AI for Science领域存在大量未解NP-hard问题,其中就包括量子多体问题。编辑 | 青暮
人工智能的下一个目标是从模仿认知学习,转向解决一直存在的大规模科学计算问题,UC伯克利教授Michael Jordan曾经强调。而李国杰院士也曾在与雷峰网的交流中进一步指出,人工智能应该突破约翰·麦肯锡和艾伦·图灵定下来的框框,去研究NP-hard级别的大难题,让基础科研走向大工程化。也就是说,要用数据、算力和算法合力去寻找这类难题的具体解,并落地应用,而不仅仅追求理论边界的证明。
这些具有组合爆炸性特点的难题很早就已存在,并且有非常显式的定义,但依然由于计算难题被卡住。而人工智能特别是深度学习在层级特征建模、压缩表征等方面的优势,为解决这类问题带来了新的曙光。AlphaFold是其中的绝佳范例,再往上一层看,在整个AI for Science领域中,比如物理、化学、生物等都存在大量的未解决NP-hard问题,其中就包括了物理学中的量子多体问题。
比如,确定量子混合态是否存在纠缠就是一个NP-hard问题。k-Local Hamiltonian 问题(k-LH)至少是NP-hard问题。它们都涉及量子多体系统。
k-LH问题是指:给定k,在n个量子比特的系统中,存在一组约束,每个约束最多涉及k个量子比特,希望确定系统的基态能量是高于某个阈值或低于某个阈值。它属于一种量子多体问题,并且k不小于2时,至少是NP-hard的。当k=3或以上时,甚至出现了更高阶的复杂性类——QMA完全。
QMA类似于经典复杂性类中的NP,也就是说,如果一个问题的答案可以在量子计算机上以多项式时间验证(并且至少有2/3的概率是正确的),但无法以多项式时间给出答案,则该问题的复杂性类为QMA。同样,QMA完全也类似于NP完全。
多年以来,量子多体物理领域是凝聚态物理中最核心和最优挑战性的话题之一。比如物理世界中我们能够观测到的一些奇特物理现象和物质中,最具代表性的便是超导、超固量子Hall效应、超流、玻色-爱因斯坦凝聚和量子自旋液体等,都是基于大量粒子相互作用的量子现象。
著名的物理学家Phlips Anderson曾说,“More is Different”,这是指我们的世界并非各个物质的简单叠加,当系统中的粒子数以及元素种类增多的时候,会导致1+1>2的效果。从理论上来说就是量子多体之间的相互作用所致的结果。
由于希尔伯特空间随着粒子数增加而指数增长(组合爆炸),量子多体问题的高精度模拟是对于经典计算机极富挑战性的问题。近几年发展起来的深度学习算法为模拟量子多体提供了新的有效的计算工具。
2021年12月16日,中国科技大学物理系教授何力新在CNCC 2021“人工智能在超大规模科学计算领域的应用探索”专题论坛上做了题为《深度学习算法在新一代神威超算平台的应用:量子多体问题模拟》的学术报告,分享了深度学习算法在量子多体模拟问题上的研究工作和领域进展。
在报告中,何力新表示,他们团队设计了基于卷积神经网络的新算法,对强阻挫的强关联自旋系统实现了高精度的基态模拟。他们还在新一代神威超级计算机上移植并优化了该算法,并计算了著名的方格J1-J2模型,将计算的系统规模及计算精度提高到了新的高度。在移植、优化程序的过程中,通过物理学-并行优化-超算系统三方面交叉团队,成功在新一代神威超算上实现高性能的量子多体问题模拟,为构建国产AI-HPC生态提供一个优秀的模板示例。

何力新教授是中国科技大学物理系教授,1997年毕业于中国科技大学,2003年在美国罗格斯大学攻读博士,2003~2006年在美国国家再生能源实验室从事量子点的理论研究工作,并于2006年回国到中科大中科院量子信息中心进行研究工作,2011年获得杰青称号,2012年入选IOP Fellow,曾任科技部量子调控量子通信网络和量子仿真关键器件物理实现之首席科学家。
以下是演讲全文,AI科技评论进行了不改变原意的整理:

研究量子多体问题具有极强的科学意义,可以从两个方面进行概括。首先在基础研究的角度上来看,量子多体问题的一个主要目标是发现和研究新的物质形态。我们可能对生活中常见的固体、液体和气体形式十分熟悉,但其实自然界中有很多其他物质形态,比如我们之前所说的超导和量子自旋液体等,这些新型的物理形态都具有各自的存在意义以及研究价值。
因此通过对新型物质形态的研究,我们便可以洞悉和总结物理世界的深层规律和法则。
另一项具有意义的方向是研究其应用价值。例如高温超导已经在能源、交通、精密测量和信息等领域有了广泛的应用。托克马克装置需要非常强的磁场进行物理约束,因此可以利用超导体产生超强的磁场。此外,拓扑序也可以进行拓扑量子计算。

在量子多体物理的模型中,有两个经典模型,即海森堡自旋模型,以及哈伯德电子模型。其中海森堡模型其本质是一个自旋模型,它描述了格点上两个自旋量子的相互作用。比如图中描述了两个最近邻的两个量子发生的交换作用J,如果J>0,则两个粒子倾向于自旋反平行。但是当J<0时,粒子倾向于自旋平行。
另一个经典模型是哈伯德模型,它描述了电子运动的模型。该模型描述了量子在格点上的运动,其中第一项表示的是电子从一个格点跳跃到另一个格点的过程。第二项,描述的是同一格点上电子的库仑排斥作用。
从局部的角度来看,这两种模型很容易理解。但是当粒子数逐渐增加的时候,系统将变得十分复杂,对其求解将会变得十分困难,算力需求也难以满足。

计算困难的根本原因在于量子态的希尔伯特空间会随着粒子数量的增加而呈现指数级的增长。比如有N个1/2的自旋粒子,每个自旋有上下两个状态,那么态空间将达到2^N级别。因此如果我们需要对其进行严格求解,会遇到“指数墙”的问题,也就是算力需求巨大。目前我们只能实现大约40个格点的自旋系统的严格求解。
此外,我们也有一些其它近似方法,例如量子蒙特卡洛方法。但是它在计算费米系统(电子系统)和阻挫系统时会出现符号问题,即负几率问题。而动力学平均场方法,会对一维和二维等低维度的模型有计算问题。最后是密度矩阵重整化方法,只能计算一维和准一维的问题。
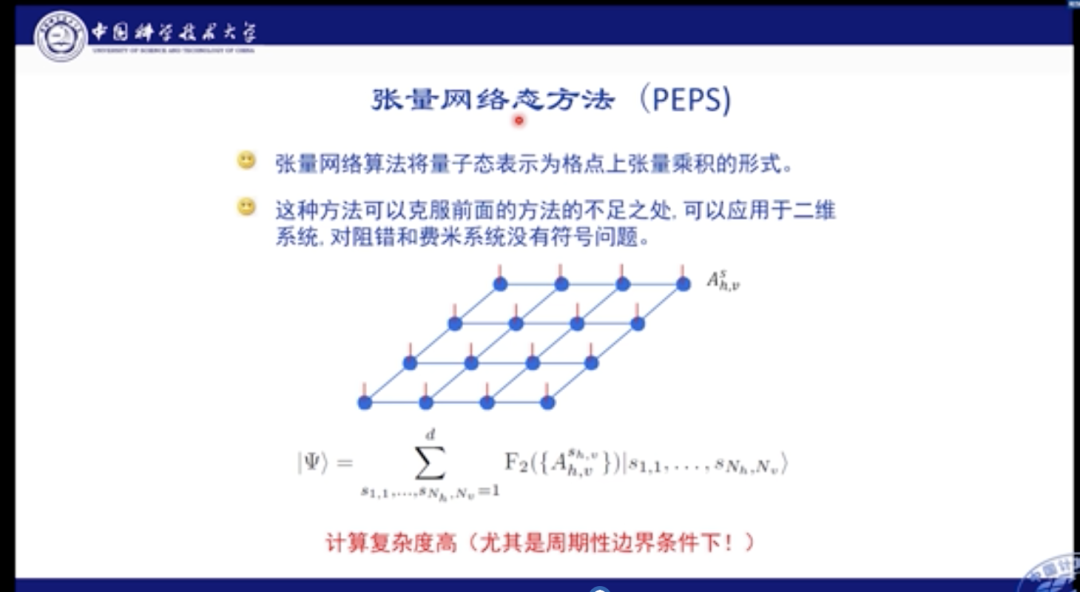
在过去的十几年间,国际上发展了一些新的算法,例如张量网络态方法(PEPS算法)。这些算法将量子态表示为格点上的张量乘积形式。原则上这种方法可以在一定程度上克服已有方法的不足,它可以应用于二维系统,也不存在对阻挫系统和费米系统中的符号问题。
但是另一方面,它的计算复杂度很高,尤其是对周期性边界条件的问题。因此我们目前无法对具有周期性边界条件的系统进行有效的模拟。
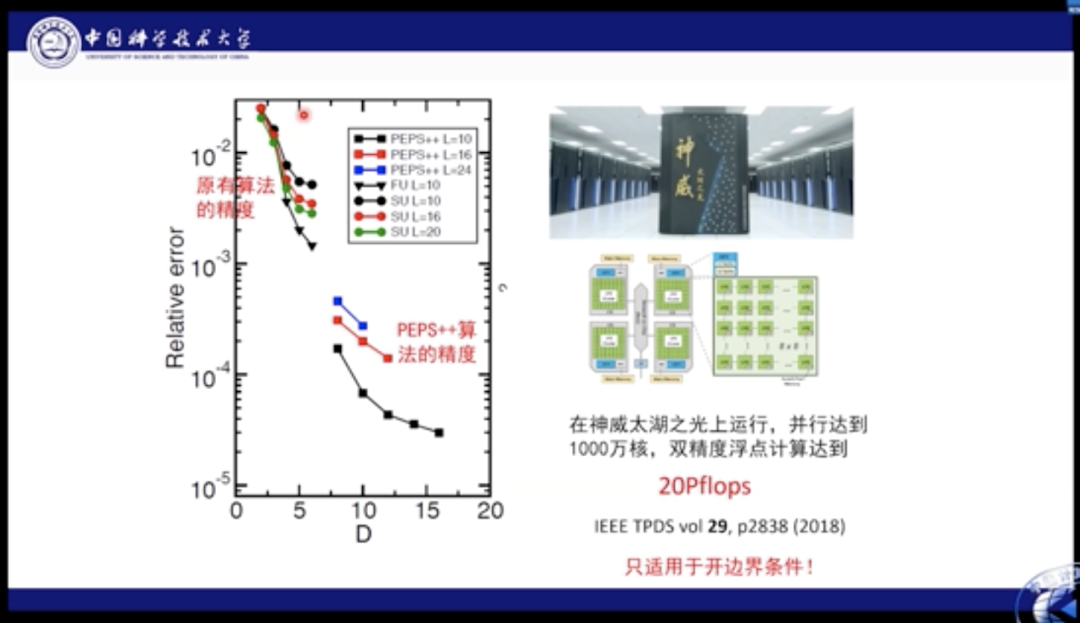
在2018年,我们曾经在神威机器上进行了PEPS算法的实现和模拟。当时可以将算法的并行度做到1000万核。我们可以看到之前工作的算法精度仅能达到10-3,但是神威机上的PEPS算法则将精度是提高了2个量级。但是这个算法仍旧仅适用于开放边界条件的问题。
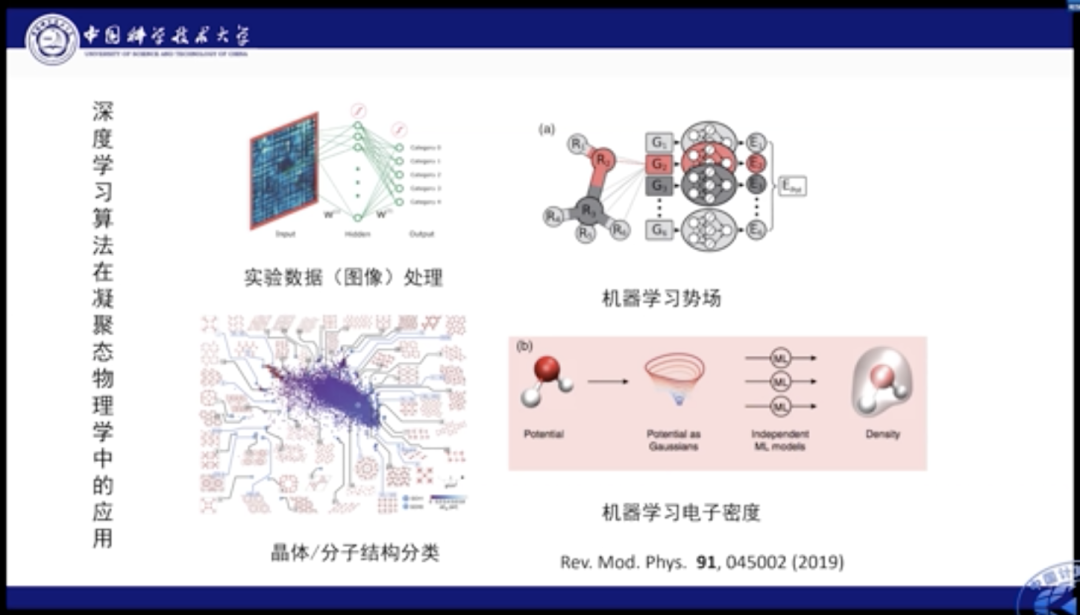
我们知道在AlphaGo在击败人类围棋玩家之后,深度学习大热,引起了很多领域的改革。实际上,深度学习在凝聚态物理学中也掀起了一番热烈讨论和尝试。它可以做实验数据的处理,可以进行机器学习势场模型的模拟和求解,也有工作研究了用AI进行分子和晶体结构的分类和预测,进行电子密度的学习等。近些年DeepMind的最新工作就是在这些方面进行研究和发现,比如使用神经网络估计电荷的密度,并且超越了人类的估计结果。
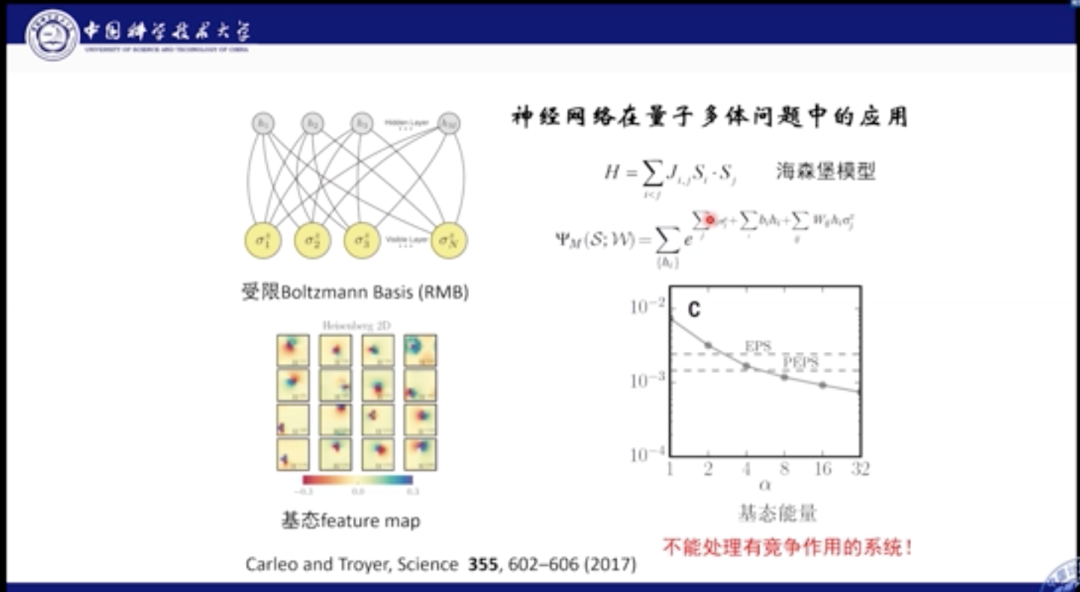
大家也在尝试将深度学习和机器学习用在量子多体问题中。上图是2017年的一篇Science工作,它使用受限玻尔兹曼机模型研究海森堡自旋模型,将系统的粒子波函数利用玻尔兹曼机进行表示和学习,通过优化系统的能量,得到神经网络的最佳参数。
在量子多体系统中,算法的好坏判断标准是计算的能量是否最优。从结果中我们看到,该计算能量的精度已经到达10-3量级,甚至超过了(我们神威工作)之前PEPS的算法效果。
但是该神经网络也面临一些问题,它只能描述简单的物理模型,无法模拟具有竞争相互作用的物理系统。
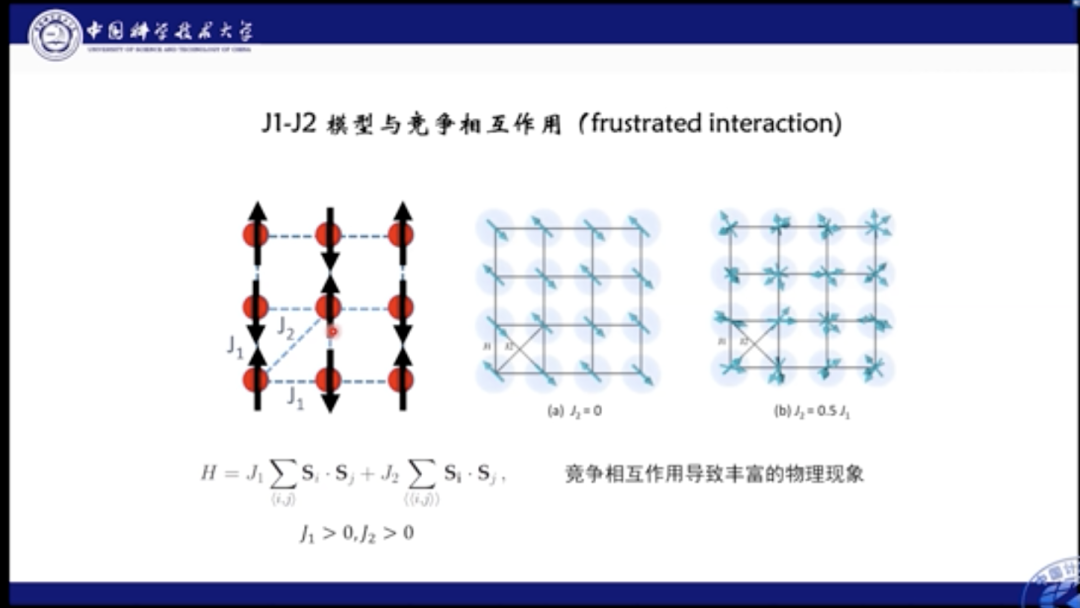
那么什么是相互竞争作用呢?我们结合这里的模型进行解释。J1-J2模型是一个典型的具有竞争相互作用的自旋模型。我们看到图中每个格点上有一个自旋,它们与近邻的自旋有相互作用,其中J1描述两个最近临的格点上的自旋相互作用,J2则描述了两个次近邻格点上自旋的相互作用,也就是对角线上的相互作用。如果相互作用的J大于0,则意味着这两个格点的自旋都倾向反平行。当J1, J2 都大于0时就会出现问题,即如果近邻格点是反平行,那么次近邻格点就一定是平行的,这就和J2相互作用的要求矛盾。该种带有竞争相互作用的系统被称为阻挫系统。
打个比方,一个员工可能有两个老板,其中一个老板要求你向东走,另一个要求向西走。则此时会产生矛盾(Frustrated Interaction)。当然,如果其中一个老板很强势,我们跟着强势的走。但是如果两个老板势均力敌,你就会很迷茫。
对J1-J2模型也是如此,如果J1较为强势,那么系统中的自旋会倾向于做出棋盘形状的持续排列。如果J2更强势,自旋则会沿对角线进行反平行排列。当两者相互作用效果相近时,则会产生更多丰富的物理现象。
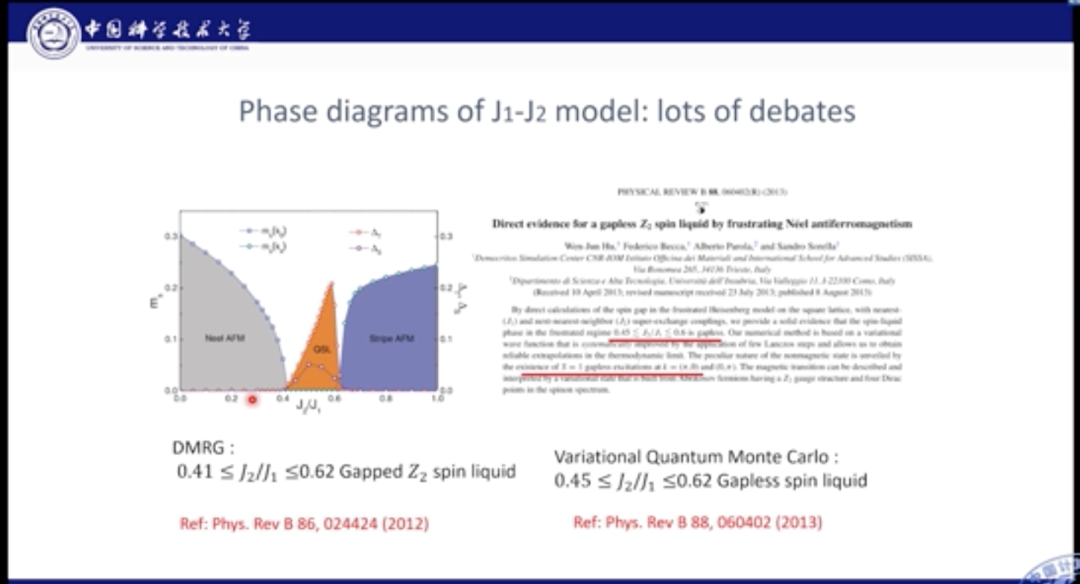
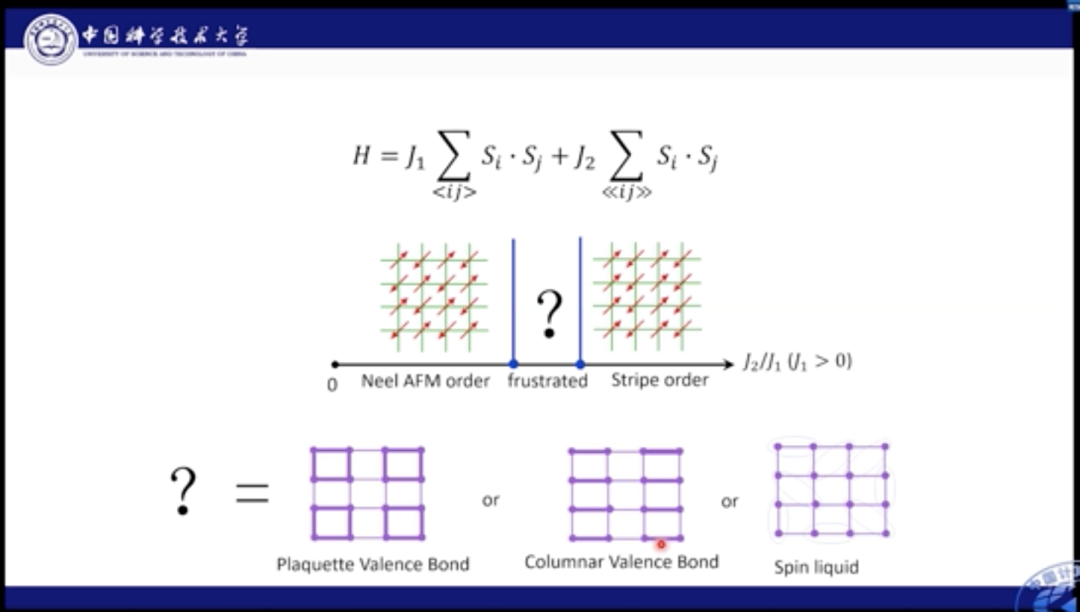
J1-J2模型十分经典,人们对其基态进行了长期的研究。目前针对J1较强,以及J2较强的情况研究已经较为清晰的结论,但是对于J1-J2共同作用的中间区域,一直存在争议。
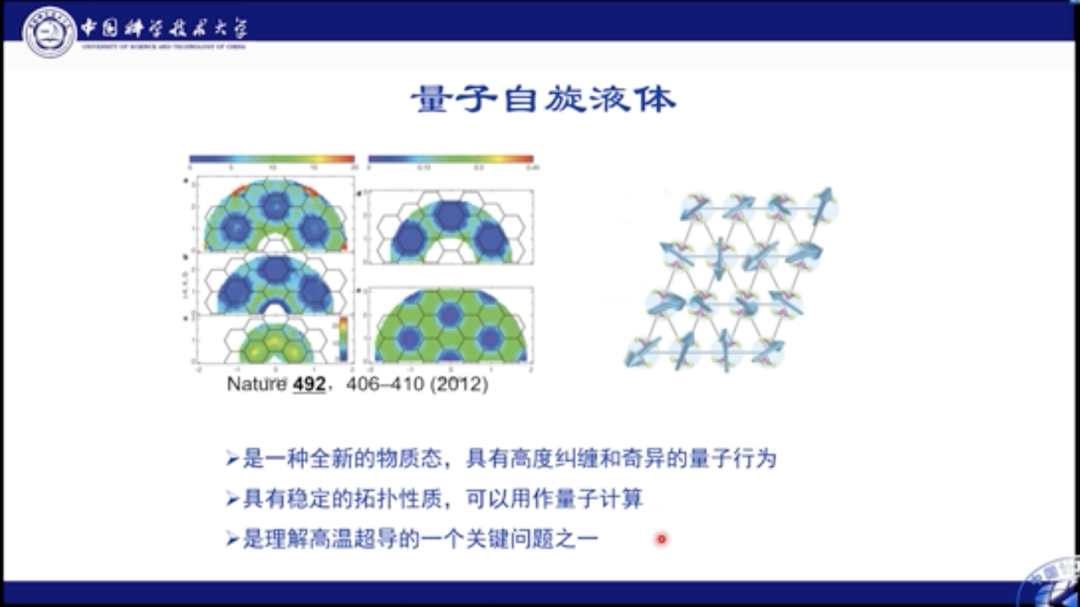
对于该区域的基态,人们有几种不同的看法。比如,有人认为格点可以形成Plaguette态,Plaguette态是一个规则有序的态;此外,也可能会形成Columnar态;也有人提出,可能其中就是一种混乱无序的状态,即自旋液体态。自旋液体态十分复杂,有着非常复杂的量子纠缠和奇异量子行为。Philip Anderson认为量子自旋液体是研究高温超导的关键问题之一。
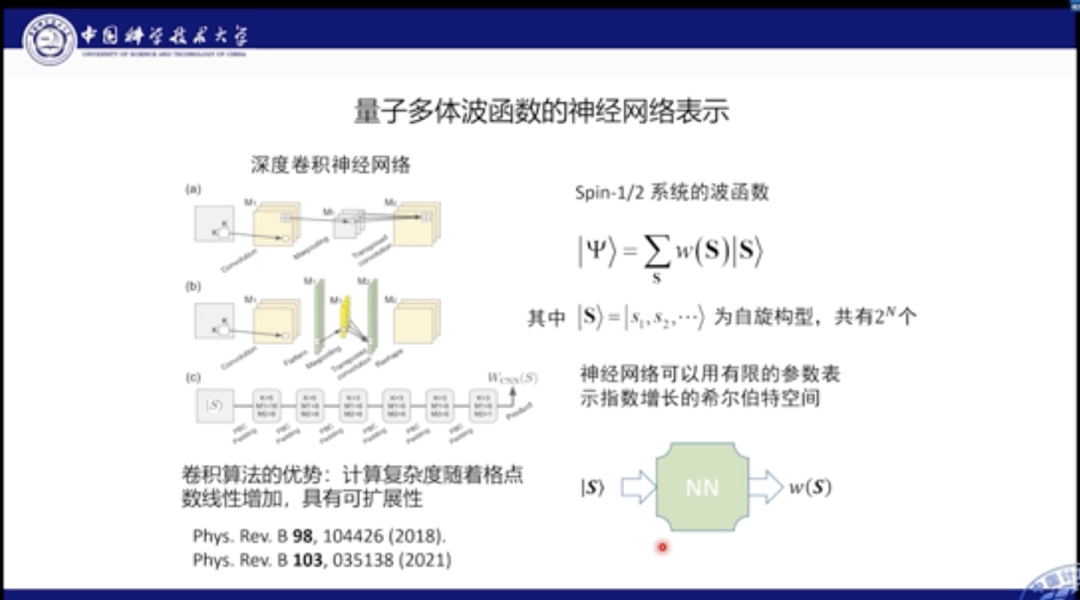
之前的玻尔兹曼机模型是无法很好地模拟该场景的。在该方法中,它将波函数视作所有可能自旋结构的叠加,其中W(S)就是自旋构型的权重,该权重在海森堡模型中都是>0的,但是在有竞争的模型中正负都有可能。因此在玻尔兹曼机模型中,就无法处理此类同时具有正负情况的波函数。
为此,我们提出使用深度卷积神经网络来描述波函数。我们的网络包括了很多Building Block,每个Block又分为多种算子,包括卷积、Max pooling和反卷积等。
当我们输入一个自旋构型,该网络可以给出有正有负的构型权重,此时的参数量是随格点数量线性增长,而非灾难的指数形增长,这就意味着我们的神经网络可以使用有限扩增的参数量来模拟出系统中指数增长的Hilbert空间。当然这个空间也是仅在基态附近的部分。

当我们确定了神经网络的结构来模拟波函数后,重要的是需要获得系统的基态,所谓基态是指系统的能量最低态。也就是我们需要通过神经网络求解系统能量最低态的参数。
这里的能量可以表示成所有自旋构型加权求和的形式,因此可以使用马尔可夫抽样的方式进行求解。这是一个典型的强化学习场景,我们可以通过优化系统能量来得到网络参数。
但是这个模型和一般的机器学习算法有所差异。第一,它需要极高的精度,我们需要比其他方法要求高至少2个量级的精度。其原因是量子态的求解精度需求极高,微小的误差将对基态解产生巨大影响。此外,系统中可能存在多个局部最优点,若我们用普通方法进行优化,则可能陷入局域极值中。
为了解决这个问题,我们使用SR方法进行解决。在机器学习中我们常称之为自然梯度法。为了更新网络参数,我们需要求解能量对参数的多个梯度,为了计算梯度相,我们需要进行求导,并求解关联矩阵的预处理,加速收敛。

这里的计算热点包括马尔可夫采样。因为我们需要计算关联矩阵,需要50万sweep的自旋样本,每个sweep都需要对所有网格进行翻转。但是在sweep之间是不需要进行求导和反向传播的,我们只需要正向执行,并在全部sweep做完后进行反向传播,以此降低通讯时间占比,以及计算量。
另一个计算热点是SR优化方法。在SR算法中一个重要步骤是计算大的关联矩阵,然后求解线性方程组。具体哪部分的耗时是最严重的,其实是由模型参数大小所决定的。如果系统越大,采样越耗时,参数越多,SR方法的耗时越大。
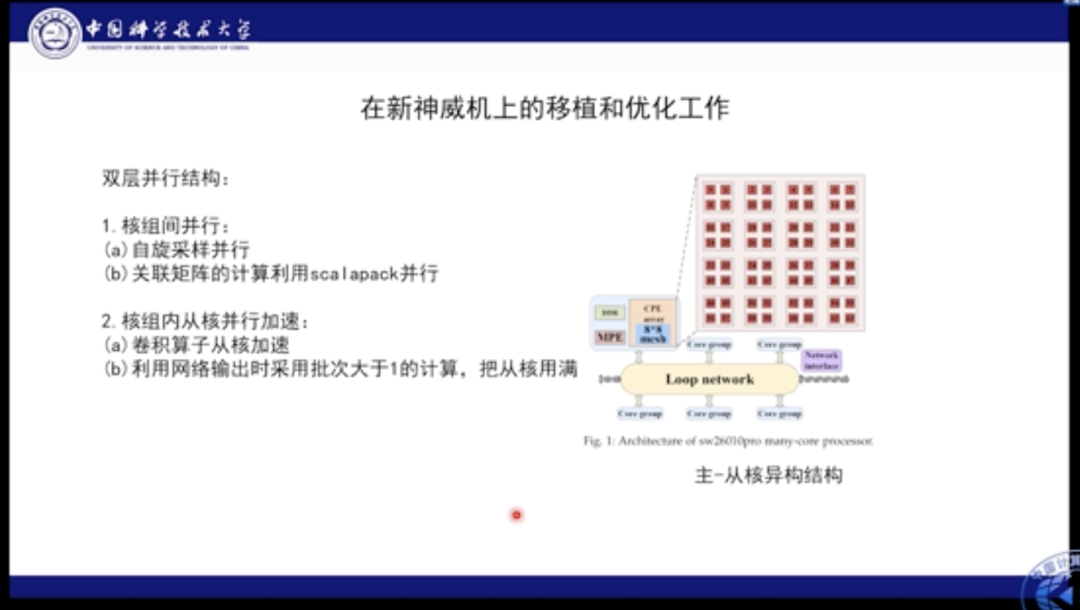
我们分别在自己的机器以及新一代的神威机上进行了验证和部署。神威机具有异构的结构,其NPI处于核组之间,因此有64个组合。在核组级别上的并行本质是线程并行。神威机的异构结构很适合此类应用,因此为了最大化利用神威机的能力,我们针对神威机的特点和应用特点设计了双层并行方案。首先在核组之间的并行被用作自旋采样,即每个自旋部署在不同的核组之上进行独立采样。在求解线性方程组的时候,会使用ScaLAPACK进行计算划分。在并行内部,我们使用卷积算子从核加速,并利用网络输出时采用批次>1的计算,将从核的计算性能妥善利用。
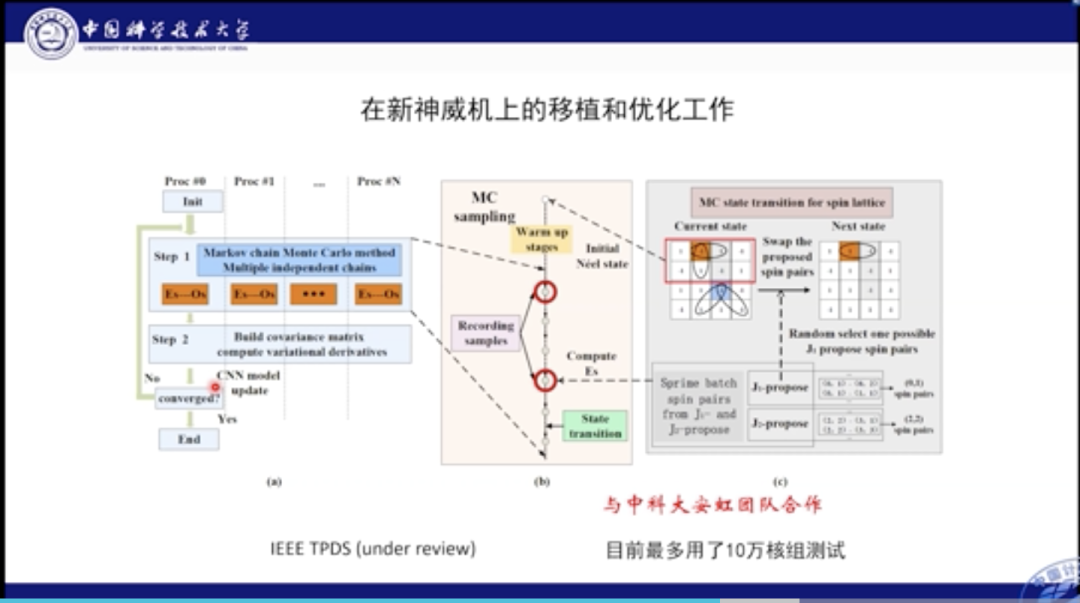
这是我们的程序在新的神威机上的移植和优化的示意图全览。可以看到在不同的核组之间我们进行了单独独立的采样;采样后将其收集并计算关联矩阵,并求导更新参数。这项工作最大利用了10万核组测试。
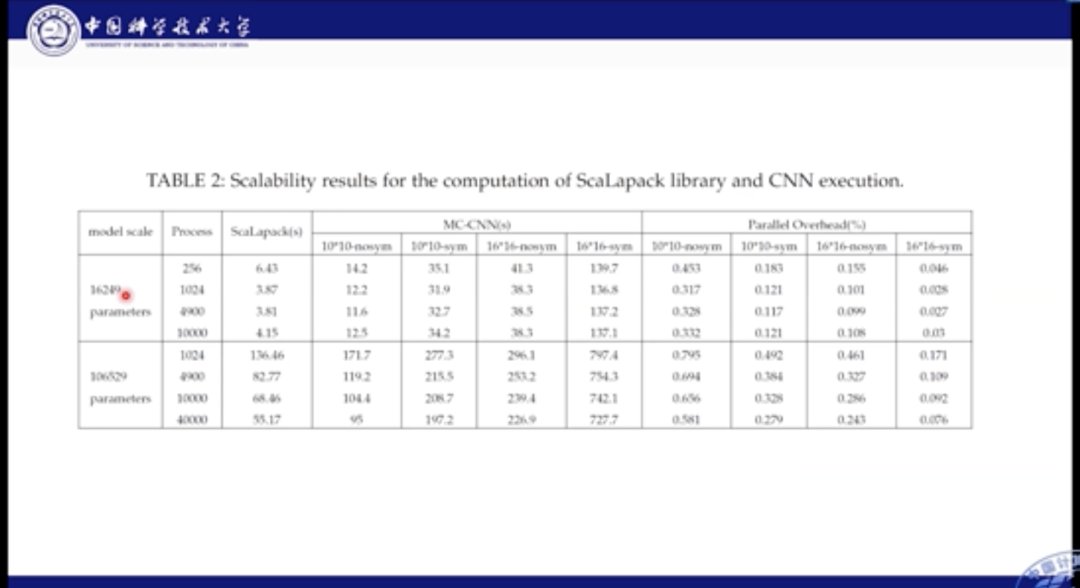
在性能表现方面,我们对比各个主机的用时结果。从上图中我们可以看到,我们分别比较了16000个参数,和10万个参数的场景。不论参数量如何,其主要的计算时间还是集中在前向计算部分,SR优化的占比只有1/4左右。
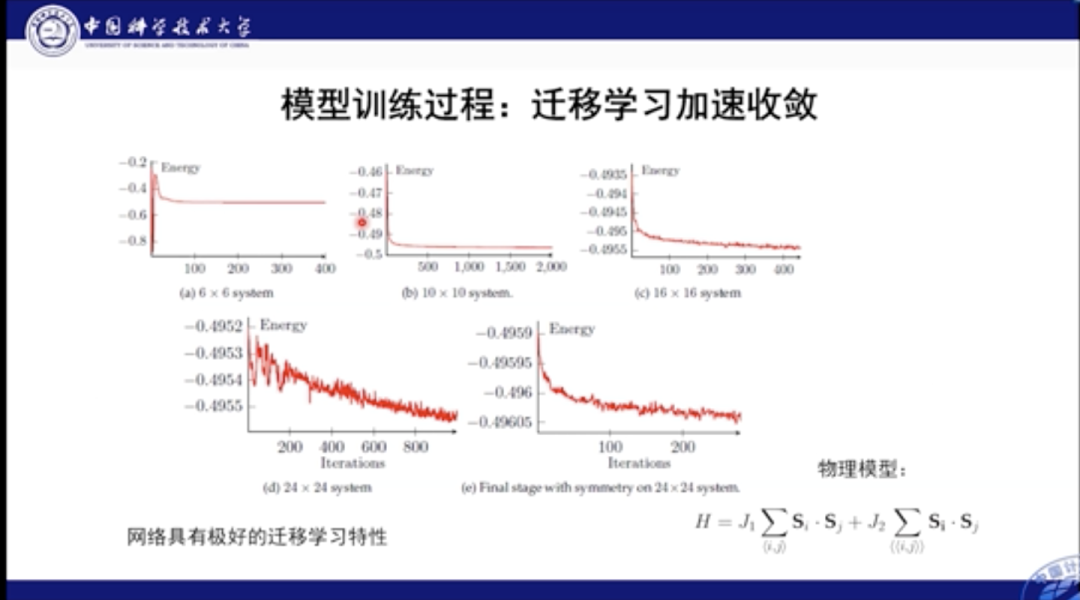
本工作的另一个优点在于其可迁移性极高。我们首先可以在较小的神经网络中进行学习,而后将其扩展到体积大的网络中。在实践中,迁移后通常只需要几百步便可以使大网络收敛,这无疑加速了模型的训练和应用。
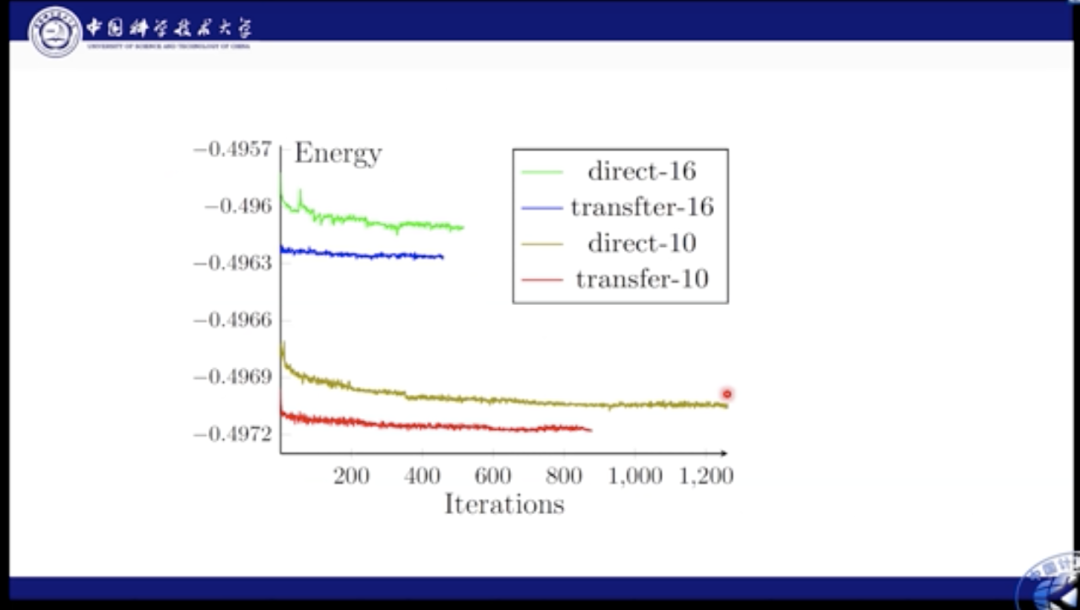
这里我们对比了性能。绿色和棕色线都是直接学习的结果,蓝色和红色是迁移的结果。通过图中结果我们知道,如果使用直接学习,则网络很难收敛到最佳结果,而迁移则极大加快了这个最优化的过程。
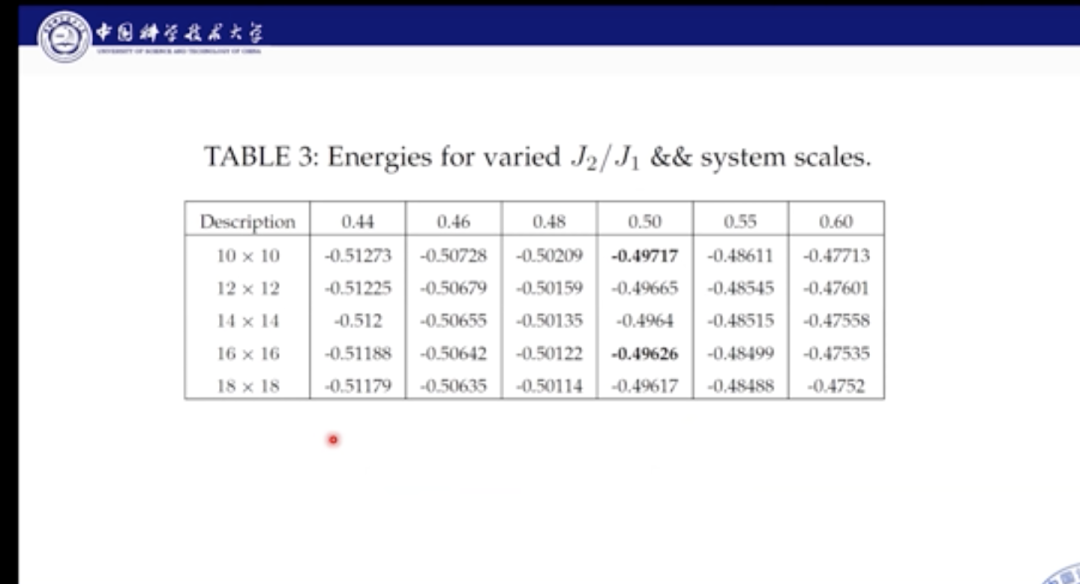
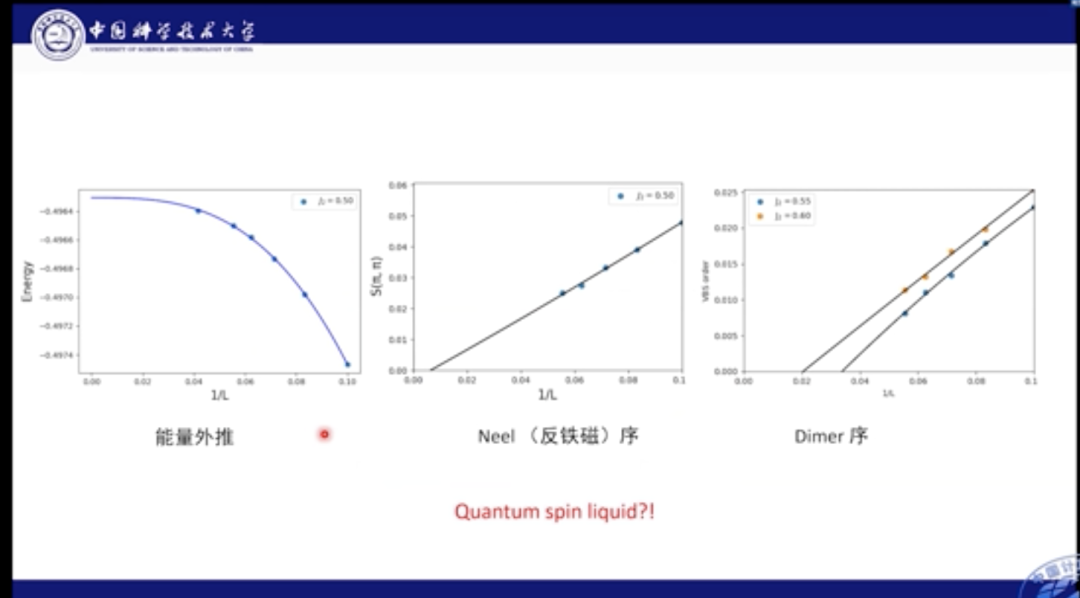
我们也分析了基态能量部分的外推结果,经过计算发现,能量在网格达到24×24后便逐渐收敛,我们也对多种磁序进行外推,比如Dimer序和反铁磁序。结果发现,系统在中间区域的基态是自旋液体相。
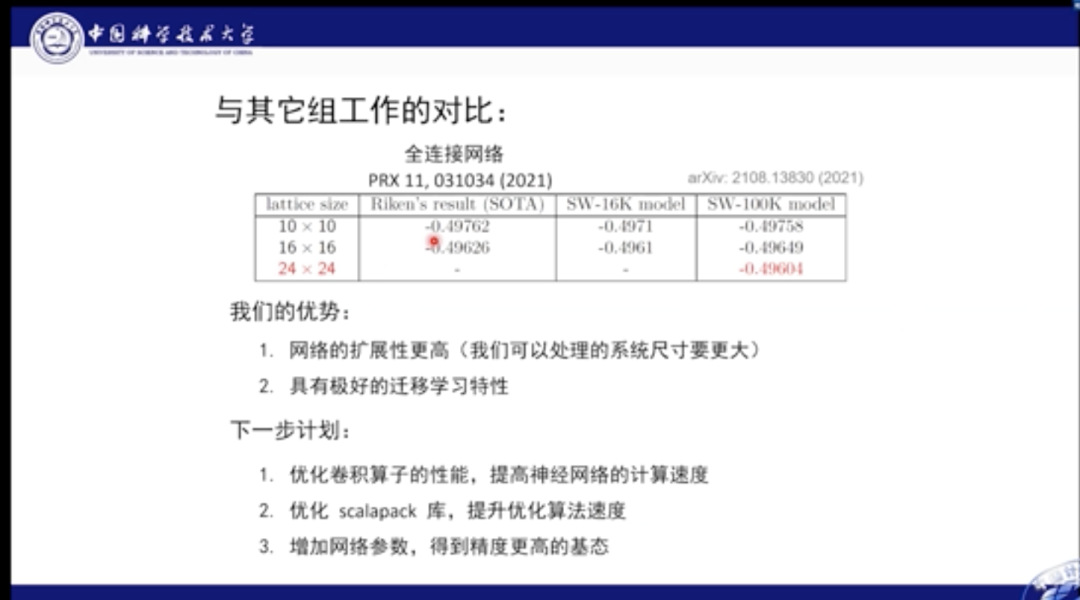
与之前的最佳结果对比,我们的优势在于,网络的扩展性更高,也就是可以处理的系统尺寸更大,具有极好的迁移学习特征。
在下一步工作中,我们将继续进行相关研究,主要优化卷积算子的性能,提高神经网络的计算速度;优化ScaLAPACK库,提升优化算法的速度;增加网络参数,得到精度更高的基态。
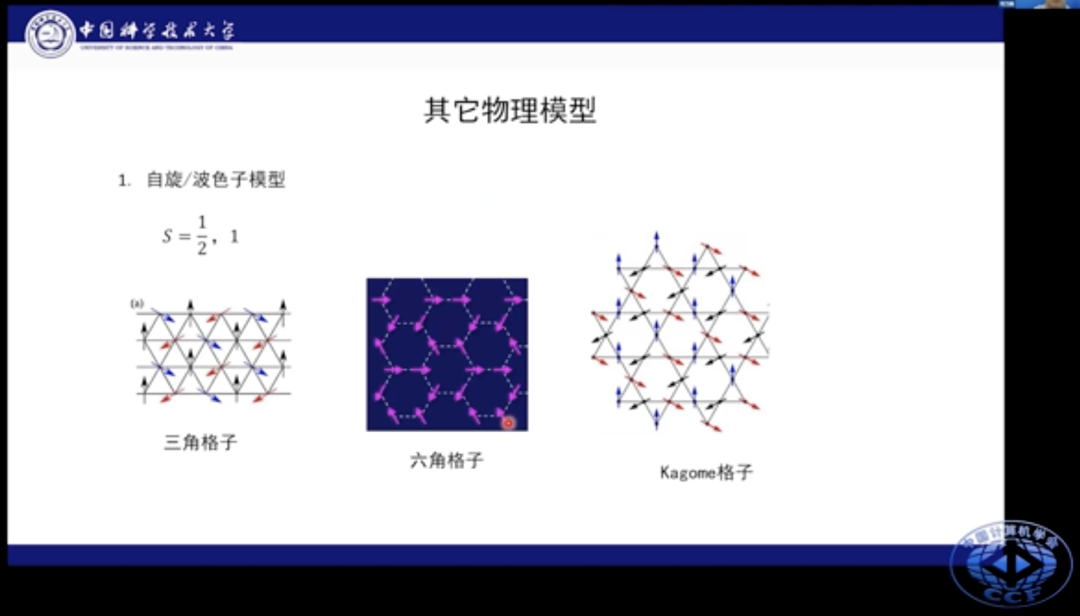
该模型可以进一步拓展到其他种类模型上,比如三角格子、六角格子和kagome格子等场景。我们还可以在近邻、次近邻作用的基础上添加次次近邻的相互作用。这些物理模型都有其特殊物理现象。

该模型还能用在费米子(电子)模型比如t-J模型上,我们初步的测试目前来看效果很好。
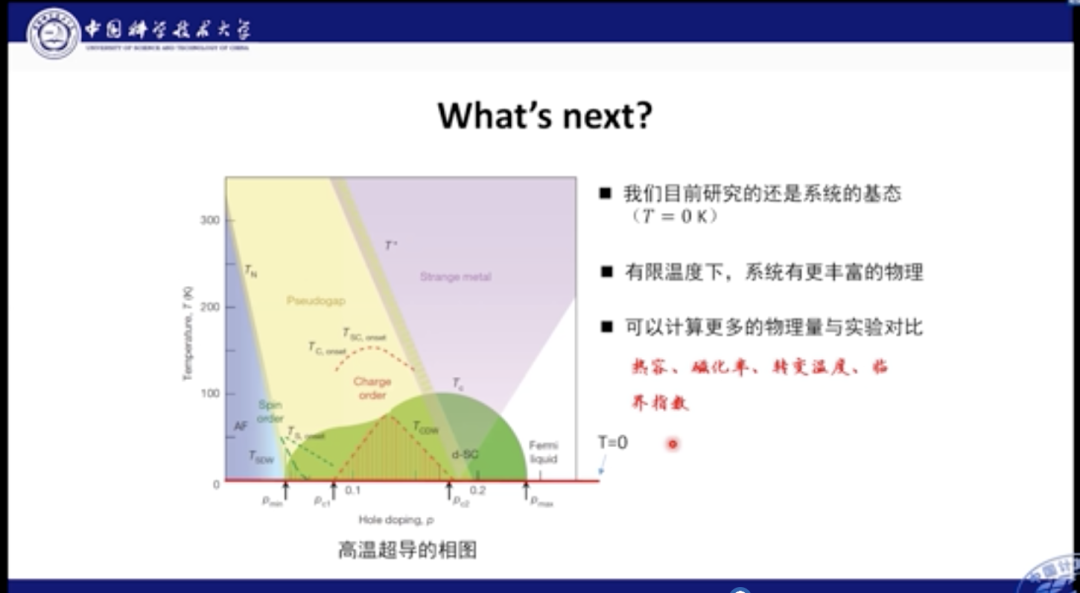
但是当前我们的研究还是限于系统的基态,即T=0K的场景。而真正有限温度下的系统,可能存在更丰富的物理系统属性,可以计算更多的物理量和实验进行对比。

有限温度的研究是个极大挑战。因为绝对零度场景下系统处于基态,因此可以使用波函数进行描述。但是当温度不等于零时,系统处于混态,就必须使用密度矩阵进行描述。此时样本空间将会成倍的增加,因此需要更多的网络参数,甚至到达100万左右的级别。








