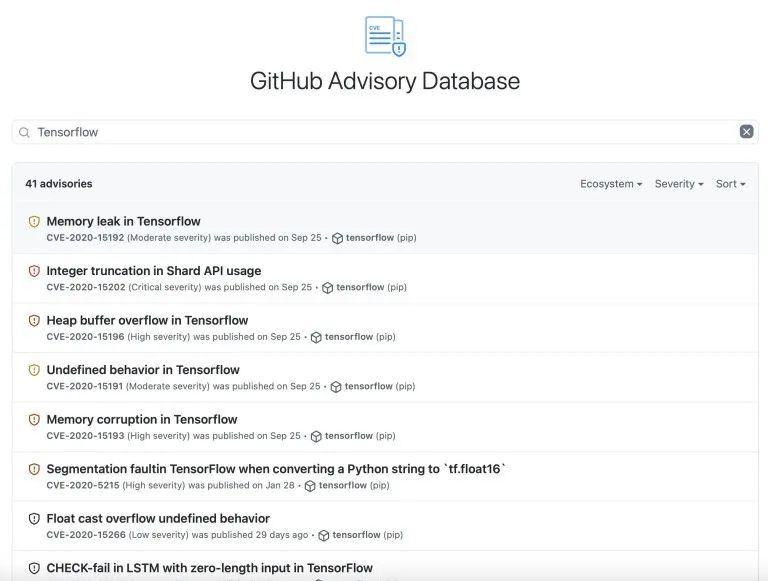
GitHub Advisory 没有对抗攻击的记录。
最后,我查看了 HackerOne,这是许多公司用来运行 bug 赏金计划的平台。该平台也没有任何报告提及对抗攻击。
虽然这可能不是一个非常准确的评估,但这些消息来源中没有一个提供任何有关对抗攻击的内容,这一事实很能说明问题。
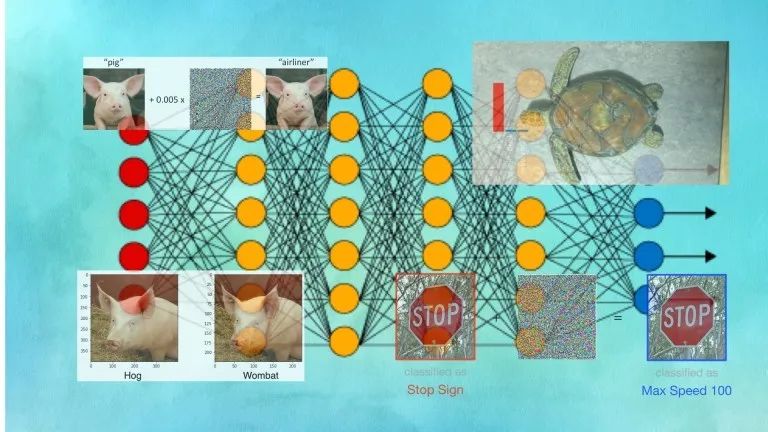
对抗漏洞深深地嵌入了机器学习模型的众多参数中,这使得传统的安全工具很难检测到这些漏洞。
自动防御是另一个值得讨论的领域。当涉及到基于代码的漏洞时,开发人员有大量的防御工具可以使用。
静态分析工具可以帮助开发人员发现代码中的漏洞。在运行时,动态测试工具可以检查应用程序的易受攻击的行为模式。编译器用了很多这样的技术来跟踪和修补漏洞。现在,即使你的浏览器都有工具来查找并阻止客户端脚本中可能的恶意代码。
同时,各组织已经学会将这些工具与正确的政策结合起来,以强制执行安全的编码实践。许多公司已经采取了程序和实践,在将应用公开发布前,对其已知和潜在的漏洞进行严格的测试。例如,GitHub、Google 和 Apple 都利用这些工具以及其他工具来审查上传到其平台上的数以百万计的应用程序和项目。
但是针对机器学习系统的防御对抗攻击的工具和程序仍处于初级阶段。正因为如此,我们很少看到有关对抗攻击的报告和建议。
与此同时,另一个令人担忧的趋势是,各个层次的开发人员越来越多地使用深度学习模型。十年前,只有那些对机器学习和深度学习算法有充分了解的人才能在应用中使用它们。你必须知道如何建立一个神经网络,通过直觉和实验来调整超参数,并且还需要获得能够训练模型的计算资源。
但如今,将一个预训练神经网络整合到应用中是非常容易的。
例如,PyTorch 是领先的 Python 深度学习平台之一,它 有一个工具,可以让机器学习工程师在 GitHub 上发布预训练神经网络,并允许开发者访问它们。如果你想将图像分类器深度学习模型集成到你的应用中,你只需要对深度学习和 PyTorch 有一个基本的了解。
由于 GitHub 不具备有检测和阻止对抗性漏洞的程序,恶意行为者可以很容易地使用这类工具来发布带有后门的深度学习模型,并在数千名开发者将其集成到应用中之后加以利用。

考虑到对抗攻击的统计特性,可以理解的是,很难用对付基于代码的漏洞的同样方法来解决它们。不过幸运的是,已经有了一些积极的进展,可以为未来指明方向。
上个月,由微软、IBM、英伟达、MITRE 以及其他安全和人工智能公司的研究人员发布的 Adversarial ML Threat Matrix,为安全研究人员提供了一个框架,用于寻找包含机器学习组件的软件生态系统中存在的薄弱点和潜在的对抗漏洞。Adversarial ML Threat Matrix 遵循 ATT&CK 框架,这是安全研究人员中已知且可信的格式。
另一个有用的项目是 IBM 的 Adversarial Robustness Toolbox,这是一个开源的 Python 库,它提供了评估机器学习模型的对抗性漏洞的工具,并帮助开发人员加强他们的人工智能系统。
这些以及未来将开发的其他对抗防御工具需要得到适当的政策支持,以确保机器学习模型的安全性。像 GitHub 和 Google Play 这样的软件平台必须建立程序,并将其中的一些工具整合到包含机器学习模型的应用程序的审核过程中。针对对抗漏洞的 Bug 赏金也是一个很好的措施,可以确保数百万用户使用的机器学习系统的健壮性。
可能还需要为机器学习系统的安全制定新的规则。就像处理敏感操作和信息的软件需要满足一系列标准一样,在生物鉴别认证和医学成像等关键应用中使用的机器学习算法也必须经过审核,以确保它们能可靠地防御对抗攻击。
随着机器学习的应用范围不断扩大,对抗攻击的威胁越来越迫在眉睫。对抗漏洞是一颗定时炸弹。只有系统化的应对措施才能化解它。
作者介绍:
Ben Dickson,软件工程师,也是 TechTalks 的创始人。撰写关于技术、商业和政治方面的文章。
原文链接:
https://bdtechtalks.com/2020/12/16/machine-learning-adversarial-attacks-against-machine-learning-time-bomb/
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”











