👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇作者丨alert1
来源丨掌控安全EDU
一、数据加载和转储
训练集数据
读取训练集部分数据,我得到的恶意代码的样本都是多个线程对API的调用序列,
所以需要按照file_id对每个恶意代码进行分组然后将每个恶意代码的标签保存到labels中
将api调用序列按线程排序逐个保存到files中,是一个有顺序的长序列,
最后分别将labels和files序列化保存在两个不同的json文件中
测试集数据
与训练集数据大致相同,不过没有标签,它在后面是将file_name(每个恶意代码的序号)和files序列化保存在两个不同的json文件中
这样就初步处理了下面实验要用到的数据,并将他们保存到了易于读取的josn文件中。
数据全部读取
#读取训练集文件
labels =[]#标签
files =[]#训练集api调用序列
print('读取训练集')
data = pd.read_csv(train_path)#,nrows=15000000)#将训练集的前nrows行读取并保存到data中
goup_fileid = data.groupby('file_id')#将data按照file_id进行分组
for file_name, file_group in goup_fileid:#将标签和调用顺序提取出来分别保存到labels和files两个列表中
#print(file_name)
file_labels = file_group['label'].
values[0]
result = file_group.sort_values(['tid','index'], ascending=True)
api_sequence =' '.join(result['api'])
labels.append(str(file_labels))
files.append(api_sequence)
#print(result)
#print(labels)
#print(files)
with open("security_train_labels.json",'w')as f:#分别将labels和files序列化保存在两个不同的json中
json.dump(labels, f)
with open("security_train_files.json",'w')as f:
json.dump(files, f)
print('读取完毕')
二、加载json文件中的数据
with open("security_train_labels.json","r")as f:#加载处理完的json文件
labels = json.load(f)#标签
with
open("security_train_files.json","r")as f:
files = json.load(f)#训练集api调用序列
#with open("security_test_names.json", "r") as f:
# file_names = json.load(f) #测试集样本序号
with open("security_test_outfiles.json","r")as f:
testfiles = json.load(f)#测试集api调用序列
三、数据处理
训练集标签处理
加载出来的标签是一个list格式的数据,我们先将它转换为数组格式
再使用keras内置函数对它进行one-hot编码,将它转换成二维张量
对此,标签处理完毕。
api调用长序列处理
我们先构造一个词生成器,将训练集和测试集中出现的api加入到词生成器中,
每个api对应一个索引,然后对训练集和测试集分别进行替换,
最后再将格式转换为整数张量,以便于输入模型,其中,设定单个恶意代码的api序列长度最大为6000
labels = np.asarray(labels)
labels = to_categorical(labels)
tokenizer =Tokenizer()#为测试集和训练集所有api产生一个索引
tokenizer.fit_on_texts(files)
tokenizer.fit_on_texts(testfiles)
maxlen =6000#单个恶意代码的api序列长度最大为6000
index = tokenizer.word_index
x_train_word = tokenizer.texts_to_sequences(files)#将api名转换为tokenizer中的索引
x_out_word = tokenizer.texts_to_sequences(testfiles)
x_train = preprocessing.sequence.pad_sequences(x_train_word, maxlen=maxlen)#将整数列表转换为整数张量
x_test = preprocessing.sequence.pad_sequences(x_out_word, maxlen=maxlen)
val_data = x_train[10000:]
x_train = x_train[:10000]
val_labels = labels[10000:]
labels= labels[:10000]
四、训练模型
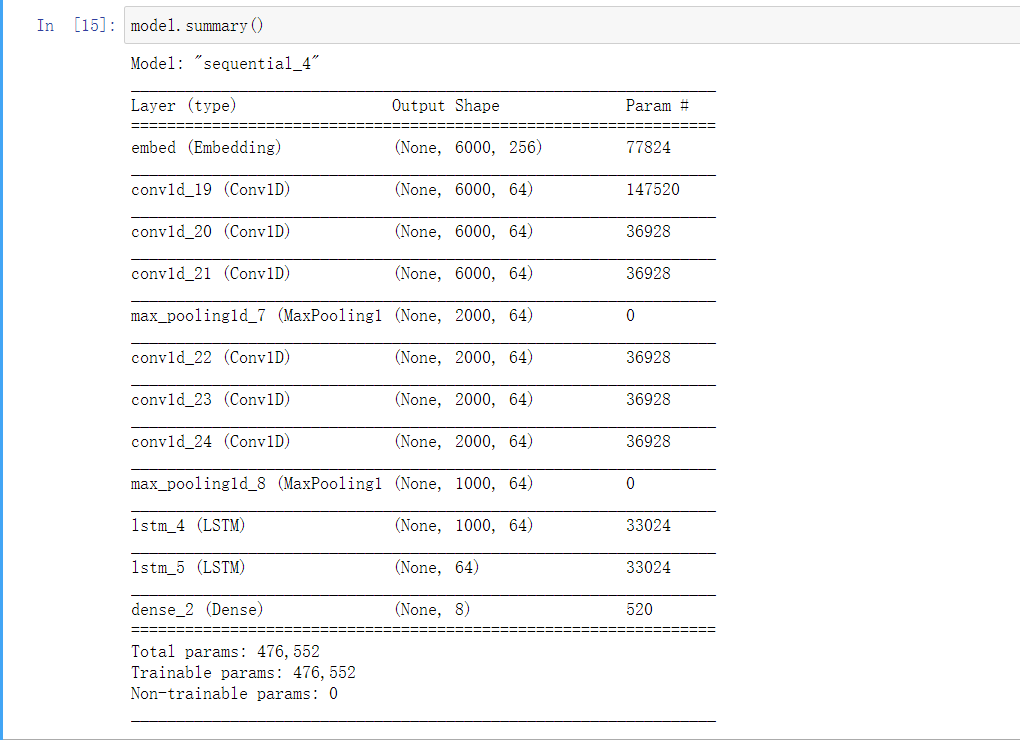
层的堆叠
第一层是Embedding层,将前面形成的api索引映射为一个密集向量,64维度,参数数量277*64=17728
第二,三层是一维卷积层
第四层是一维最大池化层
第八层是LSTM长短期记忆层,单个隐藏空间是32维度,
参数323212+32*4=12416的变换
最后一层是大小为8的Dense层,他输出了八个不同的概率值
选择每一层都是经过一定的考虑的,首先词嵌入产生的密集向量比独热编码产生的稀疏向量可以将更多信息塞入到更低的维度中,
而且词嵌入是从数据中学到的一种方式
一维卷积层可以得到长序列文本的空间信息
一维池化层用于降低一维输入的长度
LSTM层(长短期记忆)减轻了RNN中的梯度消失问题,是比较好的处理有顺序的模型,因为它可以获取前面的信息,同时还有GRU层,他是rnn和lstm的折中
最后一个dense的意思是对于每个输入样本,网络都会输出一个8维向量,向量中的每个元素都代表不同的输出类别。
这层使用的是softmax激活,网络将输出在8个不同输出类别上的概率分布
词嵌入
词嵌入的作用应该是将人类的语言映射到几何空间中。
可以理解为一个字典,将整数索引(表示特定api)映射为密集向量。
他接受整数作为输入,并在内部字典中查找这些整数,然后返回相关联的向量。
将一个Embedding层实例化时,它的权重(及标记向量的内部字典)最开始是随机的,与其他层一样。
在训练过程中,利用反向传播来逐渐调节这些词向量,改变空间结构以便下游模型可以利用。
一旦训练完成,嵌入空间将会展示大量结构,专门针对训练模型所要解决的问题.
嵌入矩阵(180,256)
(180,6000) -> (180,6000,256)
eg.比如单词:baby 可能经过训练后可由[-0.2,0.1,0.15,0.24,0.45]这样一个向量表示,
虽然每个位置单独没有意义,但是这样构成的向量的确是可以表示这一个单词的。
一维卷积层
一维卷积层可以识别序列中的局部模式.因为对每个序列段执行相同的输入变换,所以可以在句子中某个位置学到的模式稍后可以在其他位置被识别,
这使得一维卷积神经网络具有平移不变性.可以学到模式的空间层次结构。
每个输出时间步都是利用输入序列在时间维度上的一小段得到的. 输入(samples,time,features)
序列数据的一维池化
一维池化运算:从输入中提取一维序列,然后输出其最大值(最大池化)或平均值(平均池化),用于降低一维输入的长度
model =Sequential()
model.add(layers.Embedding(304,256,input_length=maxlen,name ='embed'))
model.add(layers.Conv1D(64,9,padding='same'
,activation='relu'))
model.add(layers.Conv1D(64,9,padding='same',activation='relu'))
model.add(layers.Conv1D(64,9,padding='same',activation='relu'))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(64,9,padding='same'
,activation='relu'))
model.add(layers.Conv1D(64,9,padding='same',activation='relu'))
model.add(layers.Conv1D(64,9,padding='same',activation='relu'))
model.add(layers.MaxPooling1D())
model.add(layers.LSTM(64,dropout=0.1,recurrent_dropout=0.5
,return_sequences=True))
model.add(layers.LSTM(64,dropout=0.1,recurrent_dropout=0.5))
#model.add(layers.Bidirectional(layers.LSTM(64,dropout=0.1,recurrent_dropout=0.5)))
#model.add(layers.Dense(32,activation = 'relu'))#,input_shape = (4,)))
model.add(layers.Dense(8,activation ='softmax'))
优化器
rmsprop优化器通常都是足够好的选择,同时也使用了它默认的学习率
损失函数
我在训练中使用的是categorical_crossentropy(分类交叉熵)这个损失函数
它用于衡量两个概率分布之间的距离,这里两个概率分布分别是网络输出的概率分布和标签的真实分布。
通过将这两个分布的距离最小化,训练网络可使输出结果尽可能接近真实标签。
训练指标
accuracy精度,衡量成功的指标
训练轮数和训练批次
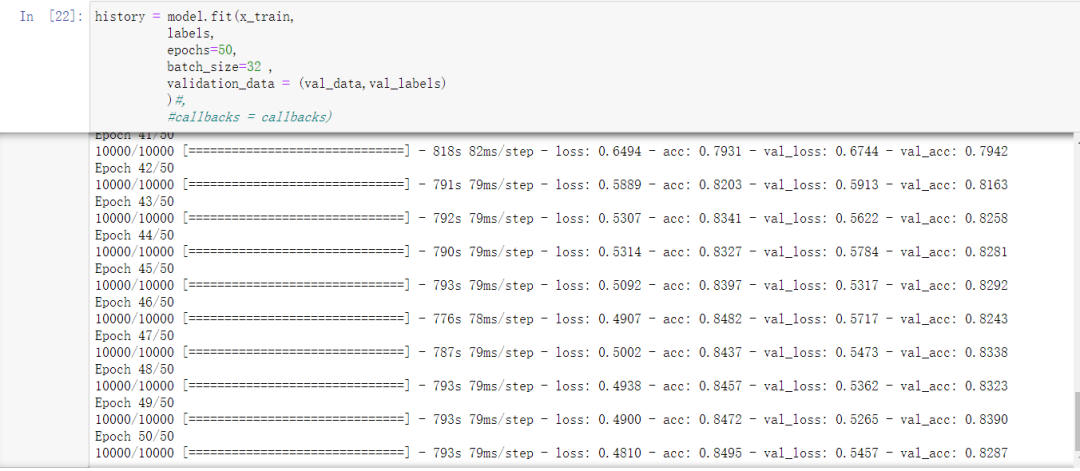
这个是在几次实验后得到的比较合理的选择,训练轮数本打算让它过拟合后再进行选择
但是因为计算速度的限制,也是没有增加验证集的原因,没有看到过拟合,只训练了50轮,暂且够用(没有过拟合)
训练批次主要是受gpu资源影响,最好是单批次32个数据,再多会报错。
model.compile(optimizer=RMSprop(lr=1e-4),loss='categorical_crossentropy',metrics=['acc'])#adma优化器 losslog lr=1e-4
history = model.fit(x_train,
labels,
epochs=50,
batch_size=32,
validation_data =(val_data,val_labels)
)#,
#callbacks = callbacks)
histogram_freq参数会在面板中添加histograms面板和distributions面板
会将每一个层的权值、偏置、输出值的统计分布以不同的视觉角度显示出来
因为权重等信息的存在,现在日志文件变为了111M,增大了很多。
#可视化
callbacks =[
keras.callbacks.TensorBoard(
log_dir ='log',
#histogram_freq=1,#显示histograms和distributions面板
#histogram_freq = 1,
#write_graph=True,
#write_images=True
#embeddings_freq = 1,
#embeddings_layer_names = 'embed',
#embeddings_data=None#.astype(float)
)
]
开始训练
训练了50轮,轮数有点少了,下面是进行绘图
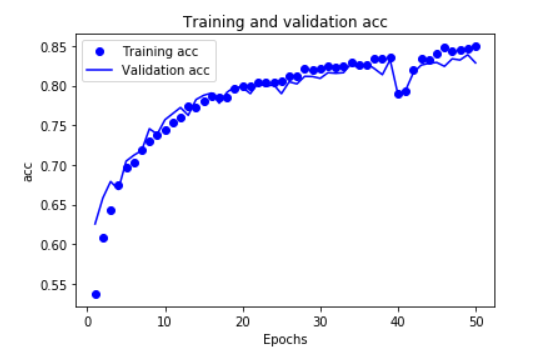
history_dict = history.history
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
epochs = range(1,
len(acc_values)+1)
plt.plot(epochs,acc_values,'bo',label ='Training acc')
plt.plot(epochs,val_acc_values,'b',label ='Validation acc')
plt.title('Training and validation acc')
plt.xlabel('Epochs')
plt.ylabel('acc')
plt.legend()
plt.show()
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1,len(loss_values)+1)
plt.plot(epochs,loss_values,'bo',label ='Training loss')
plt.
plot(epochs,val_loss_values,'b',label ='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend()
plt.show()
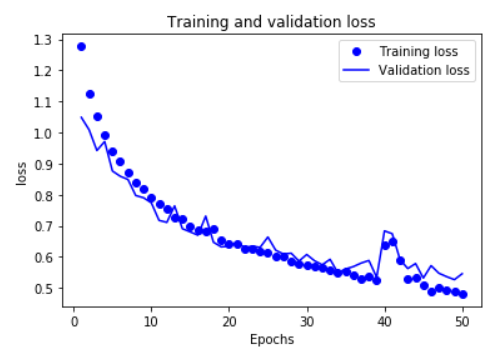
在这两幅图中可以看出,我的训练并没有得到这个模型的最好的效果,
因为就目前来看,它并没有得到一个过拟合的模型,所以我应该继续增加训练的轮数,找到过拟合的点。
这是我多次修改后的使用的一部分模型,因为训练花费的时间太长,快10个小时...
接下来我会对当前模型进行重新训练得到过拟合的点。
测试集训练
model.save('ali1.h5')
#model = tensorflow.keras.models.load_model('ali1.h5')
predictions = model.predict(x_test,batch_size =1)
test_labels = pd.DataFrame(predictions,
#index=['a','b','c','d','e']
index = range(1,len(predictions)+1),
columns=['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']
)# 默认生成整数索引, 字典的键作列,值作行
test_labels.index.name ='file_id'
test_labels.to_csv('test_labels.csv')
五、不足与改进
数据处理,线程是没有顺序的
层数的堆叠不够
应该可以使用卷积池化层来处理长序列
开发不出来过拟合的模型,难以进行更好的矫正
还可以使用一些特征工程上的方法,比如对api的调用数量进行统计,对不同恶意代码的api调用进行分析
还可以将数据倒序输入网络进行训练,可能会发现其它特殊的特征
调用keras函数式API搭建更复杂有效的网络
要使用keras自带的回调函数进行训练,可以进行终止,实时调试等
单个模型效果有限,要结合机器学习以及深度学习多模型进行集成
六、绕过方法
可以恶意病毒的调用API过程中随机插入调用一些其他的序列,破坏其API调用的特征和各个API调用序列的整体分布情况,达到绕过的效果。
基于深度学习的方法对序列的长度有着较大的限制,病毒制作者可以一开始先调用一些无关的API
等调用长度超出深度学习检测的限制的时候再开始调用恶意API
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓









