公众号:尤而小屋
作者:Peter
编辑:Peter
在以前的一篇文章 图解Pandas的排序机制sort_values 详细介绍了如何使用pandas的内置函数sort_values来实现数据的排序。本文讲解的是如何使用自定义方式来实现排序:

模拟数据
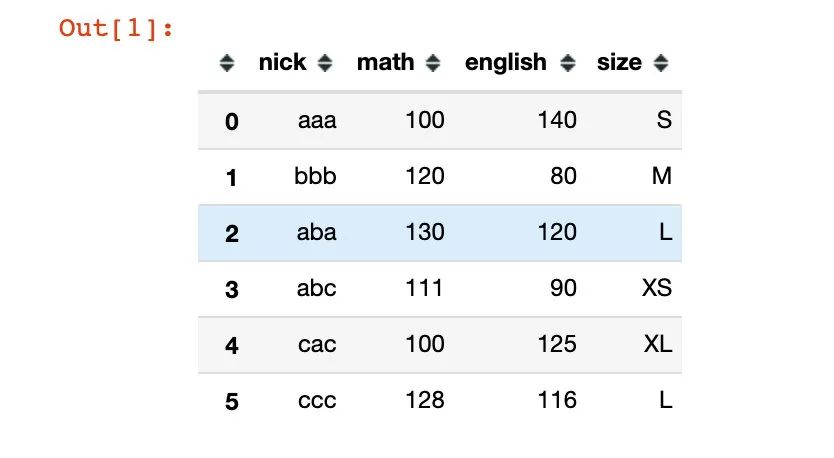
先模拟一份简单的数据:
import pandas as pd
import numpy as np
df = pd.DataFrame({
"nick":["aaa","bbb","aba","abc","cac","ccc"], # 昵称
"math":[100,120,130,111,100,128], # 数学
"english":[140,80,120,90,125,116], # 英语
"size":["S","M","L","XS","XL","L"] # 衣服大小
})
df
sort_values
DataFrame.sort_values(by,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last', # last,first;默认是last
ignore_index=False,
key=None)
参数的具体解释为:
- by:表示根据什么字段或者索引进行排序,可以是一个或多个
- axis:排序是在横轴还是纵轴,默认是纵轴axis=0
- ascending:排序结果是升序还是降序,默认是升序
-
inplace:表示排序的结果是直接在原数据上的就地修改还是生成新的DatFrame
- kind:表示使用排序的算法,快排quicksort,,归并mergesort, 堆排序heapsort,稳定排序stable ,默认是 :快排quicksort
- na_position:缺失值的位置处理,默认是最后,另一个选择是首位
- ignore_index:新生成的数据帧的索引是否重排,默认False(采用原数据的索引)
下面通过几个简单的例子来复习下sort_values的使用:
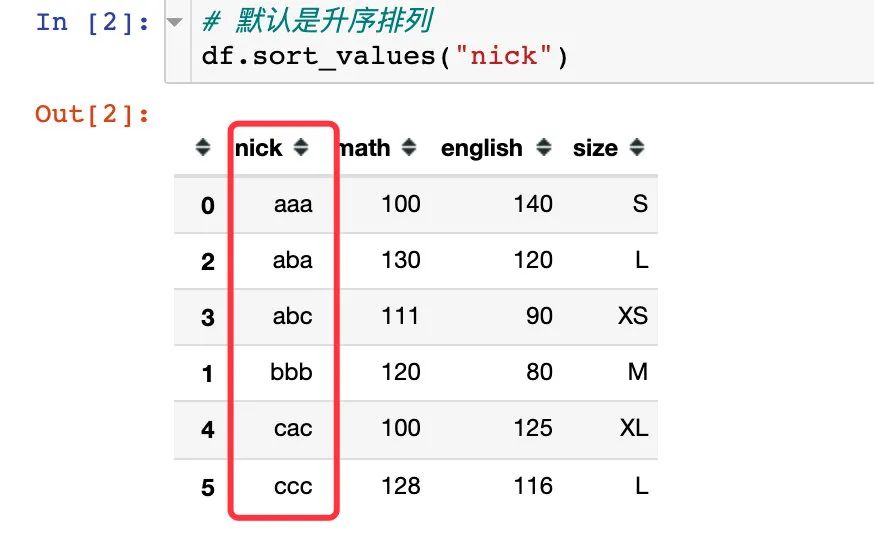
单个字段排序
通过nick字段排序,字符串是根据字母的ASCII码;默认是从小到大的升序。第一个字母相同,则比较第二个,类推:
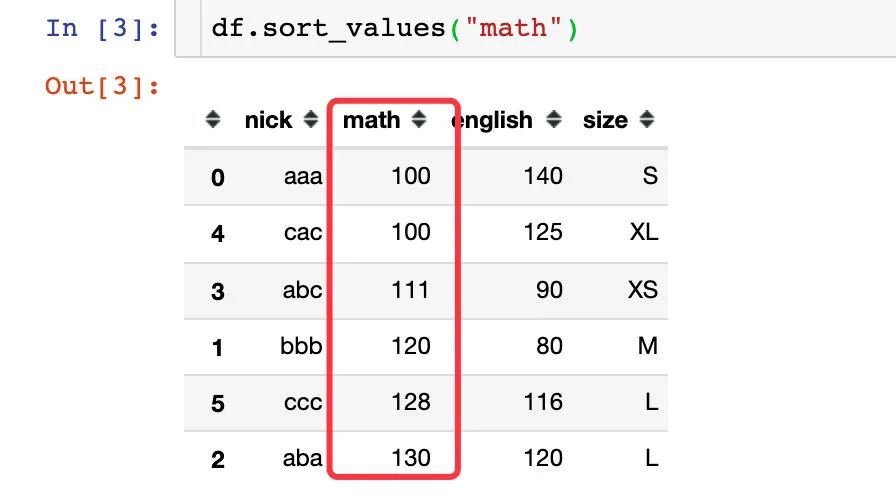
根据数值的大小来升序排列:
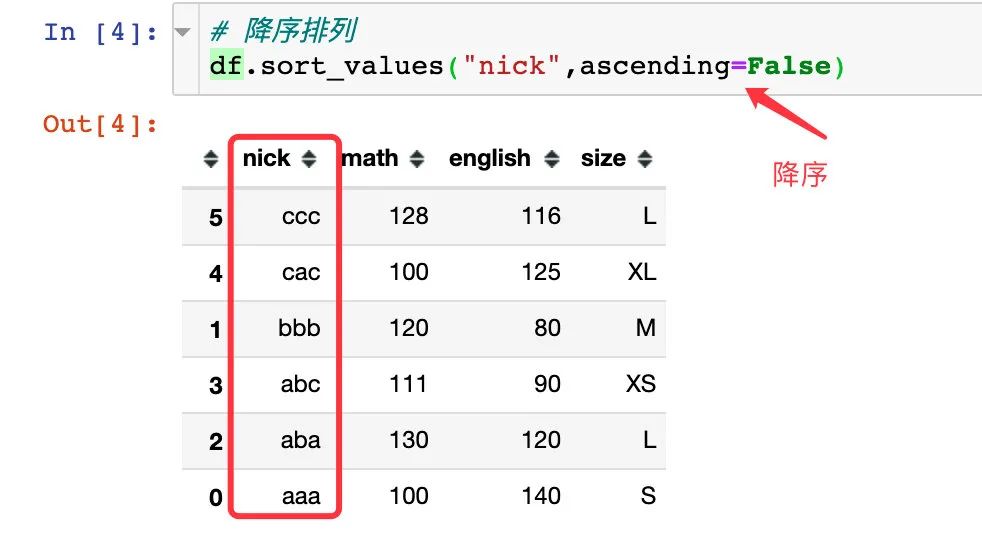
可以将排序方式改为降序:
多个字段排序
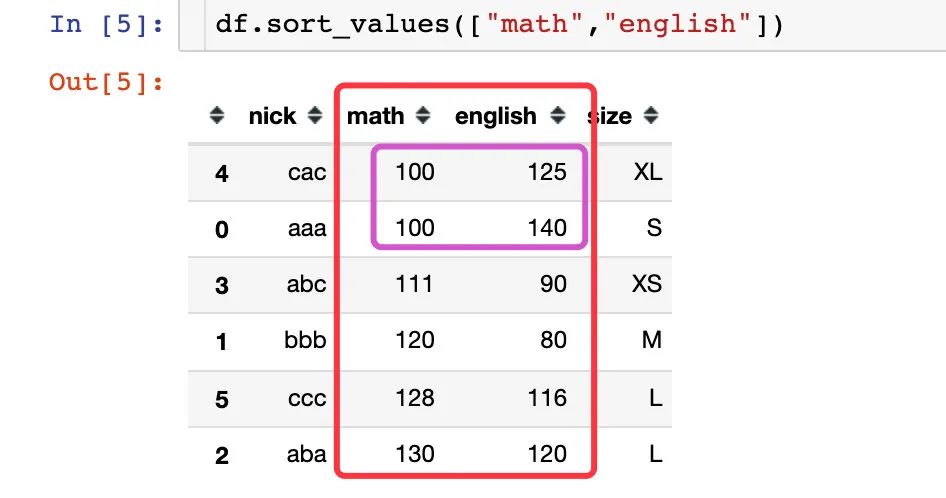
多个字段的同时排序,默认也是升序。当第一个字段的取值相同,再根据第二个字段来升序排列
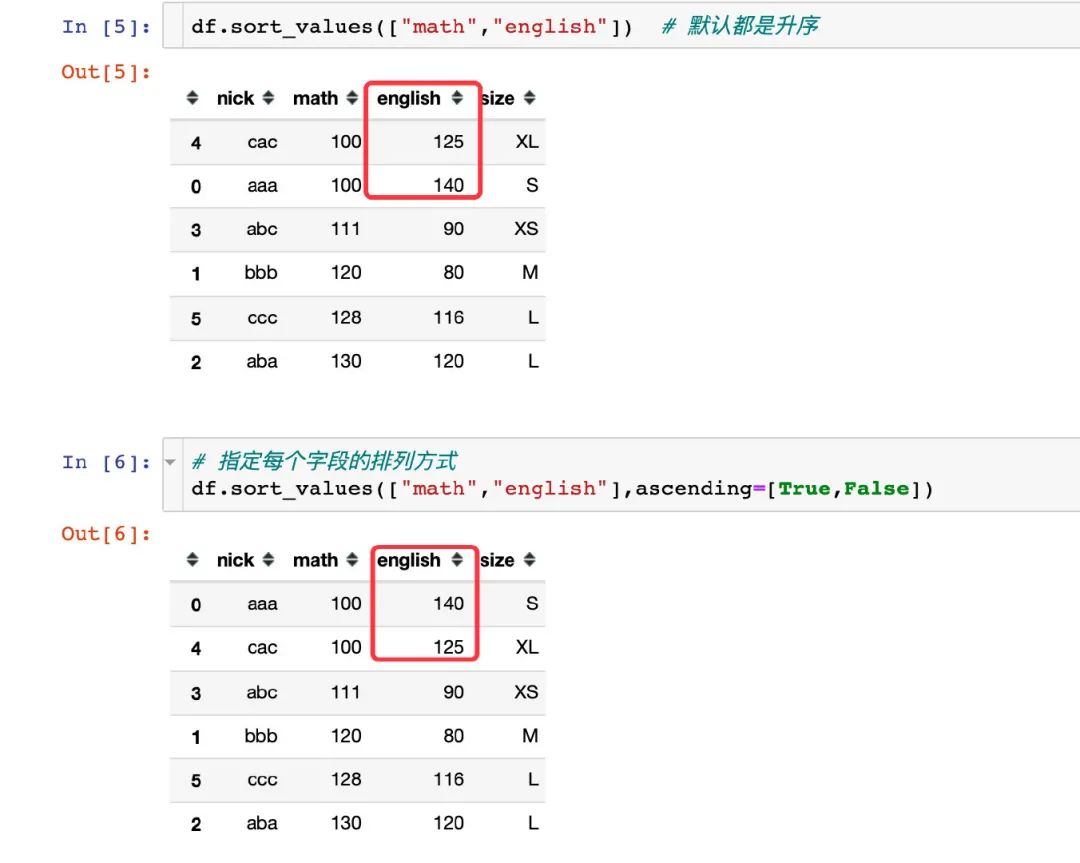
给不同的字段指定不同的排序方式:

再完整地对比下两种不同的方式:
上面的就是sort_values方法的常见排序方式。
自定义排序
使用sort_values方法排序的时候都是内置的字母或者数值型数据的大小直接来排序,当遇到下面的情况,该如何操作?
当我们根据衣服的大小size来排序,得到的结果是:
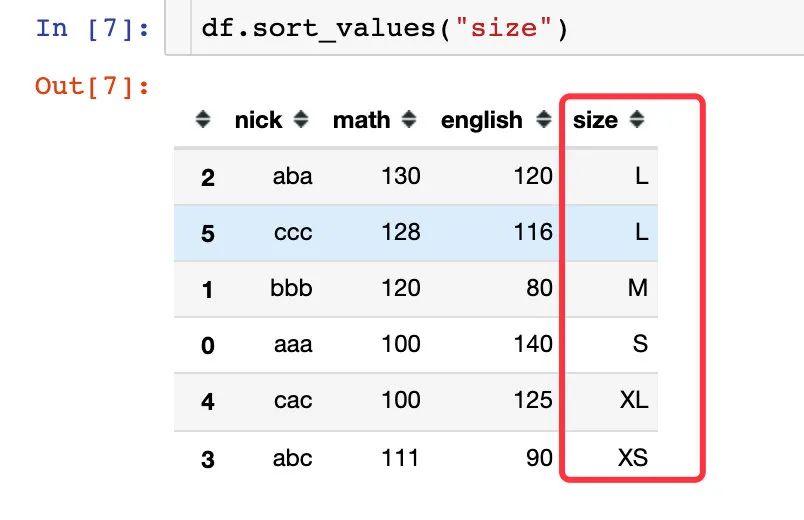
明显这样的排序方式不是我们理想中的样子,在我们的认知中:
该如何解决这个问题?提供两种方式:
方法1:通过映射
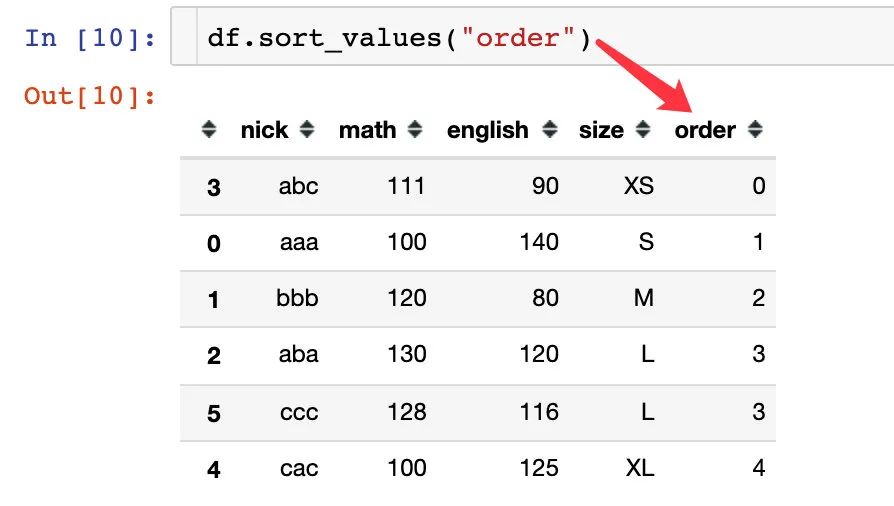
1、先找到每个size的顺序对应的数值大小
2、生成新的字段order
3、我们对order进行排序

方法2:使用CategoricalDtype
CategoricalDtype是具有类别和顺序的分类数据的类型,能够创建我们自定义的排序数据类型。官网地址:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.CategoricalDtype.html
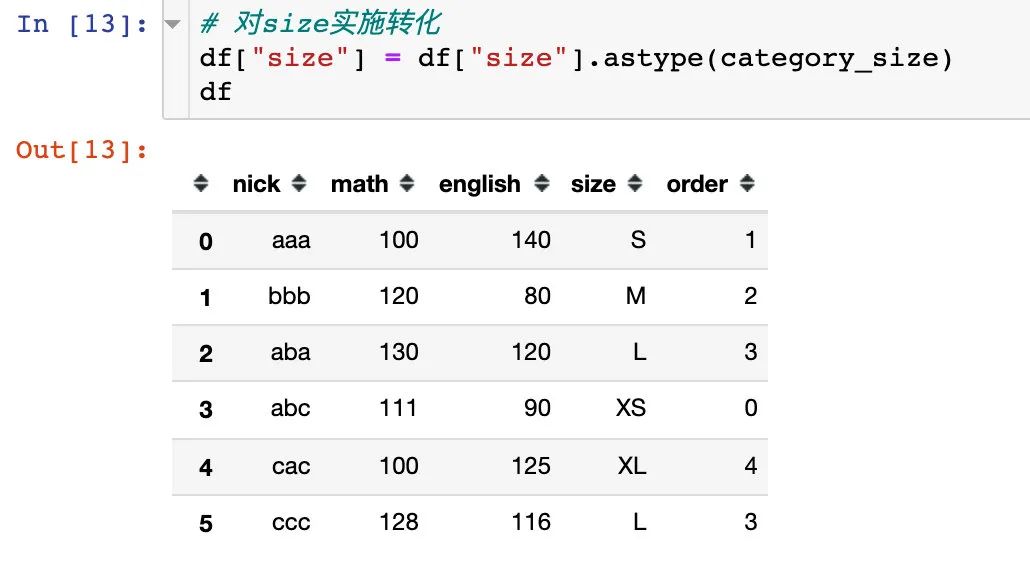
1、指定一个分类的数据类型CategoricalDtype
category_size = pd.CategoricalDtype(
['XS', 'S', 'M', 'L', 'XL'],
ordered=True)
category_size

2、将size字段设置成上面的CategoricalDtype类型
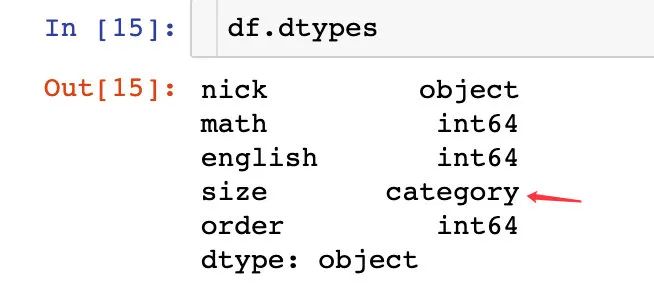
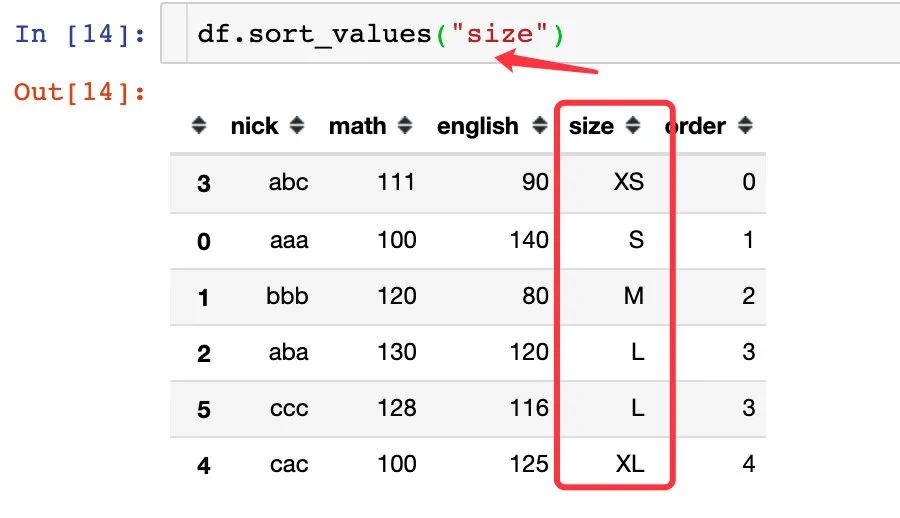
3、我们直接对size使用sort_values就可以达到我们的目的,和上面的map映射的效果是相同的
而且通过查看df的数据类型,我们也看到size的类型是category: