
图1 本方法单独地或联立地支持来自图像和文本域的条件输入以完成头发编辑
本文介绍我们在CVPR 2022关于基于文本和参考图像完成头发编辑的工作。该工作将文本和参考图像条件统一在了一个框架内,在单个模型内支持广泛的图像和文本作为输入条件从而完成相应的头发编辑任务。代码正在逐步开源,欢迎大家试用。

论文标题: HairCLIP: Design Your Hair by Text and Reference Image
作者单位: 中国科学技术大学,微软云AI,香港城市大学
录用信息: CVPR 2022
代码: https://github.com/wty-ustc/HairCLIP
论文: https://arxiv.org/abs/2112.05142
一、针对问题
1. 当前头发编辑交互方式不够友好
头发作为人脸至关重要的组成部分,一直以来得到了学术界与工业界的广泛关注。近年来,随着深度学习的发展,许多基于条件生成对抗网络(GAN)的头发编辑方法可以产生不错的编辑效果。但是,这些方法大多使用精心绘制的草图或遮罩作为图像到图像翻译网络的输入从而得到编辑后的结果。然而这种交互方式并不直接也不够友好。因此,这样的交互方式极大地限制了这些方法的大规模自动化使用。
2. StyleCLIP为文本驱动的图像编辑提供了前车之鉴,但其存在诸多不适于高强度“做头发”的缺点
得益于跨模态视觉和语言表征的发展,基于文本指导的图像篡改方法已经开始不断出现。最近,StyleCLIP通过结合StyleGAN强大的图像合成能力和CLIP惊人的图像文本表征能力展现了很好的图像篡改效果。尽管StyleCLIP内在地支持基于文本描述的头发编辑,但是它存在如下缺点:
对于每个特定的头发编辑描述,它都需要分别训练一个映射器,这种方式在实际应用中是非常不灵活的;
由于缺少定制的网络结构和训练损失函数设计使得该方法对于发型、发色和其他无关属性的解耦性比较差;
在实际应用中,一些发型发色是很难用文本描述的。这时,用户更倾向于使用参考图像,但是StyleCLIP不支持基于参考图像的头发编辑。
二、方法框架
本文利用在大规模人脸数据集上预训练的StyleGAN作为我们的生成器,整个头发编辑框架如图2所示。给定待编辑的真实图像,我们首先使用StyleGAN inversion方法得到其隐编码,然后我们的头发映射器根据隐编码和条件输入(发型条件、发色条件)预测隐编码相应的变化,最后修改后的隐编码将被送入StyleGAN产生对应的头发编辑后的图像。因此,最核心的问题就是学习一个映射器网络来将输入的条件解耦地映射到隐编码的相应变化。我们从网络结构、损失函数两个方面来解决这个问题。
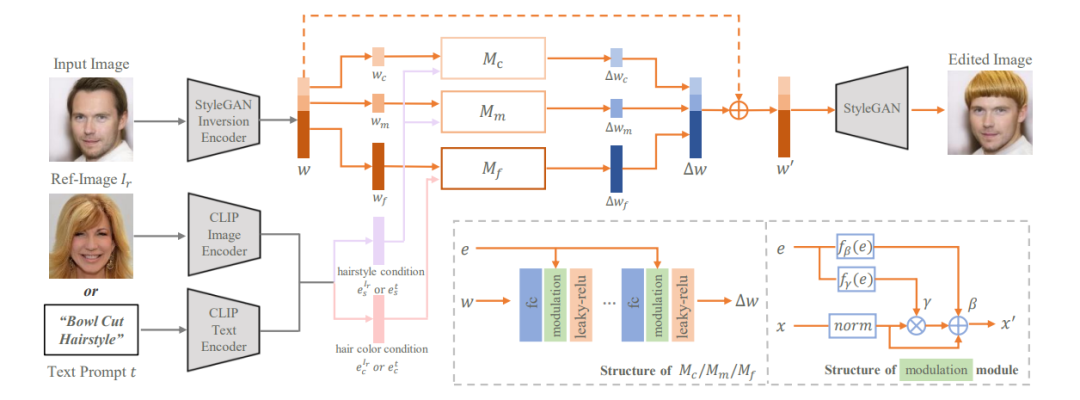
图2 本文提出的跨模态头发编辑框架的概述图
1. 网络结构
共享的条件嵌入。为了将文本和图像条件统一在同一个域内,本文利用CLIP的文本编码器和图像编码器来分别提取它们各自的嵌入,用以作为本文映射器网络的条件输入。因为CLIP是在大规模图像-文本对上训练过的,所以不管是文本嵌入还是参考图像嵌入都在同一个共享的隐空间中,因此它们可以被不加区分地送入映射器网络并且任意切换。
解耦的信息注射。因为StyleGAN存在语义分层现象,即StyleGAN中不同的层对应的语义级别不同。我们注意到了这点,在头发映射器内细分了三个子头发映射器,对应预测高、中、低语义级别的隐编码变化。同时,我们显式地分离了发型信息和发色信息,并根据它们在StyleGAN中对应的语义级别将它们分别喂入不同的子头发映射器中,这种做法提升了网络对于发型、发色编辑的解耦能力。
调制模块。本文设计了一个条件调制模块来完成输入条件对隐编码的直接控制。整个调制模块结构(见图2)非常简单,设计思想借鉴于一些经典的条件图像翻译工作,这种做法提高了本文的头发篡改能力。
2. 损失函数
文本篡改损失,用于约束编辑后的结果与给定文本描述之间的相似性。不管是发型还是发色我们都是在CLIP的隐空间中度量文本与编辑后结果的余弦相似度。这也是目前CLIP被使用最多的方式,平平无奇。
图像篡改损失,用于指导从参考图像到目标图像的发型或发色转移。对于发型转移,我们面临一个挑战:如何比较好的度量发型之间的相似度?这儿, 我们再次发挥了CLIP的强大本领,将编辑后的图像与参考图像的头发区域均经过CLIP的图像编码器嵌入到CLIP的隐空间中进而度量它们间的余弦相似性。得益于我们提出的该训练损失,我们的方法对待编辑图像与参考图像存在严重不对齐的情况,也可产生合理的编辑结果。对于发色转移,我们度量编辑后的图像与参考图像头发区域的平均颜色差异。
属性保持损失,用于保持无关属性(如:身份、背景等)在编辑前后不变。
三、实验结果
与相关工作的定性对比见图3、图4。我们的方法高质量地完成了相应的头发编辑任务。

图3 与StyleCLIP、TediGAN就基于文本描述的头发篡改的定性对比

图4 与LOHO、MichiGAN就基于参考图像的头发篡改的定性对比
四、应用展示
1. 头发内插
在获得两个完成头发编辑的隐编码后,我们可以通过将两个隐编码进行线性加权的方式完成细粒度的头发编辑。

图5 头发内插结果展示
2. 泛化能力
得益于我们提出的共享条件嵌入策略,我们的网络在有限的文本训练后拥有了一定的外推能力,它可以对训练过程中未出现过的一些文本产生合理的编辑结果。

图6 对未见过的文本描述的泛化性
3. 支持跨模态的条件输入
我们的模型支持来自图像域和参考图像域的条件以单独地或联合地形式作为网络的输入,这是目前其他头发编辑方法无法做到的。

图7 跨模态条件输入结果展示
五、总结
本工作第一次证明了CLIP在头发编辑领域的巨大潜力:不是单一地利用CLIP衡量图像文本相似度,本工作利用CLIP的强大的共享隐空间完成了对图像域和文本域的统一与协作促进,探索了CLIP的图像编码器对难以表征的事物提供一种相似性度量的手段。虽然本工作聚焦于头发编辑,但希望它可以对其他相关领域给予一些启发与思考。

-
- 机器学习交流qq群955171419,加入微信群请扫码:










