近年来,以机器学习、深度学习为核心的AI技术得到迅猛发展,深度神经网络在各行各业得到广泛应用:
1. CV(计算机视觉):目标检测,场景识别,图像分割等。
2. 智慧语音:语音识别,声纹识别等。
3. NLP(自然语言处理):自动搜索引擎,对话服务机器人,文本分类,智能翻译等。
4. 科学研究:应用于物理、生物、医学等多研究领域。高能粒子对撞分类,宇宙天体图数据分析,星系形状建模,生物结构的蛋白质折叠预测,精准医疗与疾病预测。

这些应用催生更多的新模型出现:CNN, RNN, LSTM, GAN, GNN,也催生着如Tensorflow, Pytorch, Mxnet, Caffe等深度学习框架出现。目前训练框架开始收敛,逐步形成了PyTorch引领学术界,TensorFlow主导工业界的一个双雄局面。
但是,深度学习算法要实现落地应用,必须被部署到硬件上,例如Google的TPU、华为麒麟NPU,以及其他在FPGA上的架构创新。

这些各训练框架训练出来的模型要如何部署到不同的终端硬件呢,这就需要深度学习神经网络编译器来解决。
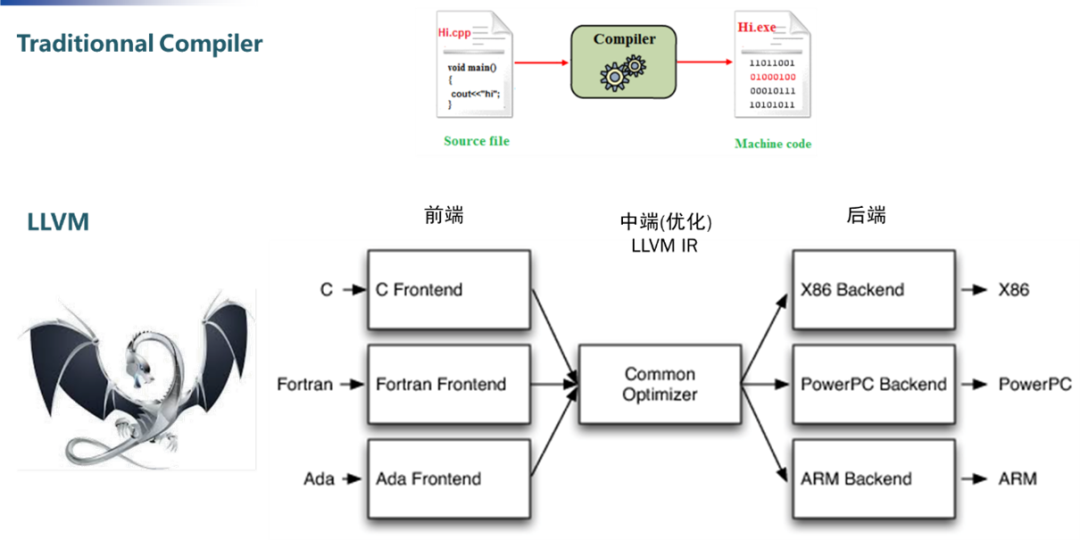
在神经网络编译器出现之前,我们使用的是传统编译器。
传统编译器和神经网络编译器
传统编译器
以LLVM(low level virtual machine)为例,其输入是高级编程语言源码,输出是机器码,由一系列模块化的编译器组件和工具链组成。
LLVM通过模块分为前端,中端(优化)和后端三部分。每当出现新的编程语言,只需要开发相应的前端,将编程语言转换成LLVM的中间表示;类似地,出现新的硬件架构,只需要开发相应的后端,对接上LLVM的中间表示。
模块化的划分,避免了因编程语言和CPU架构的翻新而引发的编译器适配性问题,大大简化了编译器的开发工作。
神经网络编译器
其输入是深度学习训练框架训练出来的模型定义文件,输出是能够在不同硬件高效执行的代码。

从上至下由四个层级组成:
1. 最上层对接各个深度学习训练框架训练出来的算法模型(Tensorflow, Caffe, Pytorch, Mxnet等)。
2. 图层级(High-level IR):神经网络的结构可以表示成计算图,图层级的操作则是对计算图进行一些和具体硬件和框架无关的操作,比如算子融合,内存分配优化,数据类型和数据维度的推导等。

我们可通过算子融合的方式,避免中间数据频繁的在寄存器和内存直接来回读写,从而提升整体推理性能。

Nividia通过把conv, bn, relu这三个算子融合成一个算子 fuse- CBR. 实现了三倍的推理性能提升。
3. 算子层级(operator level/kernel level)算子层级主要是张量计算。为了实现这些计算在硬件上高效实现,发挥芯片的性能,通常硬件芯片配有专门优化的算子计算库,如Intel的MKL, Nvidia的CuDNN, TensorRT。这个层级需要支持每个硬件后端的算子实现。
4. 各硬件后端:GPU, ARM CPU, X86 CPU, NPU等。

自深度学习编译器的概念提出以来,各类编译器变层出不穷的出现。
TVM的前世今生
在编译器快速发展的浪潮中,较为突出的便是TVM(Tensor Virtual Machine)。
TVM最早提出是2017年,是深度学习系统的编译器堆栈。
第一代TVM的设计借鉴了借鉴传统编译器框架LLVM的设计思路,设计抽象出中间表示层,不同的模型只需要开发相应的前端接口,不同的后端只需要开发相应的后端接口。
TVM全称为Tensor Virtual Machine,属于算子层级,主要用于张量计算,提供独立于硬件的底层计算中间表示,采用各种方式(循环分块,缓存优化等)对相应的计算进行优化。第一代的图层级表示叫NNVM(Neural Network Virtual Machine)。NNVM的设计目标是:将来自不通深度学习框架的计算图转换为统一的计算图中间表示(IR),对之进行优化。
第一代的静态图存在一定的缺陷:
1. 不能较好支持控制流,如分支跳转,循环等。
2. 不能支持计算图输入形状,取决于输入tensor大小的模型,比如word2vec等。
虽然Tensorflow有如tf.cond.Tf.while_loop的控制接口来在某种程度上解决第一个问题,tf.fold来解决第二个问题,但是这些方式对刚刚接触深度学习框架的同学来说门槛过高。
后面出现的动态图摒弃了传统的计算图先定义,后执行的方式,采用了计算图在运行时定义的模式,这种计算图就称为动态图。
第二代TVM的图计算层变为Relay VM,Relay和第一代的图计算表示NNVM的最主要区别是Relay IR除了支持dataflow(静态图), 能够更好地解决control flow(动态图)。它不仅是一种计算图的中间表示,也支持自动微分。

总结一下,目前TVM的架构是:
1. 最高层级支持主流的深度学习前端框架,包括TensorFlow,MXNet,Pytorch等。
2. Relay IR支持可微分,该层级进行图融合,数据重排等图优化操作。
3. 基于tensor张量化计算图,并根据后端进行硬件原语级优化,autoTVM根据优化目标探索搜索空间,找到最优解。
4. 后端支持ARM、CUDA/Metal/OpenCL、加速器VTA(Versatile Tensor Accelerator)。
Halide
Halide于2012年提出,主要用于自动优化。其嵌入到C++中,是MIT研究人员专门为图像处理设计的一种程序语言。Halide语言易于编写,语法简单,数据结构清晰,能过自动对代码进行优化,使得程序获得比较好的执行效率。
它设计的核心思想是把算法和调度分离。这样做的好处是,在给定算法的情况下只需要去调整它的Schedule 调度选择,不用重写算法实现不同的Schedule。当调整Schedule、探索设计空间时也不会担心因为重写算法而导致计算的正确性会发生变化。
Algorithm部分主要是算法描述和计算的数学表达式。
Halide于2012年提出,主要用于自动优化。其嵌入到C++中,是MIT研究人员专门为图像处理设计的一种程序语言。Halide语言易于编写,语法简单,数据结构清晰,能过自动对代码进行优化,使得程序获得更好的执行效率。
它设计的核心思想是把算法和调度分离。这样做的好处是,在给定算法的情况下只需要去调整它的Schedule 调度选择,不用重写算法实现不同的Schedule。当调整Schedule、探索设计空间时也不会担心因为重写算法而导致计算的正确性会发生变化。
Algorithm部分主要是算法描述和计算的数学表达式。
Schedule部分则是告诉机器什么时候分配内存,如何计算(分块计算还是顺序计算)——目前已经提供了一些调度策略。


不同调度策略考虑重复冗余计算和局部性(locality)的权衡。
AutoKernel
深度学习模型能否成功在终端落地应用,满足产品需求,一个关键的指标就是神经网络模型的推理性能。
目前的高性能算子计算库主要是由高性能计算优化工程师进行手工开发。然而新的算法/硬件的不断涌现,导致了算子层级的优化开发工作量巨大。同时优化代码的工作并不是一件简单的事,它要求工程师既要精通计算机体系架构,又要熟悉算子的计算流程。
人才少,需求多,技术门槛高,因此我们认为算子优化自动化是未来的大趋势。而提出AutoKernel的初衷便是希望能把这个过程自动化,从小处入手,在算子层级的优化,实现优化代码的自动生成。

AutoKernel的输入是算子的计算描述(如Conv、Poll、Fc),输出是经过优化的加速源码。
这一工具的开发旨在降低优化工作的门槛,不需要有底层汇编的知识门槛,不用手写优化汇编。可通过直接调用开发的工具包便可生成汇编代码。同时还提供了包含CPU、GPU的docker环境,无需部署开发环境,只需使用docker便可。还可通过提供的插件——plugin,可以把自动生成的算子一键集成到推理框架中——Tengine。

对应地,算子层级的AutoKernel则主要分为三个模块,
1. Op Generator:算子生成器,采用了开源的Hallide。
2. AutoSearch:目前还在开发中,目标是通过机器学习、强化学习常用算法自动搜索出优化策略。
3. AutoKernel Plugin:把生成的自动算子以插件的形式插入到Tengine中,和人工定制互为补充。

Tengine对象层对接了不同的神经网络模型,图层级的NNIR包含了模型解析、图层优化,算子层级则包括高性能计算库(HCL lib)。
AutoKernel Plugin主要分为生成和部署两部分,生成部分用Hallid填写算法描述和调度策略,执行时指定后端类型(基本覆盖目前的主流后端)。
部署部分则封装为Tengine的库,直接调用。

相信随着更多开发者的加入,AutoKernel开源社区会有更大的突破与成长,在未来的深度学习编译器领域中,留下浓重的一笔!
项目开源Github地址:
https://github.com/OAID/AutoKernel

(加入AI科技评论顶会交流群,观看AI研习社同步直播)
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看
”。











