
第一作者:Chenchen Wang
通讯作者:柏耀辉
通讯单位:中国科学院生态环境科学研究中心
论文DOI:10.1016/j.watres.2021.117185
导读由于邻近土地利用模式和排污源的不同,河流系统的水质可能会发生变化。这些变化可以引起水生微生物群落的快速反应,这可能是水质特征的一个指标。在目前研究中,我们采用随机森林模型,基于环境理化指标(PCIs)、微生物指标(MBIS)及其组合预测了三种不同河流生态系统的水样来源,这些河流生态系统沿人为干扰梯度分布(干扰较少的山区、城市污水排放区和施农药化肥的农业区)。结果表明,在基于PCI的模型中,使用常规水质指数作为输入对水样来源的预测明显优于使用药品和个人护理用品(PPCPs),并且比使用多环芳烃(PAHs)及其衍生物(SPAHs)的预测要好得多。在基于MBI的模型中,使用前30名细菌的丰度结合致病性抗生素耐药菌(PARB)作为输入,获得了最低的中位数(out-of-bag error rate)聚合错误率(9.9%)和增加的中位数kappa系数(0.8694),而添加真菌输入降低了kappa系数。与基于PCIs或PCIs和MBIs组合的模型相比,基于前30名细菌的模型仍然显示出优势。随着测序技术的改进和未来数据可用性的提高,该方法为基于微生物群落的丰度数据识别水样来源提供了一种经济、快速、可靠的方法。
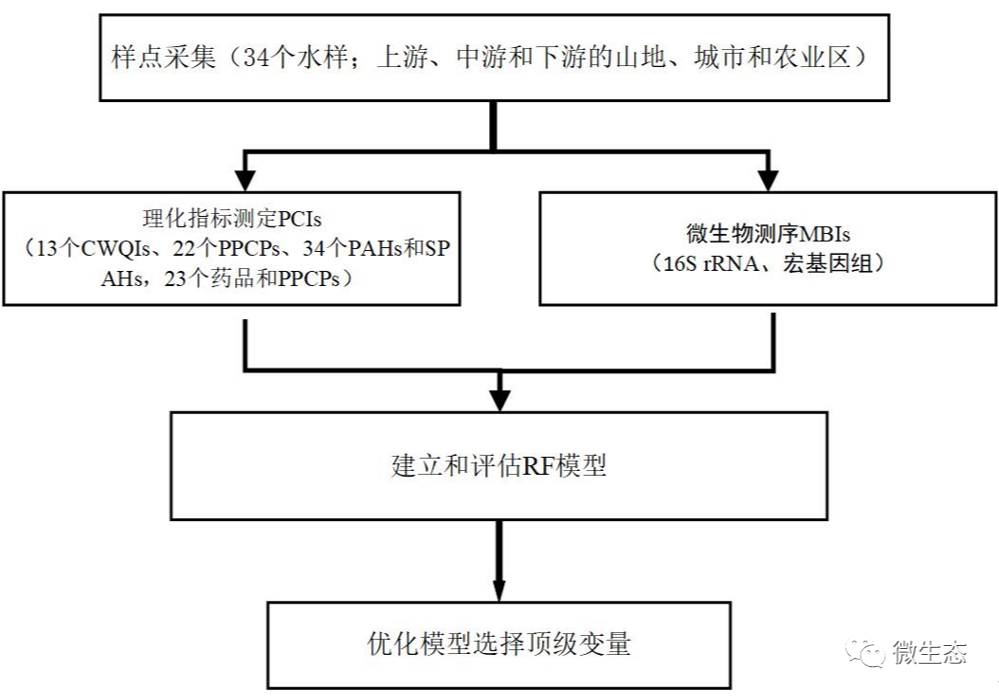
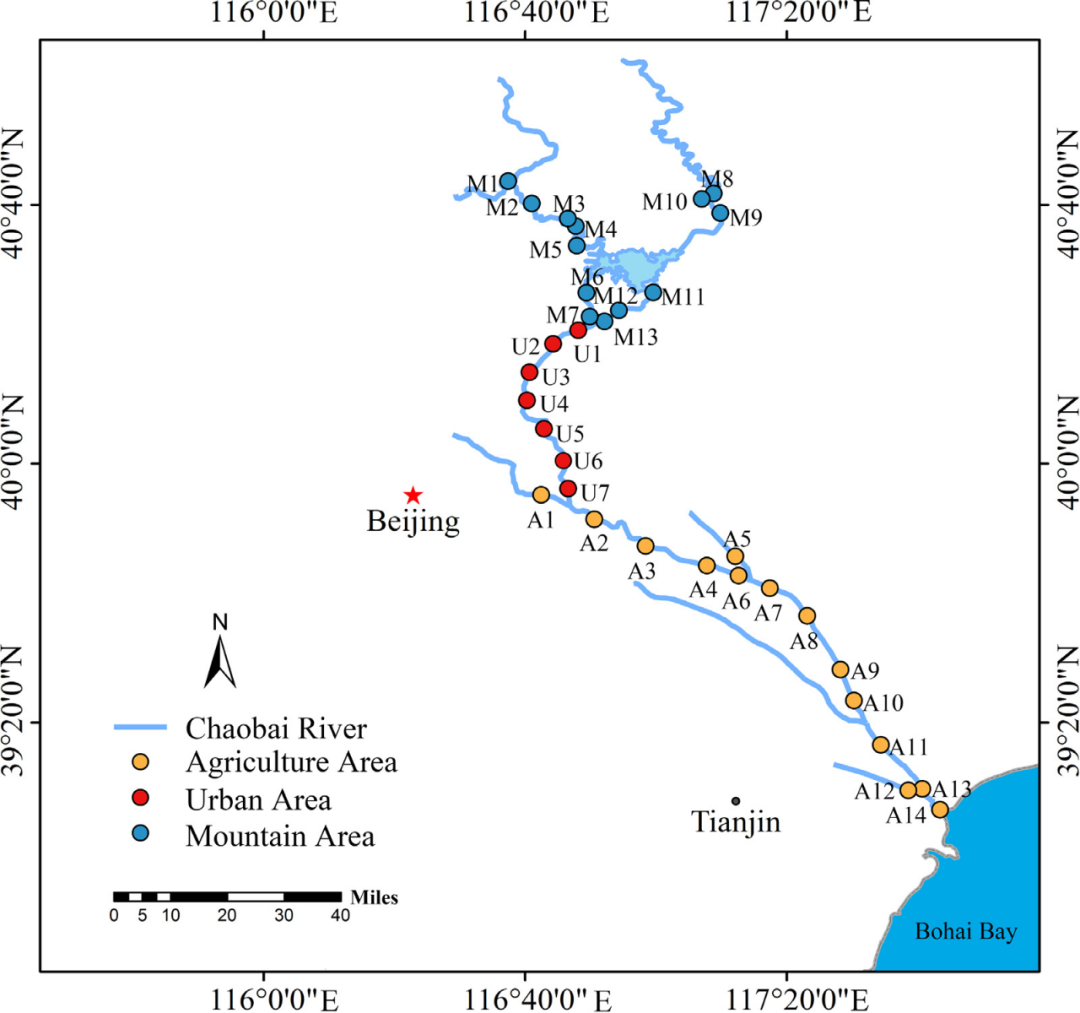
图1. 潮白河采样点。根据土地利用类型,选取了34个具有代表性的样点,并将其划分为位于上游、中游和下游的山地(M1-M13,蓝点)、城市(U1-U7,红点)和农业区(A1-A14,橙点)三个区域。
在RF模型中,只考虑了环境PCIs,使用了四组输入,包括13个CWQIs、22个PPCPs、34个PAHs和SPAHs,以及全部71个PCIs。将四种模型的精度与图2(a)和(b)所示的错误率和kappa系数的OOB估计以及表S2所示的具体统计值进行了比较。仅基于CWQIs的模型具有最低的OOB误差,范围为11.22%-14.29%(中位数为12.24%),kappa系数相对较高,范围为0.7002-0.8641(中位数为0.7511)。这些结果仅略低于基于所有PCIs模型所获得的结果,这表明尽管CWQIs模型中未包含PPCPs和(S)PAHs的重要信息,但CWQIs可以反映不同功能区大部分水质特征。基于所有71个PCIs的模型的kappa系数中值最高,为0.7979,但范围也较大(0.5891-0.9388),表明预测结果不如基于CWQIs的模型稳定,这可能是由于部分PPCPs和(S)PAHs的输入参数噪声的影响。仅基于PPCPs的模型也具有16%的较低中值OOB误差和0.7076高中值的kappa系数,但在很宽的范围内(0.4526-0.9351)是不稳定的。仅基于PAHs和SPAHs的模型预测效果最差,OOB误差中位数最高(28.71%),kappa系数中位数最低(0.4704)。 在所有71个PCIs的数据集划分的10个随机种子的10个计算中,最好的3个预测具有相对较低的OOB误差,分别为12.84%、15.6%和17.43%,以及相应的较高的kappa系数为0.8792、0.9189和0.9388。因此,它们被选为输入变量的重要性排序。图2(c)显示了按MDA中位数排名前30位的PCIs的排名结果。表S3提供了三个最佳预测中所有71个PCIs的MDAs及其中位数排名结果。这三个排序结果相似,表明分析的可靠性。因此,采用MDAs的中位数进行进一步分析。总体而言,大多数CWQIs的MDA值高于其他变量,DOC、NH4+-N、COND、NO3—N、TP、TDS、ORP和SRP的MDAs中位数分别为37.88、33.10、32.39、21.25、19.35、17.31、13.27和12.66。因此,这些重要的CWQI变量反映了不同功能区之间水质的主要差异。几种PPCPs表现出非常高的MDA值,例如卡马西平(CBZ,72.84)、磺胺甲恶唑(SMX,18.11)、苯扎贝特(BF,17.34)和美托洛尔(MET,12.15),而排名前30位的几种PPCPs表现出中等高MDA值,范围在5.09-8.95之间,例如磺胺嘧啶(SDZ)、甲氧苄啶(TMP)、洛美沙星(LOM)、土霉素(OTC)、金霉素(CTC)、罗红霉素(ROX)、咖啡因(CAF)。结果表明,CBZ在所有PCIs中排名第一,甚至高于CWQIs,这表明CBZ可以作为水环境中一种可能的人为标记,这与之前的几项研究一致。CBZ在污水处理中的广泛使用和有限的清除导致大量CBZ进入地表水体;CBZ在自然环境中也很难降解。我们的研究还表明,TPPCPs(MDA为16.04)在预测中发挥了重要作用,在MDA排名中排在第11位。这表明TPPCP浓度是人类活动的一个重要指标,可以用来区分水样来源。在我们前期的研究中,潮白河沿岸不同土地利用类型中大多数药物的检测频率和浓度表现出明显的空间异质性,可能来源于不同的污染源。城区中检出的药物与毗邻河流的污水处理厂密切相关,而农业区还受到周边家庭和畜牧场未经处理的废水的影响。除1-CN(19.17)和D-CN(15.81)分别排在第7位和第12位,以及排在前20位的Ace(9.62)、BKF(9.07)、1-ClPyr(6.73)和Acy(5.62)外,PAHs和SPAHs的MDAs普遍较低。值得注意的是,这些MDA含量较高的PAHs和SPAHs在整个河流中的浓度水平都很低。特别是,1-CN的最大值仅为2.9 ng/L,在大多数M个采样点都未检测到,这可能导致了其区域敏感性。而总体浓度较高的PAHs和SPAHs,如AT、AQ、9-FL、NAP和Phe的MDA值较低(分别为-0.04、3.32、4.24、0.27和0.46),表明不同地区之间没有显著差异。可以推测,地表水中这些PAHs的主要来源可能是大气沉降或其他重要来源,而不是污水厂排放。因此,重要性排序进一步证明了采用CWQIs作为输入模型比单纯基于PPCPs或(S)PAHs的模型更好地预测了水样来源。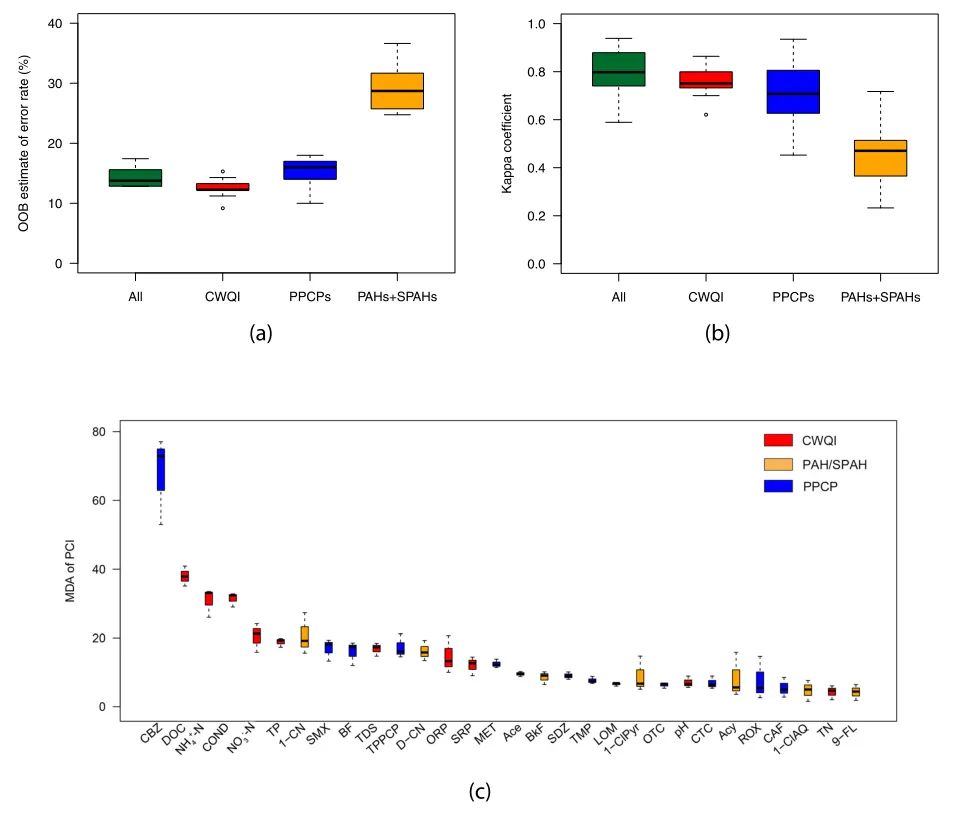
图2. 利用RF算法和PCIs的重要性排序,对四组环境PCIs(CWQIs、PPCPs、PAHs和SPAHs以及全部71个PCIs的预测性能进行了比较。(a)、OOB估计错误率;(b)、kappa系数;(c)、排名前30位的PCIs的平均精度下降(MDA)。
根据71个PCIs的平均重要性排序,将前10、20、30、40和50个PCIs分别作为预测水样来源的输入。预测结果的OOB估计错误率和kappa系数如图3所示,具体的统计数据见表S2。与基于所有PCIs的模型相比,使用前10个PCIs作为输入显著降低了OOB误差的中位数(13.76%至11.93%),并增加了kappa系数(0.7979至0.8260)。然而,基于前20、30、40和50个变量的模型的OOB误差中位数分别增加到12.39%、12.84%、12.84%和13.76%,这表明太多的环境变量不仅不能提供有用的信息,而且还可能引入冗余的噪声,特别是在观测数据非常有限的情况下。使用前30个PCIs获得了最高的中值的kappa系数为0.8492,但与基于前10个PCIs的模型相比,预测也不太稳定。然而,尽管这些PCIs模型在训练集上通常显示稳定的OOB误差,但使用新数据进行预测的kappa系数非常不稳定。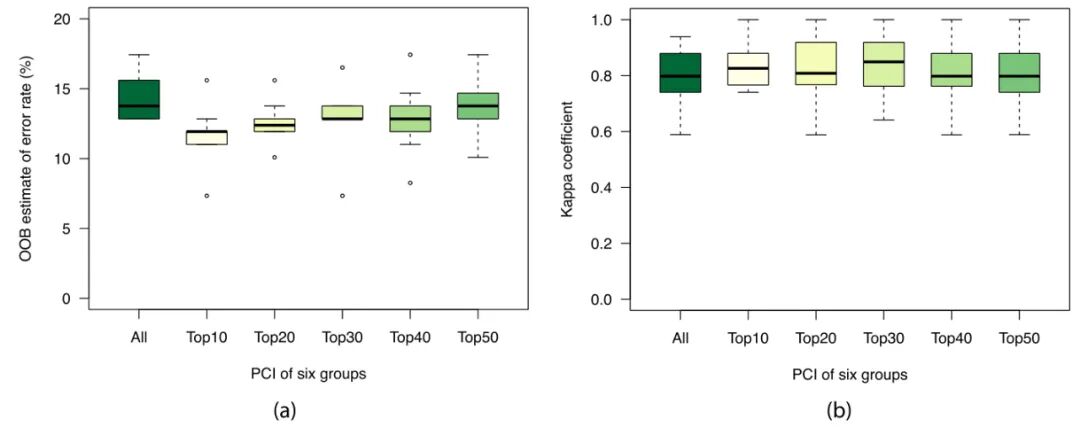
图3. 使用RF算法基于前10、20、30、40、50和所有PCIs的预测性能比较。(a)、OOB估计错误率;(b)、kappa系数。
将所有样本中检测到的1045个细菌OTUs的相对丰度数据作为RF建模运行的输入,建立10个随机种子以形成不同的数据集分区。选择准确率最高的进行重要性排序。根据基于PCIs的预测优化过程,选取细菌重要性排名前10、20、30、40和50个变量作为输入,建立RF模型。预测结果如图4所示,具体的统计数据见表S4。所有五个简化模型都明显减小了OOB误差,提高了kappa系数。基于前30个细菌变量的模型表现最好,最低的中位OOB误差(10.89%)和最高的中位kappa系数(0.8592)。相比之下,前10个变量和前20个变量不足以反映不同地区之间的水质差异,OOB误差中位数分别为15.84%和13.37%,kappa系数中位数分别为0.7525和0.7973。相反,在前40和前50个模型中,随着细菌变量的不断增加,噪声也被引入,OOB误差中位数分别为11.39%和12.87%,kappa系数中位数较低,分别为0.8587和0.8139。因此,前30个细菌集被认为是最佳的输入集,并与真菌和PARB集合相结合进行进一步预测。排在前30位的细菌大多属于变形杆菌和拟杆菌。表S5提供了前30种细菌注释结果的具体信息。如图2(b)和图3(b)所示,基于具有126条观察记录的5组顶级细菌的模型与基于PCI的模型(具有136条观察记录)相比,对新数据的预测更稳定。为了比较每一类的预测精度,确定了A,M和U的平衡精度,如图4(c)-(e)所示。基于前30个细菌的模型,A类的平衡精率很高,在0.9091到1的稳定范围内(中位数为0.9655)。对于M类,以前50个细菌为基础的模型预测效果最好,虽然较高,但在0.8831~1的较不稳定范围内(中位数为0.9792)。在所有RF模型中,U类的平衡精度都很低。这主要是因为与A和M(分别为48和53个样本)相比,样本数量(25个)较少,导致建模运行不足。尽管A类样本比M类样本少,但平衡精度普遍较高。可以推断出山地水样中较高的细菌多样性可能导致需要更多的细菌输入变量来充分阐明特征。需要注意的是,对于相同的RF模型,预测精度随着测试集中U个样本的增加而降低,这取决于数据集划分的随机性。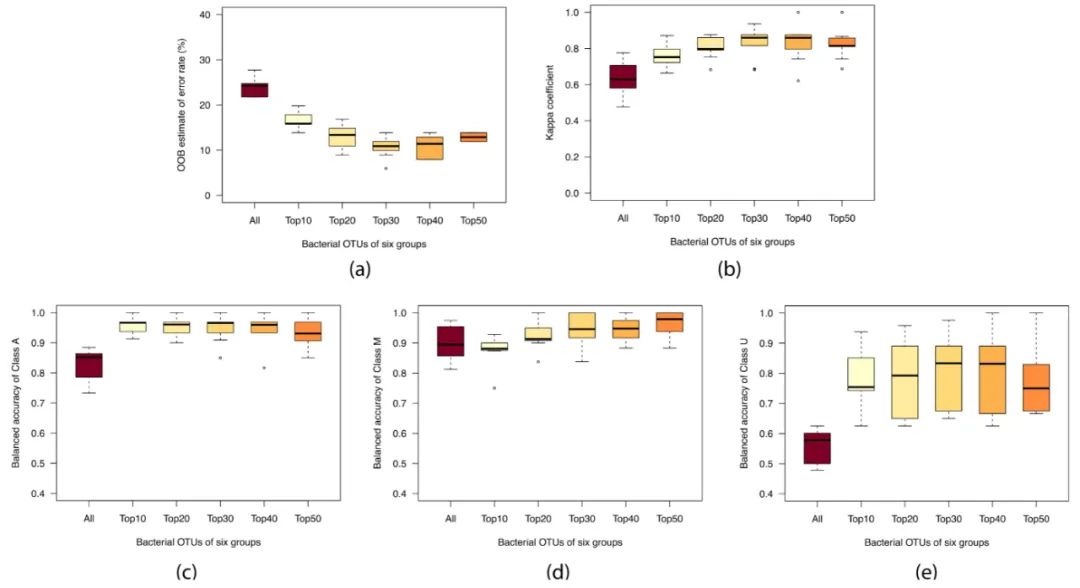
图4. 使用RF算法基于前10、20、30、40、50和所有细菌OTUs的丰富数据的预测性能比较。(a)、OOB估计错误率;(b)、kappa系数;(c)、A类平衡精度;(d)、M类平衡精度;(e)、U类平衡精度。
根据细菌变量的选择和优化过程,将所有样本中检测到的423个真菌OTUs的相对丰度数据作为RF模型的输入用10个随机种子进行训练。然后,通过重要性排序选择前10、20、30、40和50个真菌变量作为输入,基于RF模型预测水源。预测结果如图5所示,具体统计数据见表S4。在6组以基于真菌的模型中,使用前30个变量获得了最佳预测,OOB误差中值为27.55%,kappa系数中值为0.6049。使用前30位的真菌建立的模型也获得了对A,M和U类的最好预测,中值平衡精度分别为0.8534,0.8782和0.6409。然而,与细菌模型不同的是,A类的平衡精度低于M类。此外,基于真菌的模型的预测性能明显差于基于细菌模型,表明真菌群落没有表现出与细菌群落相同的环境敏感性。表S6提供了排名前30位的真菌注释结果的具体信息。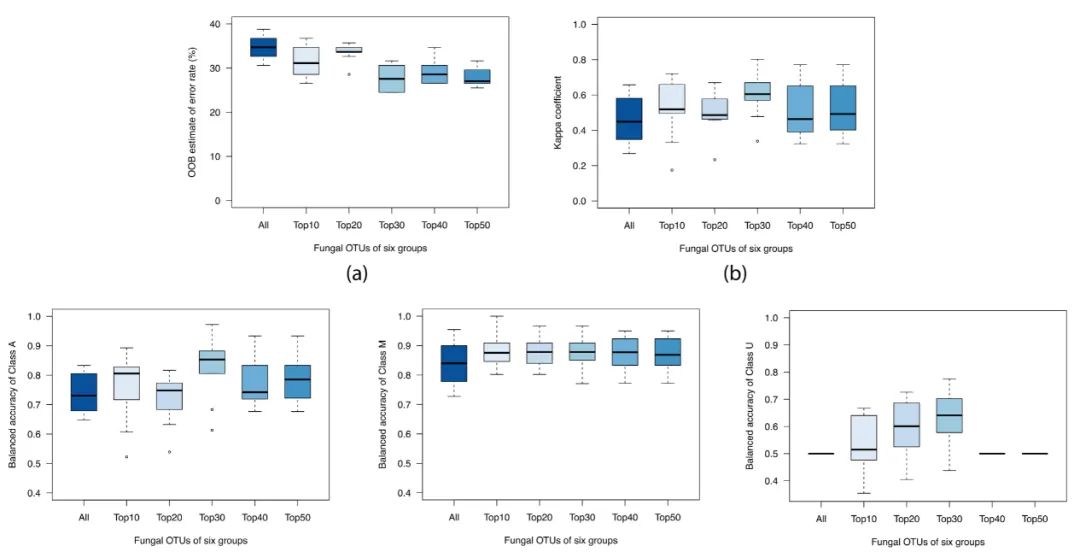
图5. 使用RF算法基于前10、20、30、40、50和所有真菌OTUs的丰富数据的预测性能比较。(a) 、OOB估计错误率(b)、kappa系数(c)、A类平衡精度(d)、M类平衡精度(e)、U类平衡精度。
为进一步优化输入变量,前30名细菌与PARB(“MBI-31”)和前30名细菌与PARB和前30名真菌(“MBI-61”)分别作为输入预测水样来源。基于MBI-61对最佳预测进行重要性排序,分别选取前10、20、30、40和50个MBI变量作为输入进行预测。它们的性能比较如图6所示,具体的统计数据见表S7。如图6所示,所有顶级MBI输入都提供了较低的OOB错误率和较高的中值kappa系数。然而,与仅基于顶层细菌的模型(图3(b))相比,图6(b)中的kappa系数通常表现出更广泛的范围,表明真菌变量的加入导致了预测的不稳定性。此外,根据图6(c)所示的重要性排序,只有3种真菌进入前30MBIs,进一步表明细菌群落对水样差异的指示作用比真菌群落强得多。在七组MBIs值中,以MBI-31输入的预测效果最好,中值OOB误差为9.9%,中值kappa系数为0.8694,略好于仅以前30个细菌为基础的模型,表明PARB在预测中起到了积极的作用。因此,与PARB结合的前30种细菌是最好的MBI输入集,尽管PARB的加入略微降低了分类的稳健性,这可能是受数据量有限的影响。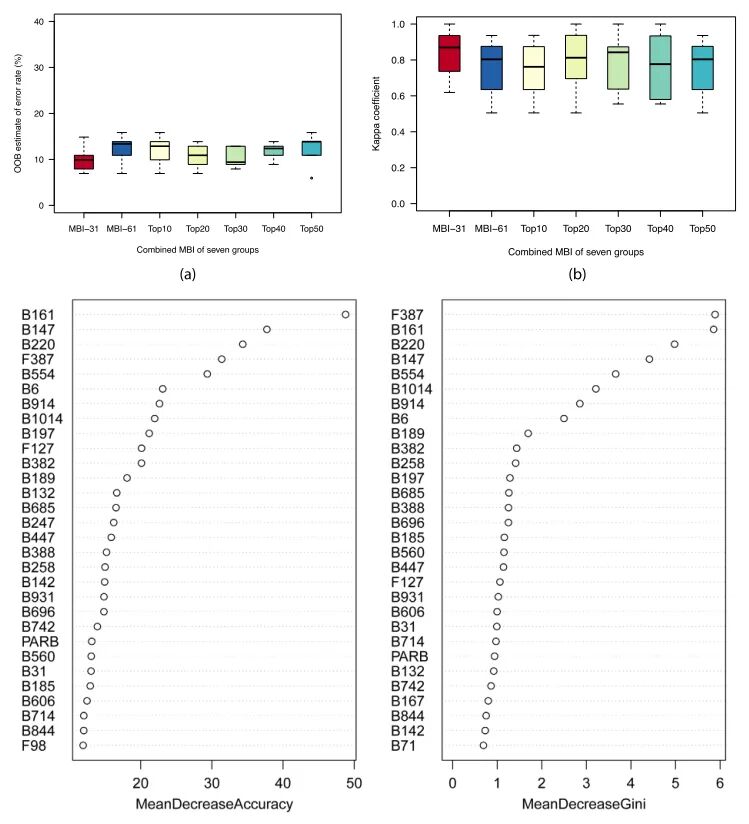
图6. 使用RF算法的基于不同微生物组合的预测性能的比较,包括前30个细菌与PARB(“MBI-31”)的组合输入,前30个细菌与前30个真菌和PARB(“MBI-61”,变量的重要性排序)的组合输入,以及使用RF算法的前10、20、30、40和50个MBIs的组合输入。(a) 、OOB估计错误率(b)、kappa系数(c)、根据MBI-61进行最佳预测的前30个MBIs的重要性排序(注:B为细菌,F为真菌)。
对前20个MBIs的丰度和它们在最佳预测中的平均MDA值(如上所述)进行了相关性分析,结果以相关系数(R)表示,如表1所示。每个MBI的绝对量是用其丰度乘以用流式细胞仪分析水样中的绝对细胞计数得出的。排在前20位MBIs的MDAs与其丰度(数量)之间的R值很低,表明没有显著的线性相关性。先前的研究表明某些优势细菌属不像非优势细菌属那样对环境敏感。表1. 排名前20位MBIs的MDAs与其丰度(数量)之间的相关系数(R)。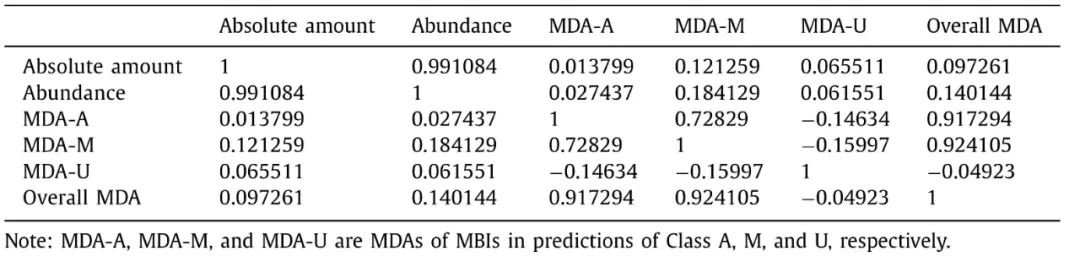
基于MBIs, PCIs及其组合的RF模型的预测性能的比较如图7所示。根据重要性排序(图S2),基于前10、20、和30个组合输入进一步执行预测。正如所见,使用组合输入略微提高了预测的稳健性。特别是,使用前20和前30个组合输入得到的中位数kappa系数分别为0.8738和0.8769,略高于MBI-31(0.8694),这可能是由于更多数据的优势。然而,基于前30个细菌和PARB相结合的模型仍然是所有模型中最低的OOB误差估计中值(9.90%),这表明它们在反映水质特征方面的重要性和可靠性。根据重要性排序(图S2),CBZ的MDA仍居首位,远远超过其他输入,再次表明其反映人类活动的指示性作用。此外,NH4+-N、B147、COND、B161、B220和DOC也表现出很高的MDAs。值得注意的是,在大多数A样品中未检测到B147(g_Fimbriimonas),而B161(f_GZKB119)仅在A、U样品中检测到。
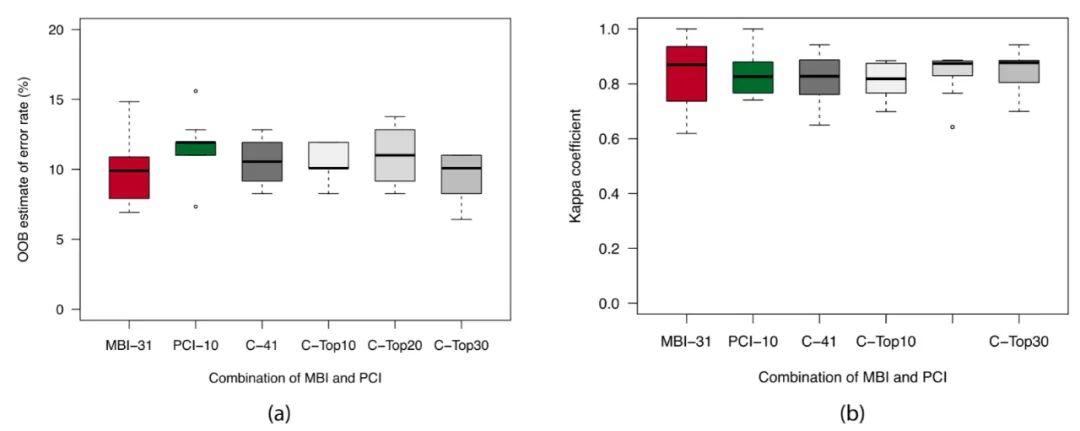
图7. 基于MBIs、PCIs和使用RF算法的不同组合的预测性能比较,包括前30名细菌与PARB(“MBI-31”)、前10个PCIs(“PCI-10”)及其组合(“C-41”),以及组合中的前10、20和30个(分别为“C-Top10”、“C-Top20”和“C-Top30”)。(a) 、OOB估计错误率;(b)、kappa系数。
对前30个MBIs的丰度(PARB)与全部71个PCIs的测量数据进行了相关分析。结果分别以层次聚类 (图8)和原始顺序(图S3)表示。如图8所示,几种细菌即B189(f_Cytophagaceae),B1014(f_auto67_4W),B6(g_Nitrosopumilus),B560(c_koll11),B31(o_YLA114)和B559(c_PBS-25)表现出相似的特征,并与DOC呈强负相关,与某些PPCPs(如CBZ)和(S)PAHs(如1-CN,D-CN,2-CN,Ace和9-FL)呈中度或弱负相关。发现这些细菌与B132(o_Gaiellales)、B71(o_Actinomycetales),B258(f_Saprospiraceae)和B931(f_Xanthomonadaceae)呈负相关。B167(g_Paludibacter)和B161(f_GZKB119)也表现出相似的反应,与NH4+-N,CAF,ROX,TPPCP,Fluo、2,6-DMN、DOX和SRP呈正相关。此外,被注释为黄杆菌科(Flavobacteriaceae)的B220与电导率呈显著正相关。先前的研究表明,黄杆菌科(Flavobacteriaceae)对周围环境很敏感。如图S3所示,总体而言,前30位细菌中的大多数与CWQIs具有较强的相关性,其次是SPAHs,PPCPs和PAHs。值得注意的是,b197(g_Leadbetterella)与几种(S)PAHs表现出强烈的相关性,包括Phe,Ant,Flua,Pyr,BaA,Chry、BbF和9-Clphe,这是以前未报道的。鉴于这些化合物之间的高度相关性,我们推测Leadbetterella可能与这些(S) PAHs中的一种或几种的降解有关。此外,PARB与一些传统的PCIs和SPAHs相关,而不是与抗生素PPCPs相关,与B914( Pseudomonas )呈高度正相关,如先前研究报告。因此,可以推断大多数顶级MBIs的丰度受多种环境PCIs和其他微生物相互作用的综合影响。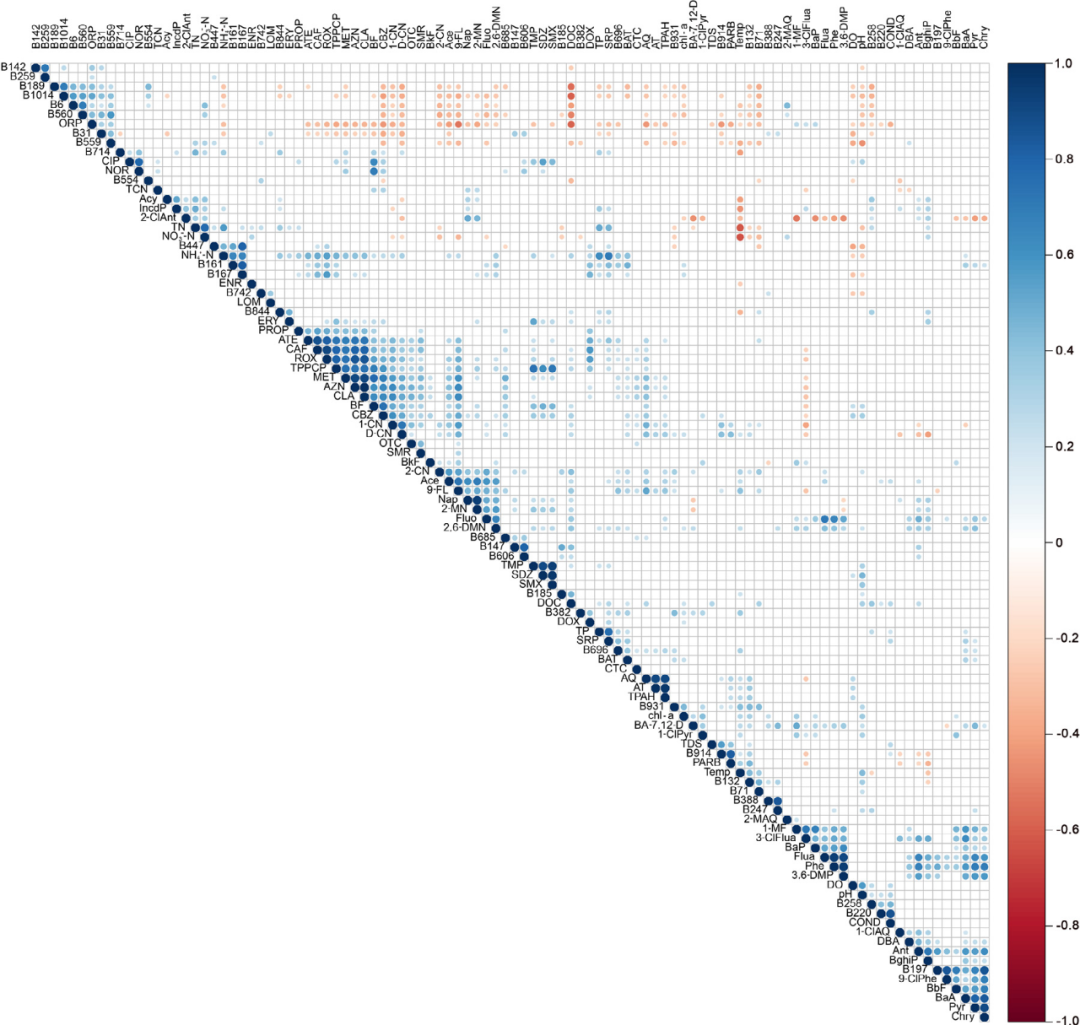
图8. 前30个MBIs(和PARB)的丰度与所有71个PCIs测量数据在显著性水平P=0.05的相关分析(按等级聚类顺序显示)。
我们探索和开发了一种基于RF模型的快速、可靠的水样来源识别方法。主要结论如下:(1)在基于PCI的模型中,使用CWQIs作为输入的分类效果明显好于PPCPs,也明显好于使用PAHs和SPAHs的分类效果。使用基于重要性排序优化预测的前10位PCIs指标。(2)在基于MBI的模型中,细菌输入比真菌输入能更好地识别水样的来源。在基于MBIs、PCIs及其组合的模型的比较中,重要性排名前30位的细菌结合PARB作为输入提供了最好的预测。随着未来样本数据可获得性的不断提高,基于MBI的模型应该会显示出更大的优势,并有可能扩展到工业废水和污染物的可追溯性。
来源:微生态。投稿、合作、转载、进群,请添加小编微信Environmentor2020!环境人Environmentor是环境领域最大的学术公号,拥有近10W活跃读者。由于微信修改了推送规则,请大家将环境人Environmentor加为星标,或每次看完后点击页面下端的“在看”,这样可以第一时间收到我们每日的推文!环境人Environmentor现有综合群、期刊投稿群、基金申请群、留学申请群、各研究领域群等共20余个,欢迎大家加小编微信Environmentor2020,我们会尽快拉您进入对应的群。











