
量化投资与机器学习公众号独家解读
量化投资与机器学公众号 QIML Insight——深度研读系列 是公众号今年全力打造的一档深度、前沿、高水准栏目。

公众号遴选了各大期刊最新论文,按照理解和提炼的方式为读者呈现每篇论文最精华的部分。QIML希望大家能够读到可以成长的量化文章,愿与你共同进步!
第一期 | 第二期 | 第三期 | 第四期 | 第五期 | 第六期
第七期
本期遴选论文
来源:The Journal of Financial Data Science Summer 2021
作者:Oleksandr Proskurin
标题:Does the CFTC Report Have Predictive Power: Machine Learning Approach
核心观点
- 基于CFTC的COT持仓报告构建特征,应用随机森林模型预测未来一周的趋势。
- 如果按照周五的披露,该数据并没有可以预测未来趋势的有用特征。
- 如果假设周二就可以获得数据,则该数据有可以明显预测未来趋势的有用特征。
- 其中基于资金管理人MMs的Trade Group Performance特征表现较优。
对于国内投资的参考意义:
国内交易所每日收盘后也会提供各品种的持仓数据,相比CFTC来的更及时,可以参考数据标注及特征构建的方法,测试该方法在国内市场的效果。
COT持仓报告
在美国市场,根据商品期货交易委员会(Commodity Futures Trading Commission)于1962年设立的要求,各大期货交易者必须定时(在美国时间每周五下午3:30)向商品期货交易委员报告当周周二的持仓数据(Commitments of Traders,COT),若遇上当周美国有公假,CFTC持仓报告发布时间通常会推迟一个工作日发布,数据来自芝加哥、纽约、堪萨斯城和明尼安纳波利斯的期货或期权交易所。CFTC报告是全球投资者非常关注的报告,虽然数据本身与中国市场的期货公司每日持仓排名相比,存在一些时间滞后,但根据CFTC公布出来的当周的持仓报告数据,投资者可以根据报告中的持仓数量、增减变化、各类持仓所占比例变化、交易商数量变化等,作为投资判断一些持续时间较长的趋势性行情的重要参考标准。
对于量化交易而言,其中最重要的是分类报告(Disaggregated Report),披露的详细格式及数据如下图所示,其中会按不同的交易者类型披露其当周的持仓数据。注意是周五披露截至到当周周二的数据。其中交易者按一下分类:
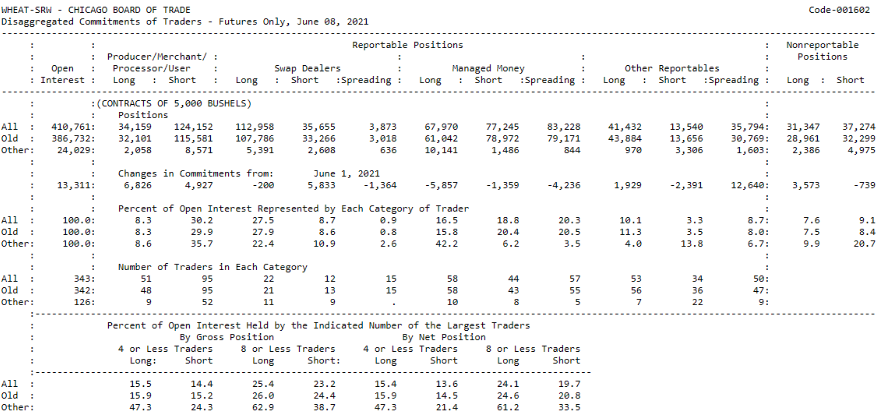
这些持仓报告的数据中,特别是MMs组的数据,是否存在可以预测未来趋势的信息,由于报告是在周五才披露周二的数据,这个延迟披露是否会影响数据的有效性。在本篇报告中,作者就以上问题做了探讨。
基于COT分类持仓报告的特征构建
第一类特征:常规指标

第二类特征:TRADING GROUP PERFORMANCE(TGR)
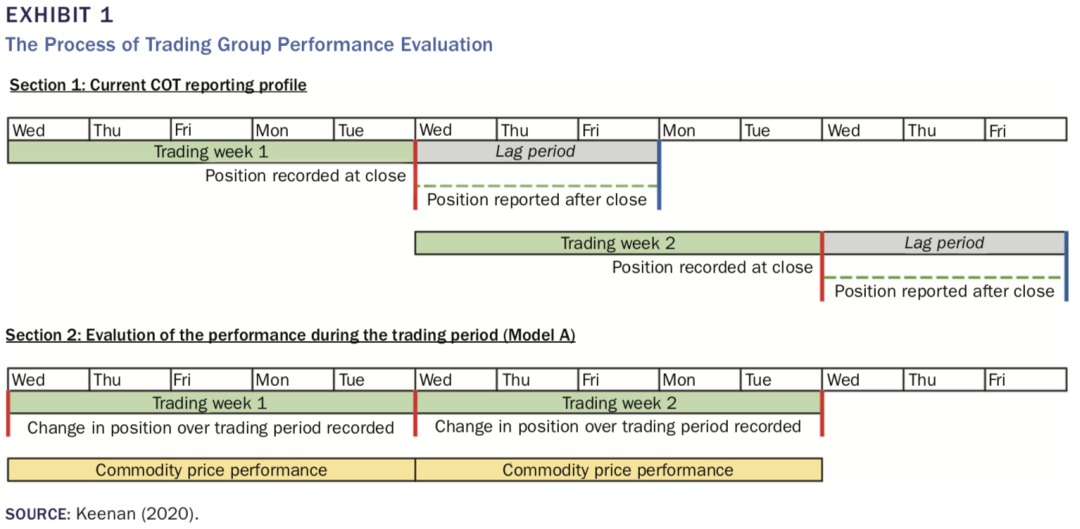
记录每组每周初与周末的净持仓(如下图1,Section 1所示)
如果周初与周末的净持仓方向一致,则假设一整周的净持仓都未发生变化
如果周初与周末的净持仓方向不一致,那么本周的数据就不会用在后面的实证分析中。但需要记录每个商品期货中,发生这种情况的数据占所有数据的比例(以周为单位)
记录每周该商品期货的收益率
对于各组,如果净持仓方向与期货的收益率一致,则该组的TGR指标加上这周的收益率,如果净持仓方向与期货的收益率相反,则该组的TGR指标减去这周的收益率。以Money managers(MMs)组为例,如果本周MMs组的净持仓为Long,且期货上涨了1%,则在本周MMS的TGR指标等于上周MMs的TGR指标加上1%;相反,如果本周MMs组的净持仓为Short,且期货上涨了1%,则在本周MMS的TGR指标等于上周MMs的TGR指标减去1%。
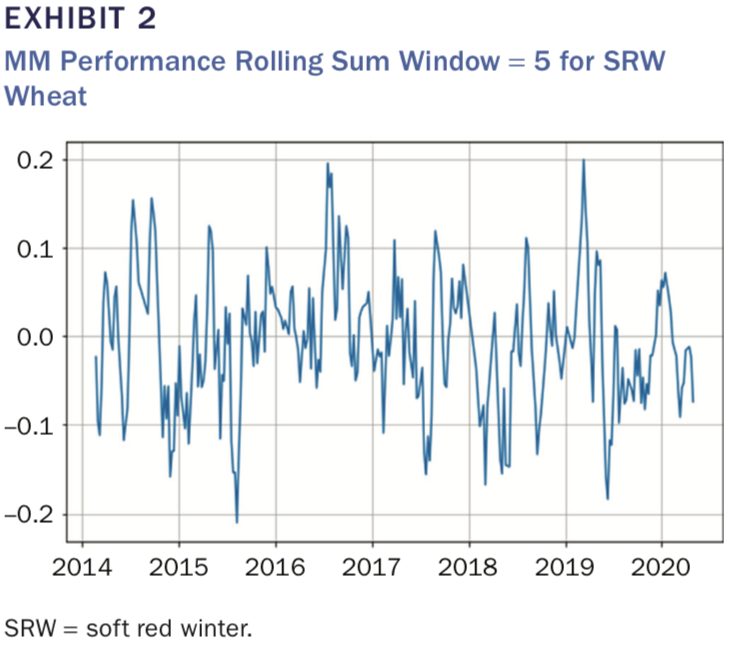
除了每组每周的TGR指标,作者还计算了TGR与该期货Long-Only策略的收益差,及TGR的变化及滚动总和,如图2为MMs组TGR的5日滚动之和。

第三类特征:CONCENTRATION AND CLUSTERING RANGE
这类指标主要基于持仓情况和交易者的数量来构建超买超卖指标,该类特征由以下几个指标计算而来:
MM(L/S):MMs组,Long(或short)的持仓数量
MM(L/S)T:MMs组,Long(或short)的交易者(Traders)数量
MM(L/S)%:MMs组,Long(或short)的持仓数量变化的百分比
MM(L/S)T%:MMs组,Long(或short)的交易者(Traders)数量变化的百分比
min(MM(L/S)%range):过去一段时间(range),MM(L/S)%的最小值
本篇论文中,range的取值为2、5、10、20及50。
数据标注与模型选择
基于López de Prado (2020),作者采用趋势扫描标注法(Trend Scanning Labeling),用以标注当天的行情是处于一段上升趋势(+1)、下降趋势(-1)还是无趋势(0)中。代码参考如下:
import statsmodels.api as sm1
def tValLinR(close): # tValue from a linear trend
x=np.ones((close.shape[0],2))
x[:,1]=np.arange(close.shape[0])
ols=sm1.OLS(close,x).fit()
return ols.tvalues[1]
def getBinsFromTrend(molecule,close,span):
'''
Derive labels from the sign of t-value of linear trend Output
includes: - t1: End time for the identified trend - tVal: t-value
associated with the estimated trend coefficient - bin: Sign of the
trend
'''
out=pd.DataFrame(index=molecule,columns=['t1','tVal','bin'])
hrzns=xrange(*span)
for dt0 in molecule:
df0=pd.Series()
iloc0=close.index.get_loc(dt0)
if iloc0+max(hrzns)>close.shape[0]:
continue
for hrzn in hrzns:
dt1=close.index[iloc0+hrzn-1]
df1=close.loc[dt0:dt1]
df0.loc[dt1]=tValLinR(df1.values)
dt1=df0.replace([-np.inf,np.inf,np.nan],0).abs().idxmax()
out.loc[dt0,['t1'
,'tVal','bin']]=df0.index[-1],df0[dt1], np.sign(df0[dt1]) # prevent leakage
out['t1']=pd.to_datetime(out['t1'])
out['bin']=pd.to_numeric(out['bin'],downcast='signed')
return out.dropna(subset=['bin'])
数据范围为CFTC披露的2014年至2020年5月的COT分类持仓报告,作者选择的机器学习模型为随机森林(Random Forest)。
指标重要性判断方法
Mean Decrease Accuracy Feature Importance(MDA)
平均准确度下降法(MDA,Mean Decrease Accuracy):OOS样本外计算,适用于任何模型,最重要的是,它直接比较了将某特征进行无序打乱前后,训练结果的评价指标准确度的下降情况。
原理:打乱每个特征的特征值顺序,并且度量顺序变动对模型精确率的影响。对于不重要的变量来说,打乱顺序对模型的精确率影响不大,但对于重要的变量来说,打乱顺序就会降低模型的准确率。
实现步骤:
1、训练出一个随机森林模型,在测试集检验得到accuracy0;
2、随机重排(permutation)测试集某特征xi,检验得到accuracyi;
3、(accuracy0- accuracyi)/accuracy0,即为特征xi的重要性。
Shapley Values
Shapley value最大的优势是SHAP能对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。因此Shap值承担了后xgboost时代树模型的解释任务。关Shapley的详细解释参考知乎文章:https://zhuanlan.zhihu.com/p/91834300
Python中的SHAP库可以很方便的实现Shapely Values的计算,在Github中超过了15K的star。
实证步骤
在包含所有特征的数据集上拟合随机森林分类器模型,使用四组的k-fold方案获得交叉验证的log loss和accuracy评分。
基于MDA和Shapley值,评估各特征的重要性。
基于筛选后的模型计算交叉验证的模型得分并与随机猜测的模型进行比较。
实证结果
实证过程中,作者测试了两种情况,第一种是按照CFTC正常的披露时间(周五)测试模型表现;第二种是假设周二就可以获得COT的持仓报告。然后比较这两种情况下,模型的表现有没有区别。
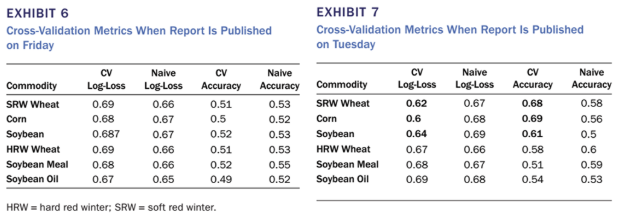
从下表6(周五公布)及下表7(假设周二公布)的模型结果来看,其中Naive为随机猜测的模型。可以看出,正常时间(周五)公布数据的模型效果还比不上随机猜测的模型,说明这些特征并没有预测的效果。相反,如果周二就能拿到持仓数据,效果明显要优于随机猜测的结果。
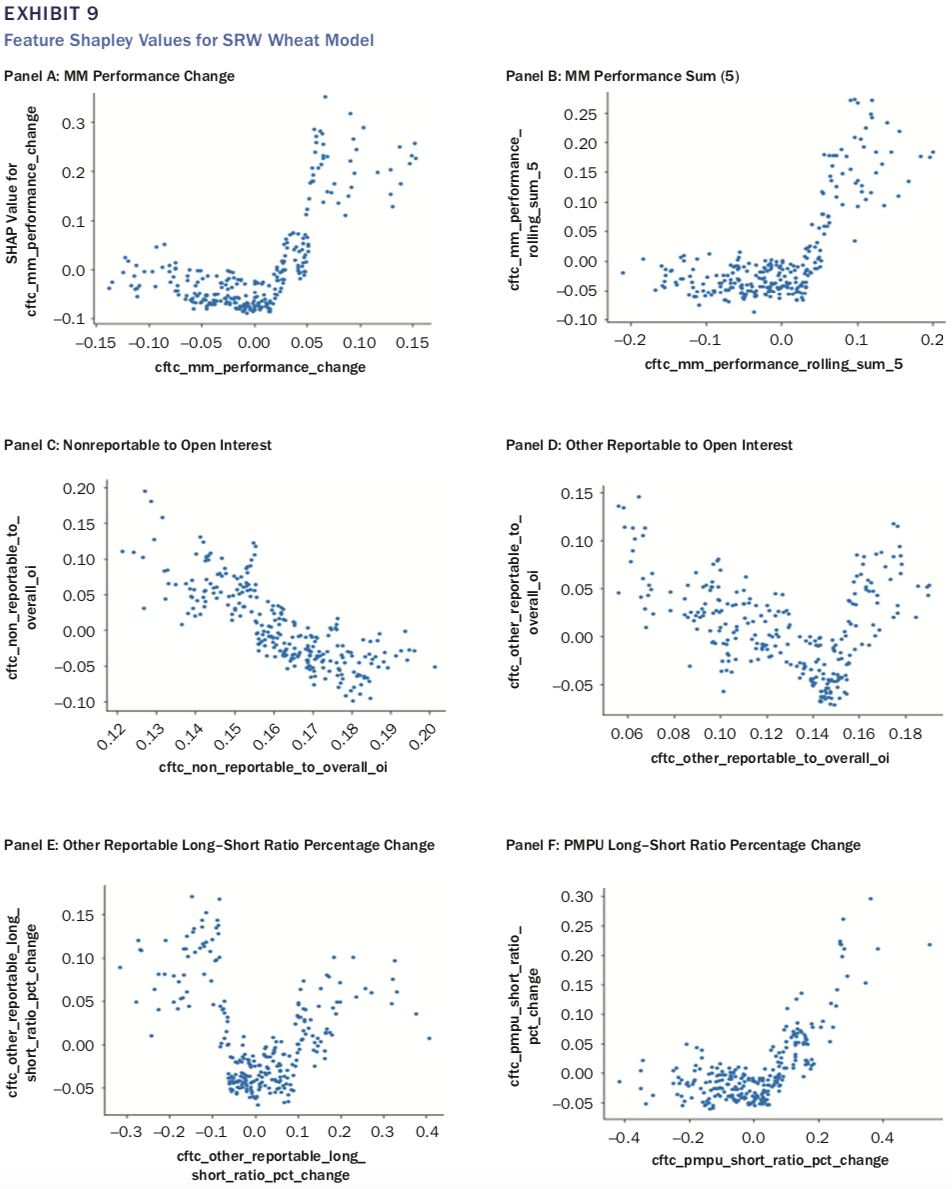
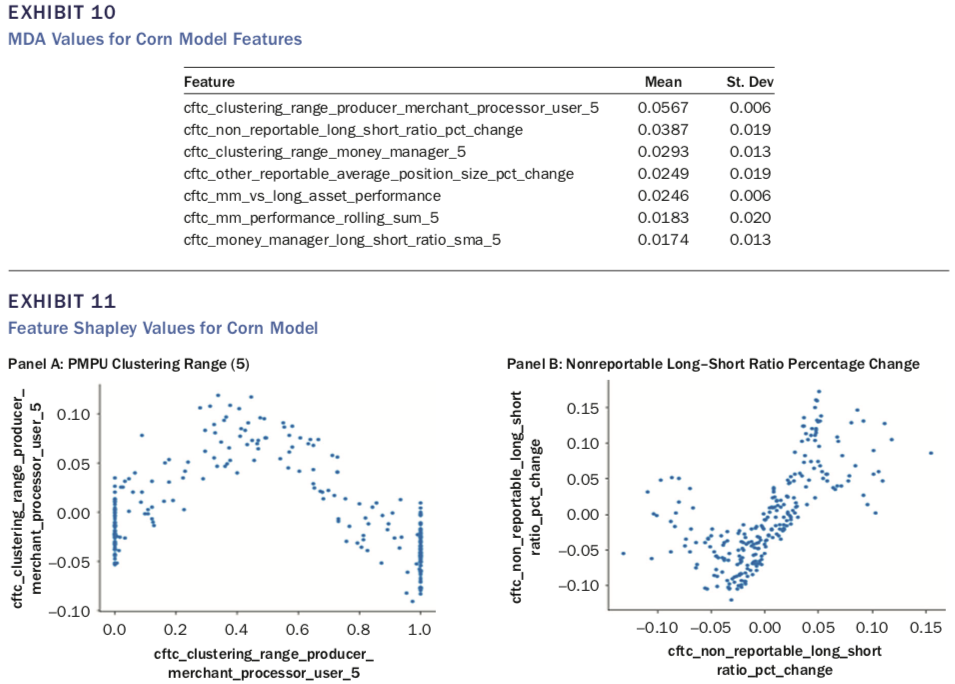
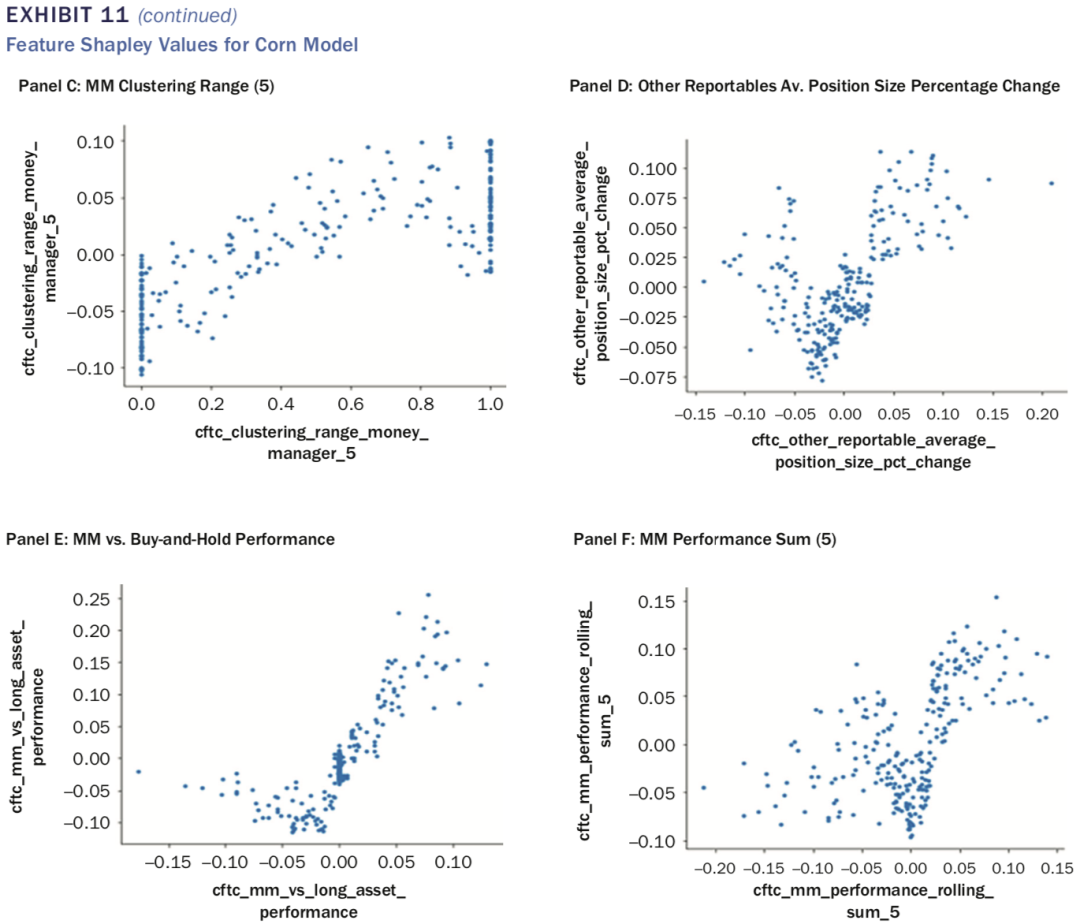
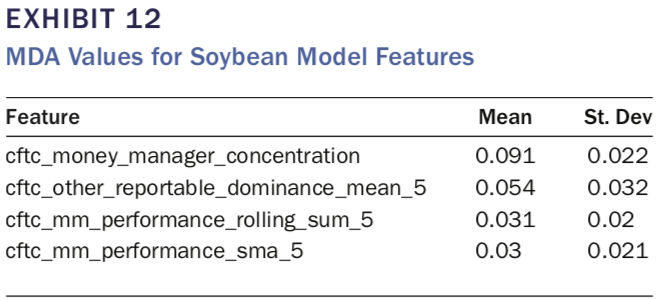
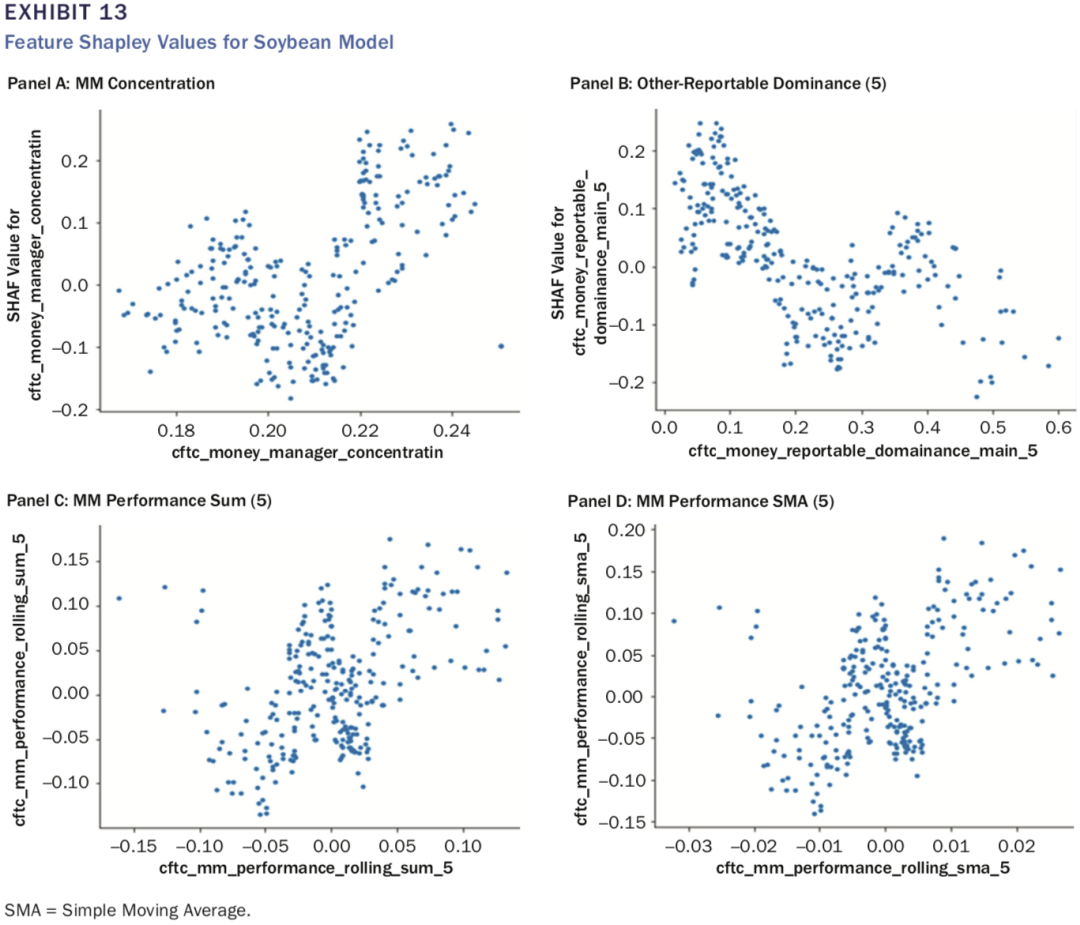
接下来,作者分别给出了对于SRW Wheat、Corn及Soy Bean三个期货品种,分别给出了筛选后比较重要的特征(见表8,10及12),可以看出MMs组的第二类指标(如cftc_mm_performance)均出现在较重要的指标列表中。

参考文献:
López de Prado, M. 2018. Advances in Financial Machine Learning. Hoboken: John Wiley & Sons, 2018.
Machine Learning for Asset Managers. Cambridge, UK: Cambridge University Press, 2020.
量化投资与机器学习微信公众号,是业内垂直于量化投资、对冲基金、Fintech、人工智能、大数据等领域的主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业20W+关注者,连续2年被腾讯云+社区评选为“年度最佳作者”。










