
不久前,剑桥高级机器学习讲师 Ferenc Huszár 在个人博客上力荐斯坦福马腾宇与 Percy Liang 团队的工作《将上下文学习视作隐式贝叶斯推理的阐释》(被 ICLR 2022 接收),称其改变了他“对上下文学习以及将语言模型训练成小样本学习工具的思考方式”。对一项工作的深入思考与精彩点评,同样是科学进步的源泉。同行切磋,堪比华山论剑。为此,AI科技评论将马腾宇团队的新作进行简单介绍,并整理了 Ferenc Huszár 的评论笔记,希望对该领域的研究者有所启发。作者 | 丛末
根据 Ferenc Huszár 的介绍,他是在 ICLR 审稿期间阅读到马腾宇等人的这篇工作,觉得该论文所取得的成果十分引人入胜,并进行了深入思考。
ICLR 2022 在去年11月公布初审结果,马腾宇团队有3篇工作入选,《将上下文学习视作隐式贝叶斯推理的阐释》(An Explanation of In-Context Learning as Implicit Bayesian Inference)便是其中之一。
作者:Sang Michael Xie, Aditi Raghunathan, Percy Liang,马腾宇
论文地址:https://arxiv.org/pdf/2111.02080.pdf马腾宇与Percy Liang分别为斯坦福大学计算机系的助理教授与副教授,是人工智能领域的著名新秀,都曾获得斯隆研究奖,其研究工作受到同行关注。
图注:马腾宇
如AI科技评论此前对马腾宇的专访介绍,马腾宇主要从事人工智能基础理论的研究工作,课题覆盖非凸优化、深度学习及理论等等。这篇被 ICLR 2022 接收的工作也是从理论出发,研究上下文学习/语境学习(In-Context Learning)与隐式贝叶斯推理之间的关系。
当前,GPT-3等大规模预训练语言模型进行上下文学习的表现惊人:模型只需基于由输入—输出示例组成的提示进行训练,学习完成下游任务。在没有明确经过这种预训练的情况下,语言模型会在正向传播过程中学习这些示例,而不会基于“分布外”提示更新参数。
但研究者尚不清楚是什么机制让上下文学习得以实现。
在这篇论文中,马腾宇等人研究了在预训练文本具有远程连贯性的数学设置下,预训练分布对上下文学习的实现所起到的作用。在该研究中,对语言模型进行预训练需要从条件文本中推断出潜在的文档级别概念,以生成有连贯性的下一个标记。在测试时,该机制通过推断提示示例之间共享的潜在概念,并应用该概念对测试示例进行预测,从而实现上下文学习。
他们证明了:当预训练分布是混合隐马尔可夫模型时,上下文学习是通过对潜在概念进行贝叶斯推理隐式地产生的。即便提示和预训练数据之间的分布不匹配,这种情况依旧成立。
与自然语言中用于上下文学习的混乱的大规模预训练数据集不同,他们生成了一系列小规模合成数据集(GINC),在这个过程中,Transformer 和 LSTM 语言模型都使用了上下文学习。除了聚焦预训练分布效果的理论之外,他们还实证发现,当预训练损失相同时,缩放模型的大小能够提高上下文(预测)的准确性。
Ferenc Huszár 是剑桥大学计算机系的高级机器学习讲师,对贝叶斯机器学习有深入的研究。2016年与2017年,他在基于深度学习的图像超分辨率与压缩技术上取得两大突破(如下),谷歌学术引用了超过1万4。
Photo-realistic single image super-resolution using a generative adversarial network(谷歌学术引用7.5k+)
Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network(3.5k+)
图注:Ferenc Huszár
Ferenc Huszár 对马腾宇等人的工作给予了高度评价。AI科技评论对 Ferenc 的点评做了不改原意的整理:
我喜欢这篇论文,因为它与可交换性(exchangeability)相关,这是我最喜欢的概念和想法之一。它让我想起了我在2015年(当时还处于深度学习的发展早期)的想法——利用可交换序列模型实现大规模通用学习机。在那篇旧博文中,我对可交换模型做了如下思考:
如果我们有一个可交换的循环神经网络(RNN),我们就可以在同一输入空间的多个无监督学习问题上对它进行训练。这个系统其实就学会了学习。如果想在一个新的数据集上使用该系统,只需将它输入到循环神经网络中,它就能够输出贝叶斯预测概率,无需任何额外的计算。所以,它就是一个终极通用推理机。实际上,终极通用推理机(很庆幸我给它注册了商标)跟 OpenAI 的 GPT-3 有时给人呈现的样子和使用的方式并没有太大区别。实践显示,使用者可以在多种多样的任务中将它们重新调整为小样本(或在某些情况下为零样本)学习工具。语言模型的这种通过输入精心设计的提示来解决不同任务的能力,有时候被称为“提示黑客”(prompt-hacking)或“上下文学习”。
老实说,在我读到马腾宇等人发表的这篇论文之前,我从来没有把大型可交换序列模型视作通用学习工具的动机和使用GPT-3进行上下文学习的最新趋势联系起来。事实上,我对后者深表怀疑,认为它本质上就是必然存在根本缺陷的另一种黑客行为。但是这篇论文将这些点都联系起来了,这也是它为什么如此吸引我的原因,因为我永远无法想到“提示黑客行为”和上下文学习竟然完全一样。
1)将可交换序列作为隐式学习机
在探讨这篇论文前,让我们先来温习下关于可交换序列和隐式学习的已有概念。
可交换序列模型是一个序列概率分布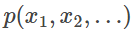 ,在序列
,在序列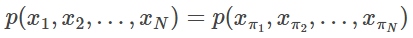 中,对于任意一个置换 π,该分布都是对标记的置换不变量。
中,对于任意一个置换 π,该分布都是对标记的置换不变量。
de Finetti 定理将这些序列模型与贝叶斯推理联系在一起,假设任意分布都可以分解成混合独立同分布(I.I.D.)序列模型:
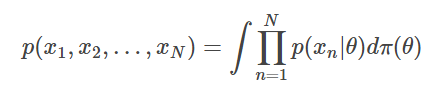
因此,前一步的预测分布(用来预测序列的下一个标记)总能分解成贝叶斯积分:
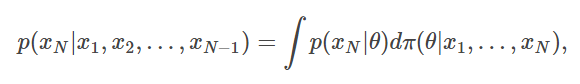
其中,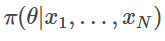 是由先验
是由先验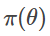 计算得到的贝叶斯后验,计算的贝叶斯公式为:
计算得到的贝叶斯后验,计算的贝叶斯公式为:
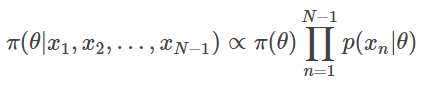
在这种情况下,如果我们有一个可交换序列模型,就可以将这些前一步的预测分布视作隐式执行的贝叶斯推理。关键是,即便我们并不知道θ个 π 是什么,以及可能性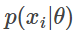 是什么,也能实现这一操作。我们不必明确指出公式的这些组成部分是什么,de Finetti 定理都能够确保这些组成部分都存在,而只需要让预测
是什么,也能实现这一操作。我们不必明确指出公式的这些组成部分是什么,de Finetti 定理都能够确保这些组成部分都存在,而只需要让预测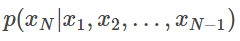 与可交换序列模型保持一致。
与可交换序列模型保持一致。
这一想法驱使我通过构建这一模型,来尝试设计总是能够产生可变换分布的循环神经网络(当时Transformer 还没有出现)。最终证明这种想法很难实现,不过这一想法最后衍生出了 BRUNO(名字取自Bruno de Finetti)这一工作。

论文地址:https://arxiv.org/pdf/1802.07535.pdf
BRUNO 是一个用于可交换数据的灵活的元训练模型,拥有小样本概念学习能力。这个想法后来在 Ira Korshunova 的博士论文中得到多种方式的拓展。
2)从可交换序列到混合隐马尔可夫模型(HMM)
但GPT-3是一个语言模型,很明显语言标记是不可交换的,所以两者联系是什么?
伴随着de Finetti 型定理出现了一些引人关注的泛化成果,可交换性的概念也出现了一些有趣的扩展。Diaconis、Freedman(1980)等人定义,偏导可交换性(Partial exchangeability),指的是能确保序列可被分别为混合马尔可夫链的序列分布的不变属性。因此,可以说,使用偏导可交换过程对马尔可夫链进行贝叶斯推理,与使用可交换过程对独立同分布(I.I.D.)数据生成过程进行推理的方式非常相似。
马腾宇等人在这篇论文中,假设使用的序列模型是混合隐马尔可夫模型。这比 Diaconis 和Freedman 提出的偏导可交换混合马尔可夫链更具泛化性。
我不知道是否混合隐马尔可夫模型能用可交换性此类的不变性来表征,但这不打紧。实际上这篇论文根本没有提及可交换性,其关于隐式贝叶斯推理的核心论点是:每当使用由简单分布组成的序列模型时,可以将前一步的预测阐释为“对一些参数隐式地进行贝叶斯推理”。虽然互联网上人类语言的分布不太可能遵循多观察隐马尔可夫模型(Multi Observation Hidden Markov Model,MoHMM)分布,但假设GPT-3输出的序列可能是混合隐马尔可夫模型的某些部分,这种说法就是合理的。并且如果真是这样,预测下一个标记就会对一些参数(作者所指的“概念”)隐式地进行贝叶斯推理。
3)上下文学习和隐式贝叶斯推理
这篇论文的核心思想是,也许上下文推理能够利用这种与语言统计模型密切相关的隐式贝叶斯推理来解决问题。语言模型能够学习隐式地对任何概念进行概率推理,因为要想在预测下一个标记的任务上表现得好,就必须进行这种推理。如果模型具备这种隐式学习能力,那它就能够操纵这种能力去执行其他同样需要这种推理的任务,包括小样本分类等等。
我认为这是一个非常有意思的泛化想法。但令我稍感遗憾的是,作者聚焦的关键问题是特定性和人为性:虽然多观察隐马尔可夫模型可以用来“补全”从某个特定的隐马尔可夫模型(混合组成部分的其中一个)中提取的序列,但如果让多观察隐马尔可夫模型补全它们根本无法直接生成的序列,例如一个人为构建的嵌入了小样本分类任务的序列,会发生什么?这就变成了一个分布不匹配的问题。
论文关键的发现在于,即便这种分布不匹配,多观察隐马尔可夫模型中的隐式推理机制也能够识别正确的概念,并且能在小样本任务中使用这种分布来做出正确的预测。
这一分析为嵌入序列中的上下文学习任务与多观察隐马尔可夫模型分布的相关性,做出了强有力的假设(具体细节请阅读原论文)。从某种程度上来说,作者研究的上下文任务,与其说是一个分类任务,不如说是一个小样本序列补全任务。
总而言之,这是一篇值得思考的、有意思的论文,它显著地改变了我对整个上下文学习以及将语言模型训练成小样本学习工具的研究方向的思考方式。
大家怎么看?
参考链接:
1.https://www.inference.vc/implicit-bayesian-inference-in-sequence-models/
2.https://www.inference.vc/exchangeable-processes-via-neural-networks/









